Back in a previous company (the same place as where Debugging GDI Handle Leaks happened), there was an interesting convention in the database: all tables had a unique 3-letter prefix assigned to them, and all columns in that table must start with the prefix, which I’ve written about before. For example, a person table would have the prefix PEO, and the columns would be PEO_PersonID, PEO_FirstName, PEO_DateOfBirth, etc. When you wanted to create a new table, you opened the shared Excel sheet...| andydote.co.uk
A system I am working on at the moment started giving errors occasionally, say 5 times out of 10,000 messages or so. The error was pretty straightforward: json: cannot unmarshal array into Go struct field Thing.Parts of type Parts The data structure it is referring to looks like this: type Thing struct { Parts Parts } type Parts struct { Part []Part } Which represents the (slightly weird) json structure we receive in a message:| Andy Dote
Many years ago, I was working on a dotnet Windows Forms application. The application had many issues overall: memory leaks, random crashes, data loss, and in this case, the “red x” problem. The problem showed up at random, and instead of a window, dialogue, or control being rendered, it would be replaced with a white box with a red outline and red diagonal cross, and I think some error text in one corner, saying something about GDI handles.| andydote.co.uk
I use opentelemetry extensively to trace my applications, and one thing I keep running into is when writing a long running process, I want to handle OS signals and still send the telemetry on shutdown. Typically, my application startup looks something like this: func main() { ctx, cancel := context.WithCancel(context.Background()) handleSignals(cancel) tracerProvider := configureTelemetry(ctx) defer tracerProvider.Shutdown(ctx) tr = traceProvider.Tracer("cli") if err := runMain(ctx, os.Args[:...| andydote.co.uk
Following on from my previous post about not having too much configuration, I want to talk about how I design software. I try and follow what I call “outside in design”; I try and make something that requires the bare minimum amount of configuration to cover the most common of use-cases. Once this functionality is working, further configuration can be added to cover the next most common use cases. API Reduction As A Feature The first example I want to go through is how I removed options f...| andydote.co.uk
This is my thoughts after reading Don’t Look Down on Print Debugging. TLDR Print debugging is a tool, and it has its uses - however, if there are better tools available, maybe use those instead. For me, a better tool is OpenTelemetry tracing; it gives me high granularity, parent-child relationships between operations, timings, and is filterable and searchable. I can also use it to debug remote issues, as long as the user can send me a file.| andydote.co.uk
When writing software, you will come across many questions which don’t always have a clear answer, and its tempting to not answer the question, and provide it as a configuration option to the user of your software. You might go as far as setting a default value though. This seems good for everyone; you don’t have to make a decision, users can change their minds whenever they want. However, too much configuration is a bad thing in general.| andydote.co.uk
A question at work came up recently about how to handle multiple errors in a single span. My reaction is that having multiple errors in a span is a design smell, but I had no particular data or spec to back this up, just a gut feeling. I’ve since thought about this more and think that in general, you should only have one error per span, but there are circumstances where multiple indeed makes sense.| andydote.co.uk
In one of my too many side projects, I am using htmx and go templates to render a somewhat complicated web UI. I much prefer using htmx for this kind of thing rather than react, as react brings in so much more additional complexity than I need or want. However, there is one thing I miss from the React ecosystem, and that is hot reload. Being able to save a file in my editor and see the changes instantly in a web browser is an amazing developer experience, and I want to recreate that for htmx.| andydote.co.uk
I haven’t seen Expand-Contract written about in some years, and I think it is a great way of performing database schema migrations without the need for application downtime. I also realised that it also applies to microservices and service-to-service communication in general. The Easy Example One of the two examples given is wanting to change how an address is stored in a database. The schema starts off looking like this:| andydote.co.uk
