Taming your shell for LLMs - rand[om]
I recently got frustrated with Codex’s command permissions. They don’t let you configure which commands should always be allowed or denied. There’s an issue about it, but it’s …| rand[om]
I recently got frustrated with Codex’s command permissions. They don’t let you configure which commands should always be allowed or denied. There’s an issue about it, but it’s …| rand[om]

Creating new files is safer and simpler. The Problem with Appending Appending to files causes problems: Multiple threads writing to the same file requires locks Other processes might append to the …| rand[om]
This post shows how to run some Ansible playbook tasks in parallel. The approach requires tags for all tasks you want to run in parallel. How It Works The script runs multiple Ansible tasks simultaneously by: Defining a list of tags to run in parallel Using a ThreadPoolExecutor to create a thread for each tag Running the Ansible playbook (as a subprocess) with a specific tag in each thread The example code (below) assumes the playbook files are part of the Python package, and uses importlib.r...| Home on rand[om]
I stopped using shell aliases and moved everything into executable scripts. Main Benefits No need to source your .bashrc after adding new scripts No need to edit .bashrc, just drop executable files in your ~/bins folder (already in my $PATH) Use immediately without reloading your shell Faster iteration (edit script, re-run command, repeat). Available in more places: Executable scripts in your PATH can be used inside other scripts, sub-shells, find -exec, xargs -I{}, and other environments whe...| Home on rand[om]
I have been using the Cursor IDE for some time already and I really like its documentation indexing feature. Recently, I discovered a better way to leverage Cursor’s tools to make better …| rand[om]
At some point in the past, I created a tool for a project (not relevant for this post). This tool generated multiple artefacts from an input (embeddings file, JSON metadata, and other files). The …| rand[om]
Some time ago, I found (and used for a while) the htl library. Before that, I was using raw template literals to build HTML, and then setting some element.innerHTML = newString. htl uses template literals, but instead returns a regular DOM Node object. This makes it a lot easier to add even listeners, setting other properties, and overall manipulating the object before appending it to the current document. I was curious to see how it was done, and it turns out it’s easier than I thought. Th...| Home on rand[om]
I was recently reading the source code of mizu.js1 and I liked the utility “function”2 they have to handle keyboard shortcuts/combinations. I decided to slightly modify it to have it as …| rand[om]
How to query a list of Python dictionaries using DuckDB, without previously converting to another format. We can pass the list of dictionaries to the query directly and use unnest to convert to a list of rows. We can also expand the struct to multiple columns. Note: all the dictionaries must have the same keys. # /// script# requires-python = ">=3.12"# dependencies = ["duckdb"]# ///importduckdbDATA=[{"foo":1,"bar":"some string","baz":1.23},{"foo":2,"bar":"some other string","baz":2.34},{"foo"...| Home on rand[om]
When you have a web application, almost always, you need to run some functions/scripts regularly. This what cron is for. I wanted to find an easy way to run “cron-like” jobs inside a FastAPI app. The app runs inside docker, and I just need those jobs to run as long as the app is also running. Since the app is “async”, I found I can just have recurring background tasks as part of the app. We need to use the app lifespan and some functions that run a task, the asyncio.sleep for a pre-de...| Home on rand[om]
Lately, I’ve been trying to learn more JavaScript. I wanted to explore web components. After checking out some frameworks and tools, mainly lit, tonic and facet, I wanted to build my own thing. It ended up being heavily inspired by tonic, but way simpler and with less features. I also really liked lit-html, which you can use as a separate package without having to use lit. It solves the problem of re-rendering only the UI parts that have changed, and it’s awesome at doing it.| Home on rand[om]
I recently read a post from vercel about porting turborepo to rust. In that post, they mention calling a go binary from the rust code instead of having to deal with FFI and C type compatibility. I wrote a post called “Use a subprocess instead of a dependency”, which follows a similar philosophy, although applied to something different. Here are some extra notes related to the vercel post. As an example, I’ll use a Python app that wants to call some Rust code, but the idea could apply to...| Home on rand[om]
I recently learned 1 a nice pattern to improve parameter handling in shell scripts. The pattern involves parameter expansion: #!/usr/bin/env bash set -euo pipefail function main {localarg1="${A1:?'FAIL. Provide A1 var'}"echo$arg1}main When calling the script (called t.sh throughout this post), it will fail: bash t.sh # t.sh: line 7: A1: FAIL. Provide A1 var But this will succeed: A1=foo bash t.sh # foo It can also be used to provide default/required positional arguments.| Home on rand[om]
