Learn how to build performant, scalable AI agents with efficient vector retrieval, hybrid dense-sparse search, real-time memory, multimodal context integration, and optimized architectures for low-latency, high-accuracy execution in production environments.| qdrant.tech
Multi-vector representations are superior to single-vector embeddings in many benchmarks. MUVERA embeddings aim to solve the problem of slow multi-vector search by creating a single-vector representation that approximates the multi-vector representation. This single vector can be used for fast initial retrieval using traditional vector search methods, and then the multi-vector representation can be used for reranking the top results.| qdrant.tech
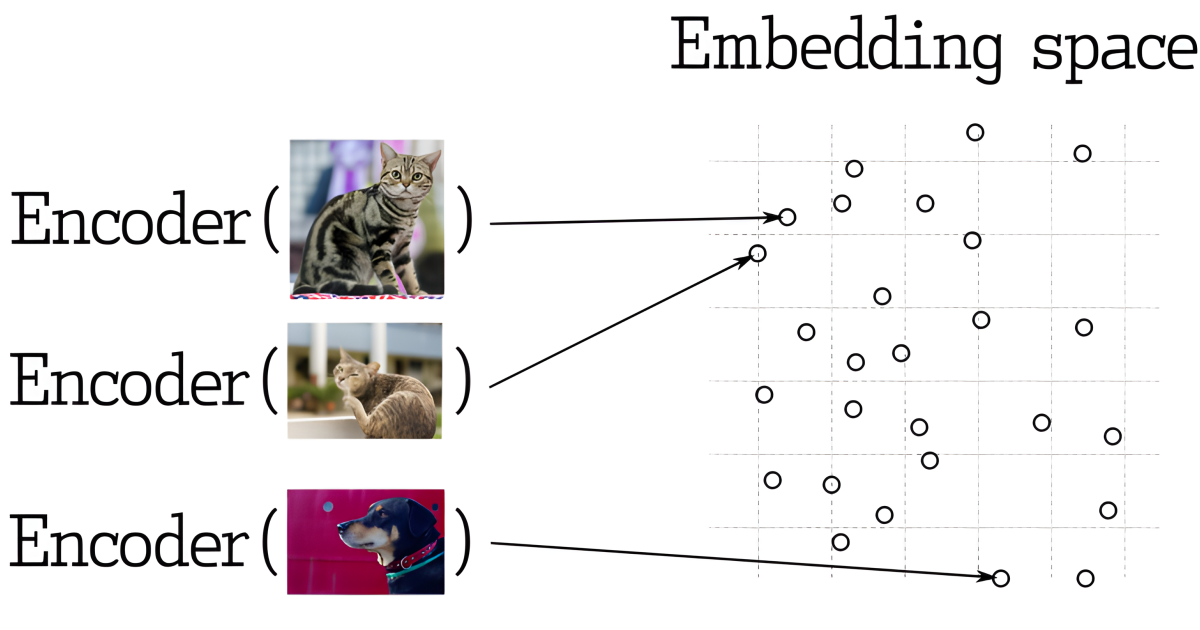
Building proper search requires selecting the right embedding model for your specific use case. This guide helps you navigate the selection process based on performance, cost, and other practical considerations.| qdrant.tech
Relerance feedback: from ancient history to LLMs. Why relevance feedback techniques are good on paper but not popular in neural search, and what we can do about it.| qdrant.tech
What’s in This Guide? Resource Management Strategies: If you are trying to scale your app on a budget - this is the guide for you. We will show you how to avoid wasting compute resources and get the maximum return on your investment. Performance Improvement Tricks: We’ll dive into advanced techniques like indexing, compression, and partitioning. Our tips will help you get better results at scale, while reducing total resource expenditure.| Qdrant Articles on Qdrant - Vector Database
Any problem with even a bit of complexity requires a specialized solution. You can use a Swiss Army knife to open a bottle or poke a hole in a cardboard box, but you will need an axe to chop wood — the same goes for software. In this article, we will describe the unique challenges vector search poses and why a dedicated solution is the best way to tackle them.| Qdrant Articles on Qdrant - Vector Database
Efficient memory management is key when handling large-scale vector data. Learn how to optimize memory consumption during bulk uploads in Qdrant and keep your deployments performant under heavy load.| qdrant.tech
Agents are a new paradigm in AI, and they are changing how we build RAG systems. Learn how to build agents with Qdrant and which framework to choose.| qdrant.tech
Finding enough time to study all the modern solutions while keeping your production running is rarely feasible. Dense retrievers, hybrid retrievers, late interaction… How do they work, and where do they fit best? If only we could compare retrievers as easily as products on Amazon! We explored the most popular modern sparse neural retrieval models and broke them down for you. By the end of this article, you’ll have a clear understanding of the current landscape in sparse neural retrieval a...| Qdrant Articles on Qdrant - Vector Database