It is no secret that I am not a fan of logs; I’ve baited (rapala in work lingo. Rapala is a Finnish brand of fishing lure, and used to mean baiting in this context) discussion in our work chat with things like: If you’re writing log statements, you’re doing it wrong. This is a pretty incendiary statement, and while there has been some good discussion after, I figured it was time to write down why I think logs are bad, why tracing should be used instead, and how we get from one to the ot...| andydote.co.uk
One of the many reasons given for using microservices rather than a mono repository is that it enforces boundaries between services/modules. However, there are ways to achieve strong boundaries between modules/services in one repository, using tools which are already available: test runners. Given a repository with the following structure: . ├── libraries │ ├── core │ ├── events │ └── ui ├── services │ ├── catalogue │ ├── billing │ └─...| andydote.co.uk
Versioning is one of the many hard problems when it comes to writing software. There is no one correct way to do it, and all have various tradeoffs. After reading keep a changelog, I was inspired to implement this into a couple of CLI tools that I am working on at the moment: Flagon (feature flags on the CLI, for CI usage), and Cas (Content Addressable Storage for Make), but I also wanted to solve my versioning and release process.| andydote.co.uk
When migrating to a continuous delivery process, it is often the case that a QA team are worried about what their role is going to be, and how the changes will affect the quality of the software in question. While doing continuous delivery does change the QA process, when done well, it improves everyone’s lives and makes the software better quality. Are silver bullets incoming? Not quite, but we don’t have to make someone’s life worse to improve other people’s lives.| andydote.co.uk
Recently we were having a debate about release processes, and I wrote that deployments are not always equal to releases. also deploy != release —Andy, baiting discussion in Slack This turned out to be somewhat controversial until we discussed what I specifically meant by deploy and release. As with all things, agreeing on definitions or understanding what someone means when they use a specific term is essential, so I thought I would write down a short blog post on it.| andydote.co.uk
At NDC Oslo this year, I attended Adam Ralph’s talk on Finding Your Service Boundaries. I enjoyed it a lot, and once the video came out, I rewatched it, and decided to have a go at doing a “sketchnotes”, which I shared on Twitter, which people liked! I’ve never done one before, but it was pretty fun. I made it in OneNote, zoomed out a lot, and took a screenshot.| andydote.co.uk
My work’s wifi is much faster than my 4G connection, so periodically I want to update all my docker images on my personal laptop while at work. As I want to just set it going and then forget about it, I use the following one liner to do a docker pull against each image on my local machine: docker images | grep -v REPOSITORY | awk '{print $1}'| xargs -L1 docker pull If you only want to fetch the versions you have the tags for:| andydote.co.uk
Last time we went through creating a Dockerfile for a microservice, with the service being compiled on creation of the container image, using xbuild. However we might not want to compile the application to create the container image, and use an existing version (e.g. one created by a build server.) Our original Dockerfile was this: FROM mono:3.10-onbuild RUN apt-get update && apt-get install mono-4.0-service -y CMD [ "mono-service", "./MicroServiceDemo.exe", "--no-daemon" ] EXPOSE 12345 We on...| andydote.co.uk
Tracking where the time goes in your CI pipeline is an important step towards being able to make it go even faster. Up until somewhat recently, the only way of tracking how long tasks took in CI was either hoping people had wrapped all their commands in time ..., or by reading a timestamped build log and calculating the difference between numbers. Which isn’t great or fun, if we’re being honest.| andydote.co.uk
Feature flags are a great tool for helping software development; they provide controlled feature rollouts, facilitate A/B testing, and help decouple deployment from release. So when it comes to building our software, why do we treat the CI pipeline without the same level of engineering as the production code? So, why not use feature flags in your CI pipeline? TLDR Reduce the risk of breaking a CI pipeline for all of a project’s developers by using the flagon CLI to query Feature Flags, opti...| andydote.co.uk