Before you read I found out the code here doesn’t work outside IPython, I didn’t realize that get_ipython() only works when running inside IPython. But the examples here work in isolated scripts if you run the script using ipython: ipython benchmarh.py. Introduction I like using IPython to measure the execution time of Python functions. You can also time functions using the timeit module, but the IPython utilities are just more convenient, and I install IPython in almost all my virtual en...| Home on rand[om]
As part of my recent experiments with mmap1 I have learned how to share data between processes using a memory-mapped file. Here I’ll show how to do it between two independent Python processes, but the same principles apply to any programming language. Create a file to store the data I will use the tempfile module so that the file gets deleted after the script finishes. I prefer using this when learning or testing new things, otherwise my folders end up filled with random files. You can also...| Home on rand[om]
Here are some benchmarks I ran to compare the speed of running a list of regexes on all the Markdown files in my Obsidian folder (210 when I wrote this). The benchmark compares running the regexes on memory-mapped files versus loading the file contents as a string and running the regexes on that string. I’m using hyperfine to run the benchmarks. Considerations When we memory-map a file, we work with bytes. Python can run regexes over those bytes too, but the pattern has to be .encode()‘ed...| Home on rand[om]
After trying a few note-taking apps, I ended up using Apple Notes. It was super fast on macOS and iOS. This was more or less my thinking: The syncing was good and it worked offline. But it had a couple of drawbacks. The format is not open. There are some scripts to reverse-engineer the Apple Notes SQLite database1, but that still needs a computer with iCloud sync, otherwise you can’t get the Notes.app SQLite database on your disk.| Home on rand[om]
This blog started as a place to share new things I learned about programming. I initially wrote Jupyter notebooks that I converted to Markdown. Then I started writing Markdown directly. After some time, I felt like having to open my text editor in my laptop to write a blog post was making me write less. It also felt like I had to write something longer than a tweet. That’s how I started using Apple Notes a lot more1. Some notes were long, others were shorter than a Tweet. I’ve been enjoyi...| Home on rand[om]
Intro I was exploring different ways I could use Apple Notes as a CMS (Content Management System). I found out that you can add a Google account to sync some notes, but those notes are synced using the IMAP protocol to a folder in the email account. This post explains how to use the Gmail API to retrieve those notes. The idea for the CMS is: Write notes in Apple Notes, avoid using tables and drawings (there may be other elements that are not compatible with this method) Add a new Google accou...| Home on rand[om]
I was recently reading the documentation of nnethercote/counts, in there, Nicholas explains a few pain points when using a table as a profiling output. But using SQLite as the “table” can relieve some of those pains. I frequently use SQLite for debugging and I wanted to share some techniques that have been helpful (and relate them to some arguments mentioned in nnethercore/counts) Defining the table and exposing it to multiple modules These 2 points are not a problem with SQLite, the “t...| Home on rand[om]
Here are some utility functions that have been useful when writing automation scripts. requests I like using requests or httpx, but if you add a dependency to your script, now you’ll need to create an environment, install the depdencies, etc. just to run it. I like keeping automation scripts in a single file I can copy around. Instead of using the requests, module, you can use this. This function has been adapted from the urlrequest function in fastai/fastcore.| Home on rand[om]
I wanted to query a large TSV file stored in S3. To achieve this, I decided to convert it to Parquet and query it using DuckDB. However, I didn’t want to download the full file and then convert it. Instead, I wanted to stream the CSV file directly from S3 and write the output to a Parquet file. Here are a couple of approaches that worked quite nicely. Setup I’m running these experiments on an EC2 instance with 8 cores and 32GB of RAM. The data is stored in a 700GB gp2 volume with 2100 IOPS.| Home on rand[om]
Sometimes calling a subprocess is better than using a dependency/package. At least in Python, once you add a third-party dependency, distribution becomes slightly harder. I like writing automation scripts in a single .py file. If that script doesn’t use any third-party dependencies, distributing it is as easy as copying the file to the machine. Otherwise you need to package your project, deal with virtual environments, PyPi, pipx, etc. I don’t think all of those tasks are hard, but rsync...| Home on rand[om]
DuckDB version 0.10.0 has been released, bringing some new array functions. You can use them to turn DuckDB into a vector database. (Make sure you have at least version 0.10.0 of DuckDB version to …| ricardoanderegg.com
This post could also be called “Or how to do React in Python” or “HTML as a function of state”. Most people use templating libraries like jinja2 to render HTML. I think …| ricardoanderegg.com
I like using Makefiles. They work great both as simple task runners as well as build systems for medium-size projects. This is my starter template for Python projects. Note: This blog post assumes …| ricardoanderegg.com