Introduction Hi everyone! I’m Huong (Celine) Hoang, and I’m thrilled to share my experience working at Qdrant this summer as part of their Summer of Code 2024 program. During my internship, I worked on integrating cross-encoders into the FastEmbed library for re-ranking tasks. This enhancement widened the capabilities of the Qdrant ecosystem, enabling developers to build more context-aware search applications, such as question-answering systems, using Qdrant’s suite of libraries. This p...| Qdrant Articles on Qdrant - Vector Database
Introduction Hello, everyone! I’m Jishan Bhattacharya, and I had the incredible opportunity to intern at Qdrant this summer as part of the Qdrant Summer of Code 2024. Under the mentorship of Andrey Vasnetsov, I dived into the world of performance optimization, focusing on enhancing vector visualization using WebAssembly (WASM). In this article, I’ll share the insights, challenges, and accomplishments from my journey — one filled with learning, experimentation, and plenty of coding adven...| Qdrant Articles on Qdrant - Vector Database
What is Semantic Cache? Semantic cache is a method of retrieval optimization, where similar queries instantly retrieve the same appropriate response from a knowledge base. Semantic cache differs from traditional caching methods. In computing, cache refers to high-speed memory that efficiently stores frequently accessed data. In the context of vector databases, a semantic cache improves AI application performance by storing previously retrieved results along with the conditions under which the...| Qdrant Articles on Qdrant - Vector Database
Qdrant is designed as an efficient vector database, allowing for a quick search of the nearest neighbours. But, you may find yourself in need of applying some extra filtering on top of the semantic search. Up to version 0.10, Qdrant was offering support for keywords only. Since 0.10, there is a possibility to apply full-text constraints as well. There is a new type of filter that you can use to do that, also combined with every other filter type.| Qdrant Articles on Qdrant - Vector Database
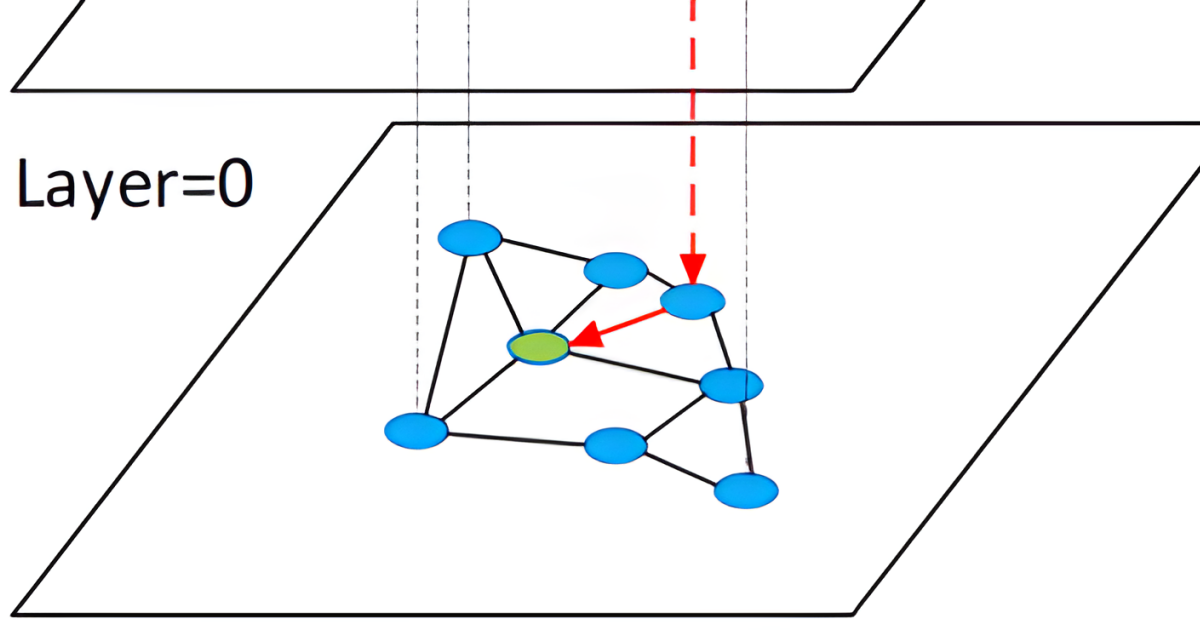
How to Optimize Vector Storage by Storing Multiple Vectors Per Object In a real case scenario, a single object might be described in several different ways. If you run an e-commerce business, then your items will typically have a name, longer textual description and also a bunch of photos. While cooking, you may care about the list of ingredients, and description of the taste but also the recipe and the way your meal is going to look.| Qdrant Articles on Qdrant - Vector Database
How to Optimize Vector Search Using Batch Search in Qdrant 0.10.0 The latest release of Qdrant 0.10.0 has introduced a lot of functionalities that simplify some common tasks. Those new possibilities come with some slightly modified interfaces of the client library. One of the recently introduced features is the possibility to query the collection with multiple vectors at once — a batch search mechanism. There are a lot of scenarios in which you may need to perform multiple non-related tasks...| Qdrant Articles on Qdrant - Vector Database
Vector quantization is a data compression technique used to reduce the size of high-dimensional data. Compressing vectors reduces memory usage while maintaining nearly all of the essential information. This method allows for more efficient storage and faster search operations, particularly in large datasets. When working with high-dimensional vectors, such as embeddings from providers like OpenAI, a single 1536-dimensional vector requires 6 KB of memory. With 1 million vectors needing around ...| Qdrant Articles on Qdrant - Vector Database