On several occasions when building complex projects, I have been tempted to set up Bazel to help speed up the build process; after all, it has a lot to offer: only building what has changed, caching built artifacts, and sharing that cache between machines for even more speed. TLDR We can use Make and a couple of short shell scripts to implement file content-based caching and read/write that cache to remote storage, such as S3.| andydote.co.uk
I write a lot of blog posts which contain code snippets. Like most people, I have done this using a fenced codeblock in markdown which is fine for short blocks of code. The problem occours when I am embedding code from another repository; often there will be tweaks or bug fixes, and keeping the code in the blog post in sync with the code in the other repo is annoying and manual.| andydote.co.uk
One of the reasons I prefer Pulumi over Terraform is the additional control I have over my processes due to the fact that it’s a programming language. For example, I have a CLI, that creates a cluster of machines for a user; the machines use IAM Authentication with Vault so that they can request certificates on boot. The trouble with this application is that it is slow; it takes 175 seconds on average to provision the machines, write the IAM information to Vault, and then re-run the cloud-i...| andydote.co.uk
I recently encountered a behaviour in Nginx that I didn’t expect and caused a production outage in the process. While I would love to blame DNS for this, as it’s usually the cause of most network-related issues, in this case, the fault lies with Nginx. I was running a very simple Nginx proxy, relaying an internal service to the outside world. The internal service is behind an AWS ALB, and the Nginx configuration was proxying to the ALB’s FQDN:| andydote.co.uk
The Operator Pattern from Kubernetes is an excellent way of handling tasks in a cluster in an automated way, for example, provisioning applications, running backups, requesting certificates, and injecting chaos testing. As a Nomad user, I wanted to do something similar for my clusters, so I set about seeing how it would be possible. It turns out; it is much easier than I expected! While Nomad doesn’t support the idea of Custom Resource Definitions, we can achieve an operator by utilising a ...| andydote.co.uk
An interesting question came up at work today: how do you tag your Docker images? In previous projects, I’ve always used a short git sha, or sometimes a semver, but with no great consistency. As luck would have it, I had pushed for a change in tagging format at a client not so long ago as the method we were using didn’t make a lot of sense and, worst of all, it was a manual process.| andydote.co.uk
Key Takeaway: os .cpus() returns the number of cores on a Kubernetes host, not the number of cores assigned to a pod. Investigating excessive memory usage Recently, when I was looking through a cluster health dashboard for a Kubernetes cluster, I noticed that one of the applications deployed was using a considerable amount of RAM - way more than I thought could be reasonable. Each instance (pod) of the application used approximately 8 GB of RAM, which was definitely excessive for a reasonably...| andydote.co.uk
One of the things I like to do when setting up a Vault cluster is to visualise all the operations Vault is performing, which helps see usage patterns changing, whether there are lots of failed requests coming in, and what endpoints are receiving the most traffic. While Vault has a lot of data available in Prometheus telemetry, the kind of information I am after is best taken from the Audit backend.| andydote.co.uk
I had the need to get some OpenTelemetry data out of a NodeJS application, and into NewRelic’s distributed tracing service, but found that there is no way to do it directly, and in this use case, adding a separate collector is more hassle than it’s worth. Luckily, there is an NodeJS OpenTelemetry library which can report to Zipkin, and NewRelic can also ingest Zipkin format data. To use it was relatively straight forward:| andydote.co.uk
This article was originally published on the Pulumi blog. When using the Pulumi Automation API to create applications which can provision infrastructure, it is very handy to be able to use observability techniques to ensure the application functions correctly and to help see where performance bottlenecks are. One of the applications I work on creates a VPC and Bastion host and then stores the credentials into a Vault instance. The problem is that the “create infrastructure” part is an opa...| andydote.co.uk