tl;dr conn.execute( "select * from ... where ... in (select value from json_each(?))", (json.dumps(list_of_values),), ) Lists of values in SQLite SQLite doesn’t have an array type as …| ricardoanderegg.com

Engineers like automating tasks. You find yourself running a set of commands, copying values between files and prompts, and you think I can automate this! Aside from the joke: “why spend 30 minutes …| ricardoanderegg.com

In this post, I want to share some reasons why using SQLite turns into a pretty convenient developer experience. This is a “live” post that may be updated in the future with more contents. Moving and …| ricardoanderegg.com
One of the main pain points of using SQLite in production deployments or VMs is managing the database. There are lots of database GUIs, but only work with local SQLite databases. Managing an SQLite …| ricardoanderegg.com
Python generators are mighty, but they lack a couple of useful features. One of them is peeking the next item without consuming the generator. Even better, what if we could peek any number of items? …| ricardoanderegg.com
SQLite has a powerful extension mechanism: loadable extensions. Being an in-process database, SQLite has other extensions mechanisms like application-defined functions (UDF for short). But UDFs have …| ricardoanderegg.com

If you have ever used the built-in sqlite3 module in a multithreaded Python application, you may have seen this message. sqlite3.ProgrammingError: SQLite objects created in a thread can only be used …| ricardoanderegg.com
The best code is the one that is easy to understand. The problem Source People don’t focus on code readability. Readability is like writing documentation. It takes extra time, more key presses, …| ricardoanderegg.com
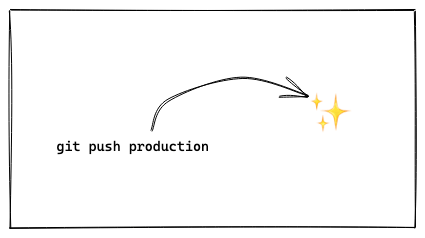
In this post I want to explain a new deployment method I came up with while working on drwn.io. I wanted it to meet a few requirements: Simple Based on git tags Zero-downtime Easy rollbacks Creating …| ricardoanderegg.com

What is a Bloom Filter? A Bloom filter is a probabilistic data structure. It tells you if an element is in a set or not in a very fast and memory-efficient way. A Bloom filter can tell if an element …| ricardoanderegg.com

Some time ago I published a post about managing Conda environments. My workflow has changed quite a bit since then, and I’ve moved to venv + pip-tools, but I’ll leave that for another …| ricardoanderegg.com

Storytelling is part of the human essence. Stories have let humans survive until today, they became the medium to move information between individuals. Programming can be considered another form of …| ricardoanderegg.com
I wrote my degree dissertation in jupyter notebooks. Then I converted them to markdown and finally to pdf with pandoc. I also had to output an office file so that my tutor could work on it too. The …| ricardoanderegg.com

Manage conda environments and Jupyterlab easily. TL;DR Use this script to create a base conda environment with Jupyterlab and some plugins, and this to create new environments and make them available …| ricardoanderegg.com