Imagine you sell computer hardware. To help shoppers easily find products on your website, you need to have a user-friendly search engine. If you’re selling computers and have extensive data on laptops, desktops, and accessories, your search feature should guide customers to the exact device they want - or a very similar match needed. When storing data in Qdrant, each product is a point, consisting of an id, a vector and payload:| Qdrant Articles on Qdrant - Vector Database
Data Structures 101 Those who took programming courses might remember that there is no such thing as a universal data structure. Some structures are good at accessing elements by index (like arrays), while others shine in terms of insertion efficiency (like linked lists). Hardware-optimized data structure However, when we move from theoretical data structures to real-world systems, and particularly in performance-critical areas such as vector search, things become more complex. Big-O notation...| Qdrant Articles on Qdrant - Vector Database
Introducing BM42 - a new sparse embedding approach, which combines the benefits of exact keyword search with the intelligence of transformers.| qdrant.tech
In today’s fast-paced, information-rich world, AI is revolutionizing knowledge management. The systematic process of capturing, distributing, and effectively using knowledge within an organization is one of the fields in which AI provides exceptional value today. The potential for AI-powered knowledge management increases when leveraging Retrieval Augmented Generation (RAG), a methodology that enables LLMs to access a vast, diverse repository of factual information from knowledge stores, su...| Qdrant Articles on Qdrant - Vector Database
Discover how Qdrant's Role-Based Access Control (RBAC) ensures data privacy and compliance for your AI applications. Build secure and scalable systems with ease. Read more now!| qdrant.tech
Explore how RAG enables LLMs to retrieve and utilize relevant external data when generating responses, rather than being limited to their original training data alone.| qdrant.tech
Sparse vectors, Discovery API, user-defined sharding, and snapshot-based shard transfer. That's what you can find in the latest Qdrant 1.7.0 release!| qdrant.tech
We explore some of the promising new techniques that can be used to expand use-cases of unstructured data and unlock new similarities-based data exploration tools.| qdrant.tech
Discover the efficiency of scalar quantization for optimized data storage and enhanced performance. Learn about its data compression benefits and efficiency improvements.| qdrant.tech
Quantum Quantization enables vector search in constant time. This article will discuss the concept of quantum quantization for ANN vector search.| qdrant.tech
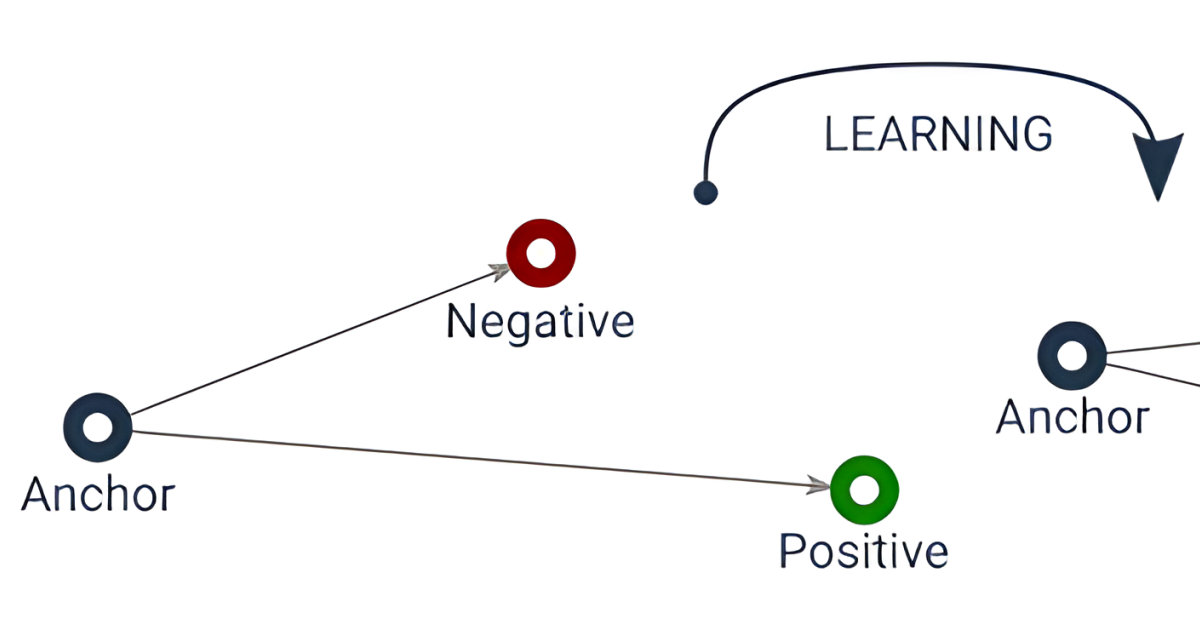
Practical use of metric learning for anomaly detection. A way to match the results of a classification-based approach with only ~0.6% of the labeled data.| qdrant.tech