Following on from my last post on Isolated Multistage Docker Builds, I thought it would be useful to cover another advantage to splitting your dockerfiles: building different output containers from a common base. The Problem When I have an application which when built, needs to have all assets in one container, and a subset of assets in a second container. For example, writing a node webapp, where you want the compiled/bundled static assets available in the container as a fallback, and also s...| andydote.co.uk
Often when building applications, I will use a multistage docker build for output container size and efficiency, but will run the build in two halves, to make use of the extra assets in the builder container, something like this: docker build \ --target builder \ -t builder:$GIT_COMMIT \ . docker run --rm \ -v "$PWD/artefacts/tests:/artefacts/tests" \ builder:$GIT_COMMIT \ yarn ci:test docker run --rm \ -v "$PWD/artefacts/lint:/artefacts/lint" \ builder:$GIT_COMMIT \ yarn ci:lint docker build...| andydote.co.uk
I write a lot of bash scripts for both my day job and my personal projects, and while they are functional, bash scripts always seem to lack that structure that I want, especially when compared to writing something in Go or C#. The main problem I have with bash scripts is that when I use functions, I lose the ability to log things. For example the get_config_path function will print the path to the configuration file, which will get consumed by the do_work function:| andydote.co.uk
Recently, I noticed that when we pull a new version of our application’s docker container, it fetches all layers, not just the ones that change. The problem is that we use ephemeral build agents, which means that each version of the application is built using a different agent, so Docker doesn’t know how to share the layers used. While we can pull the published container before we run the build, this only helps with the final stage of the build.| andydote.co.uk
When it comes to implementing a new feature in an application’s ecosystem, I don’t like spending my innovation tokens unless I have to, so I try not to add new tools to my infrastructure unless I really need them. This same approach comes when I either want, need, or have been told, to implement a Service Mesh. This means I don’t instantly setup Istio. Not because it’s bad - far from it - but because it’s extra complexity I would rather avoid, unless I need it.| andydote.co.uk
Before I start on this, I want to make it clear that if you can buy Honeycomb, you should. Outlined below is how I started to add observability to an existing codebase which already had the ELK stack available, and was unable to use Honeycomb. My hope, in this case, is that I can demonstrate how much value observability gives, and also show how much more value you would get with an excellent tool, such as Honeycomb.| andydote.co.uk
One of the many features of Nomad that I like is the ability to run things other than Docker containers. It has built-in support for Java, QEMU, and Rkt, although the latter is deprecated. Besides these inbuilt “Task Drivers” there are community maintained ones too, covering Podman, LXC, Firecraker and BSD Jails, amongst others. The one I want to talk about today, however, is called exec. This Task Driver runs any given executable, so if you have an application which you don’t want (or ...| andydote.co.uk
I noticed when running an Alpine based virtual machine with Consul DNS forwarding set up, that sometimes the machine couldn’t resolve *.consul domains, but not in a consistent manner. Inspecting the logs looked like the request was being made and responded to successfully, but the result was being ignored. After a lot of googling and frustration, I was able to track down that it’s down to a difference (or optimisation) in musl libc, which glibc doesn’t do.| andydote.co.uk
I use Vagrant when testing new machines and experimenting locally with clusters, and since moving (mostly) to Linux, I have been using the LibVirt Plugin to create the virtual machines. Not only is it significantly faster than Hyper-V was on windows, but it also means I don’t need to use Oracle products, so it’s win-win really. The only configuration challenge I have had with it is setting up VM hostname resolution, and as I forget how to do it each time, I figured I should write about it.| andydote.co.uk