We live in a fast changing world, everyone seems to be working on the next big thing while you still haven’t got used to the previous big thing. We look at technology, science and innovation as …| ricardoanderegg.com
The story of a bug fix. I found a bug in the default Haskell installer ghcup, fixed it in my computer and had the fix merged to the public installer. I started doing the MIT course Programming with …| ricardoanderegg.com
Some problems are harder than others, but having a system to approach them makes a big difference. Yesterday I finished teaching my first Python course. Apart from teaching about generators, …| ricardoanderegg.com
When dealing with a multilingual dataset doing language identification is a very important part of the analysis process, here I’ll show a way to do a fast ⚡️ and reliable ✨ language …| ricardoanderegg.com
After nearly a year coding in Python (although not consistently), I started trying code formatters and discovered they were more useful than I thought. Here are some reason why. First, I must admit …| ricardoanderegg.com
These are just a few Python snippets that I have been using a lot for timing and profiling functions using only the standard library. You can also find the code here as a GitHub Gist import contextlib …| ricardoanderegg.com
macOS AirPlay Receiver now listens on port 5000 by default, which conflicts with the default port used by some frameworks (like Flask). This may cause some confusion if you’re trying to forward …| ricardoanderegg.com
In Python you can create dataclasses with the wrong type. The type checker should show an error, but nothing prevents creating the object. This small function validates that each attribute is of the …| ricardoanderegg.com
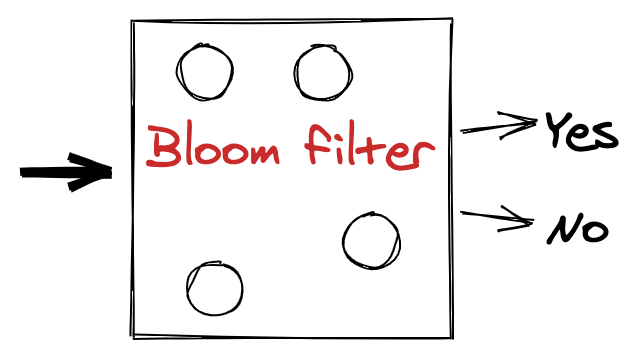
A Bloom filter is a probabilistic data structure present in many common applications. Its purpose is answering the question: “is this item in the set?” very fast and not using a lot of …| ricardoanderegg.com
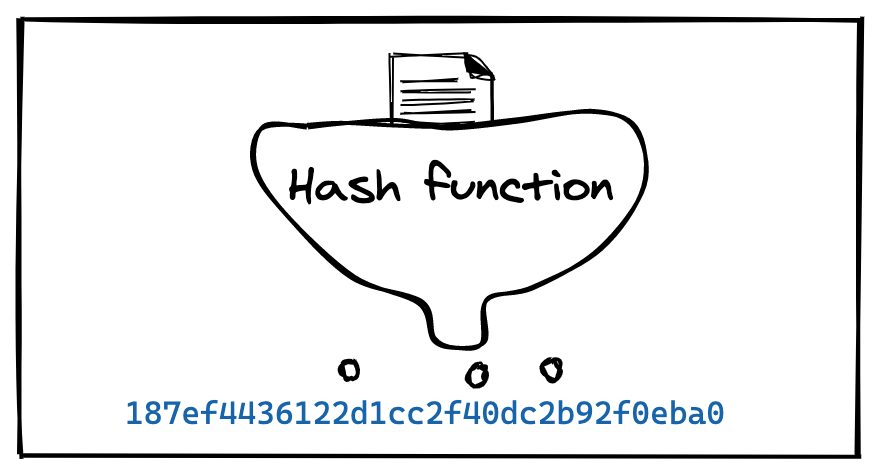
Hash functions are a fundamental part of modern programming. They map a variable-sized input to a fixed-size output. We can use them to: Verify the integrity of files and make sure they have not been …| ricardoanderegg.com

Our attention spans are short. Even more when looking for new information. We get flooded by different sources. Most of them contain little useful information. Content should be concise, packed with …| ricardoanderegg.com