I will update this post as I learn more (both positive and negative), and is here to be linked to when people ask me why I don’t like Kubernetes, and why I would pick Nomad in most situations if I chose to use an orchestrator at all. TLDR: I don’t like complexity, and Kubernetes has more complexity than benefits. Operational Complexity Operating Nomad is very straight forward. There are very few moving parts, so the number of things which can go wrong is significantly reduced.| andydote.co.uk
So we want to set up a Vault instance, and have it’s storage be a TLS based Consul cluster. The problem is that the Consul cluster needs Vault to create the certificates for TLS, which is quite the catch-22. Luckily for us, quite easy to solve: Start a temporary Vault instance as an intermediate ca Launch Consul cluster, using Vault to generate certificates Destroy temporary Vault instance Start a permanent Vault instance, with Consul as the store Reprovision the Consul cluster with certifi...| andydote.co.uk
I was recently using my Hashibox for a test, and I noticed the DNS resolution didn’t seem to work. This was a bit worrying, as I have written about how to do DNS resolution with Consul forwarding in Ubuntu, and apparently something is wrong with how I do it. Interestingly, the Alpine version works fine, so it appears there is something not quite working with how I am configuring Systemd-resolved.| andydote.co.uk
This post is going to go through how to set up a Consul cluster to communicate over TLS. I will be using Vagrant to create three machines locally, which will form my cluster, and in the provisioning step will use Vault to generate the certificates needed. How to securely communicate with Vault to get the TLS certificates is out of scope for this post. Host Configuration Unless you already have Vault running somewhere on your network, or have another mechanism to generate TLS certificates for ...| andydote.co.uk
Often when developing or testing some code, I need (or want) to use SSL, and one of the easiest ways to do that is to use Vault. However, it gets pretty annoying having to generate a new CA for each project, and import the CA cert into windows (less painful in Linux, but still annoying), especially as I forget which cert is in use, and accidentally clean up the wrong ones.| andydote.co.uk
This is a text version of a short talk (affectionately known as a “Coffee Bag”) I gave at work this week, on Architecture Design Records. You can see the slides here, but there isn’t a recording available, unfortunately. It should be noted; these are not to replace full architecture diagrams; you should definitely still write C4 Models to cover the overall architecture. ADRs are for the details, such as serializer formats, convention-over-configuration details, number precisions for tim...| andydote.co.uk
I wanted to implement canary routing for some HTTP services deployed via Nomad the other day, but rather than having the traffic split by weighting to the containers, I wanted to direct the traffic based on a header. My first choice of tech was to use Fabio, but it only supports routing by URL prefix, and additionally with a route weight. While I was at JustDevOps in Poland, I heard about another router/loadbalancer which worked in a similar way to Fabio: Traefik.| andydote.co.uk
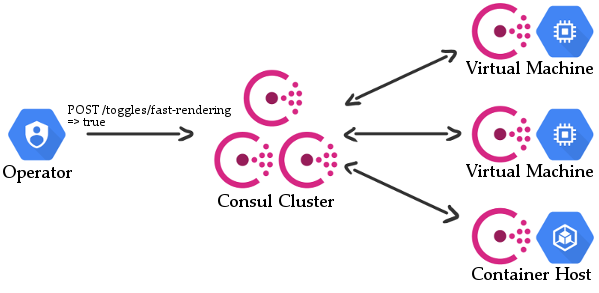
One of the points I make in my Feature Toggles talk is that you shouldn’t be querying a toggle’s status all over your codebase. Ideally, each toggle gets checked in as few places as possible - preferably only one place. The advantage of doing this is that very little of your codebase needs to be coupled to the toggles (either the toggle itself or the library/system for managing toggles itself).| andydote.co.uk
Recently, I was asked if I could provide an example of Branch By Abstraction when dealing with feature toggles. As this has come up a few times, I thought a blog post would be a good idea so I can refer others to it later too. The Context As usual, this is some kind of backend (micro)service, and it will send email messages somehow. We will start with two implementations of message sending: the “current” version; which is synchronous, and a “new” version; which is async.| andydote.co.uk
DEPRECATED - This has a race condition! Please see this post for an updated version which works! Following on from the post the other day on setting up DNS forwarding to Consul with SystemD, I wanted also to show how to get Consul up and running under Alpine Linux, as it’s a little more awkward in some respects. To start with, I am going to setup Consul as a service - I didn’t do this in the Ubuntu version, as there are plenty of useful articles about that already, but that is not the cas...| andydote.co.uk
DEPRECATED - This doesn’t work properly Please see this post for an updated version which works! One of the advantages of using Consul for service discovery is that besides an HTTP API, you can also query it by DNS. The DNS server is listening on port 8600 by default, and you can query both A records or SRV records from it. SRV records are useful as they contain additional properties (priority, weight and port), and you can get multiple records back from a single query, letting you do load ...| andydote.co.uk
Last time I wrote about running a RabbitMQ cluster in Nomad, one of the main pieces of feedback I received was about the (lack) of security of the setup, so I decided to revisit this, and write about how to launch as secure RabbitMQ node in Nomad. The things I want to cover are: Username and Password for the management UI Secure value for the Erlang Cookie SSL for Management and AMQP As usual, the demo repository with all the code is available if you’d rather just jump into that.| andydote.co.uk
I had a major problem a few hours before giving my Nomad: Kubernetes Without the Complexity talk this morning: the demo stopped working. Now, the first thing to note is the entire setup of the demo is scripted, and the scripts hadn’t changed. The only thing I had done was restart the machine, and now things were breaking. The Symptoms A docker container started inside the guest VMs with a port mapped to the machine’s public IP wasn’t resolvable outside the host.| andydote.co.uk
Update If you want a secure version of this cluster, see Running a Secure RabbitMQ Cluster in Nomad. RabbitMQ is the centre of a lot of micros service architectures, and while you can cluster it manually, it is a lot easier to use some of the auto clustering plugins, such as AWS (EC2), Consul, Etcd, or Kubernetes. As I like to use Nomad for container orchestration, I thought it would be a good idea to show how to cluster RabbitMQ when it is running in a Docker container, on an unknown host (i.| andydote.co.uk
In my previous post, I glossed over one of the most important and useful parts of Immutable Infrastructure: Testability. There are many kinds of tests we can write for our infrastructure, but they should all be focused on the machine/service and maybe it’s nearest dependencies, not the entire system. While this post focuses on testing a full machine (both locally in a VM, and remotely as an Amazon EC2 instance), it is also possible to do most of the same kind of tests against a Docker conta...| andydote.co.uk
I wanted to show request charts (similar to the network tab in firefox) for requests across our microservices but wanted to do so in the least invasive way possible. We already use LogStash to collect logs from multiple hosts (via FileBeat) and forward them on to ElasticSearch, so perhaps I can do something to also output from LogStash to a tracing service. There are a number of tracing services available (AppDash, Jaeger, Zipkin), but unfortunately LogStash doesn’t have plugins for any of ...| andydote.co.uk
Well, for Applications & Services at least. For libraries, SemVer is the way to go, assuming you can agree on what a breaking change is defined as. But when it comes to Applications (or SaaS products, websites, etc.) SemVer starts to break down. The problem starts with the most obvious: What is a breaking change? How about a minor change? What’s in a change? For example, if we were to change the UI of a web application, which caused no backend changes, from the user perspective it is probab...| andydote.co.uk
…about GitHub open source commit streak. This is, I think, partially triggered by Marc Gravell’s post. I currently have had a GitHub commit streak going on 1878 days. The other night I realised, that I don’t care about it any more, and more so, I’m not sure why I did to start with. I didn’t even mean to start doing it. I just noticed one day that I had done something every day for a couple of weeks, and vaguely wondered how long I could keep that up for.| andydote.co.uk
One of the reasons people list for using MicroServices is that it helps enforce separation of concerns. This is usually achieved by adding a network boundary between the services. While this is useful, it’s not without costs; namely that you’ve added a set of new failure modes: the network. We can achieve the same separation of concerns within the same codebase if we put our minds to it. In fact, this is what Simon Brown calls a Modular Monolith, and DHH calls the Majestic Monolith.| andydote.co.uk