Docker runs as root. The programs executing inside containers too. Make it a bit better. # do everything you need as root (maybe installing some dependencies) # create a non-root user RUN addgroup …| ricardoanderegg.com
There is a little trick I just found about, which I think can be very useful when you split tasks across different notebooks. Jupyter notebooks keep gaining popularity and use cases, the rapid growth …| ricardoanderegg.com
This works only in the same Python process, you can’t share an in-memory SQLite database between processes in this way. import sqlite3 # NOTE: you need to use uri=True # 3 connections to the …| ricardoanderegg.com
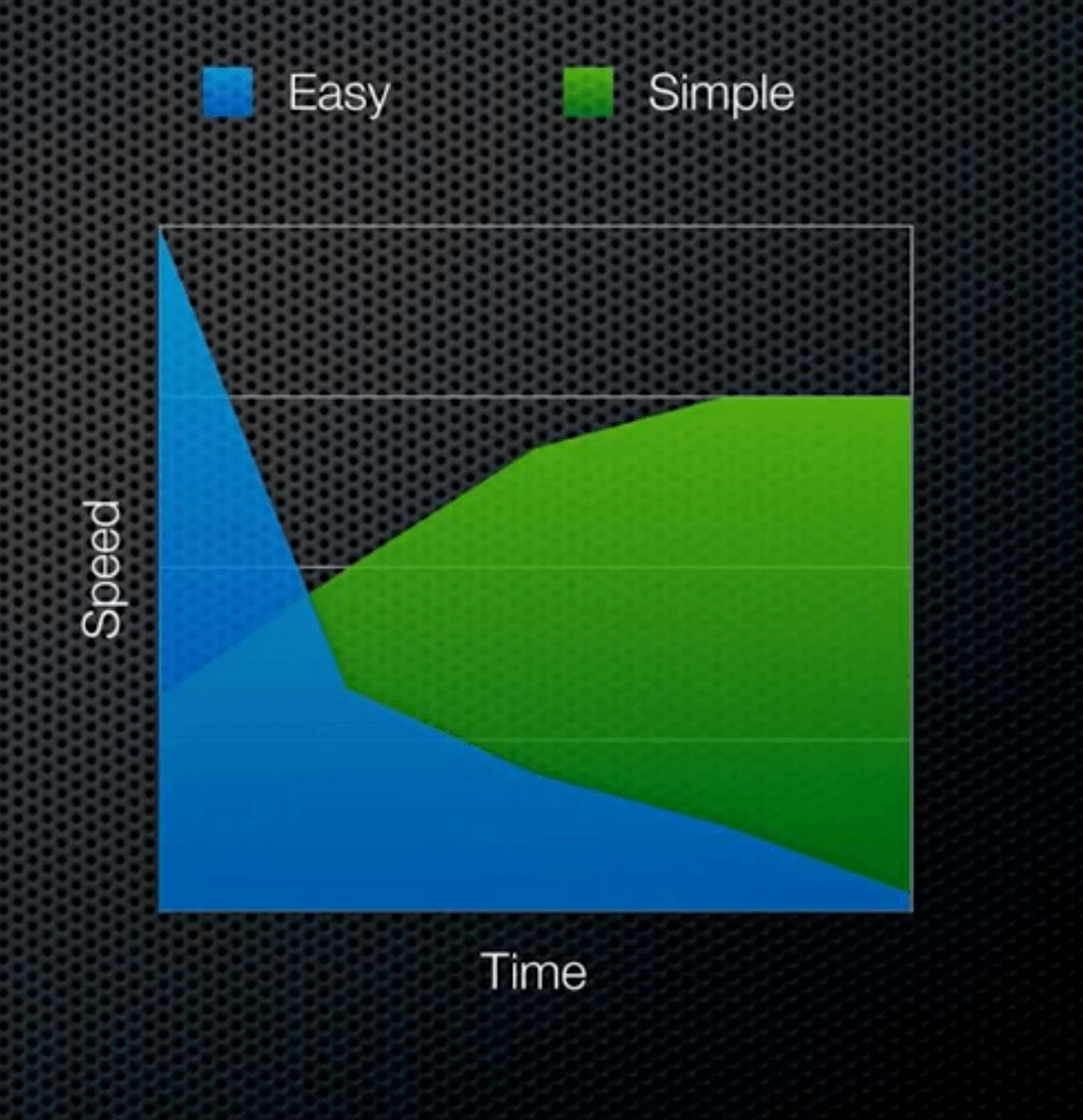
These are my notes on the talks “Simple Made Easy” by Rich Hickey. Simplicity is a prerequisite for reliability - Dijkstra Simple: One role. One task. One concept. One dimension. Lack of …| ricardoanderegg.com

Feedback is one of the most importante things when you are creating a product (probably the most important one!), so it should be easy for users to give feedback. In this post we’ll see how to …| ricardoanderegg.com

I could not get reliable connections with docker-machine or docker context. This is how I got 100% reliable connections through ssh forwarding. It’s also more secure. You don’t need to …| ricardoanderegg.com