After my previous post on Validating Your Configuration, one of my colleagues made an interesting point, paraphrasing: I want to know if the configuration is valid earlier than that. At build time preferably. I don’t want my service to not start if part of it is invalid. There are two points here, namely when to validate, and what to do with the results of validation. Handling Validation Results If your configuration is invalid, you’d think the service should fail to start, as it might be...| andydote.co.uk
Feature Toggles are a great way of helping to deliver working software, although there are a few things which could go wrong. See my talk Feature Toggles: The Good, The Bad and The Ugly for some interesting stories and insights on it! I was talking with a colleague the other day about how you could go about implementing Feature Toggles in a centralised manner into an existing system, preferably with a little overhead as possible.| andydote.co.uk
As I have written many times before, your application’s configuration should be strongly typed and validated that it loads correctly at startup. This means not only that the source values (typically all represented as strings) can be converted to the target types (int, Uri, TimeSpan etc) but that the values are semantically valid too. For example, if you have a web.config file with the following AppSetting, and a configuration class to go with it:| andydote.co.uk
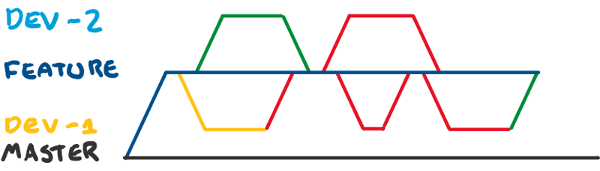
So this is a bit of a rant…but hopefully with some solutions and workarounds too. So let’s kick things off with a nice statement: I hate broken builds. So everyone basically agrees on this point I think. The problem is that I mean all builds, including ones on shared feature branches. Currently, I work on a number of projects which uses small(ish) feature branches. The way this works is that the team agrees on a new feature to work on creates a branch, and then each developer works on tas...| andydote.co.uk
Consul is a great utility to make running your microservice architecture very simple. Amongst other things, it provides Service Discovery, Health Checks, and Configuration. In this post, we are going to be looking at Configuration; not specifically how to read from Consul, but about how we put configuration data into Consul in the first place. The usual flow for an application using Consul for configuration is as follows: App Starts Fetches configuration from Consul Configures itself Register...| andydote.co.uk
The final part of my Vault miniseries focuses on permissioning, which is provided by Vault’s Policies. As everything in Vault is represented as a path, the policies DSL (Domain Specific Language) just needs to apply permissions to paths to lock things down. For example, to allow all operations on the cubbyhole secret engine, we would define this policy: path "cubbyhole/*" { capabilities = ["create", "read", "update", "delete", "list"] } Vault comes with a default policy which allows token o...| andydote.co.uk
I think Vault by Hashicorp is a great product - I particularly love how you can do dynamic secret generation (e.g for database connections). But how do you validate that the application requesting the secret is allowed to perform that action? How do you know it’s not someone or something impersonating your application? While musing this at an airport the other day, my colleague Patrik sent me a link to a StackOverflow post about this very question| andydote.co.uk
My normal development laptop runs Windows, but like a lot of developers, I make huge use of Docker, which I run under Hyper-V. I also heavily use the git bash terminal on windows to work. Usually, everything works as expected, but I was recently trying to run an ELK (Elasticsearch, Logstash, Kibana) container, and needed to pass in an extra configuration file for Logstash. This caused me a lot of trouble, as nothing was working as expected.| andydote.co.uk
One of the points I made in my recent NDC talk on 12 Factor microservices, was that you shouldn’t be storing sensitive data, such as API keys, usernames, passwords etc. in the environment variables. Don’t Store Sensitive Data in the Environment My reasoning is that when you were accessing Environment Variables in Heroku’s platform, you were actually accessing some (probably) secure key-value store, rather than actual environment variables. While you can use something like Consul’s key...| andydote.co.uk
I saw an interesting question on twitter today: Hey, people who talk at things: How long does it take you to put a new talk together? I need like 50 hours over at least a couple of months to make something I don’t hate. I’m trying to get that down (maybe by not doing pictures?) but wondering what’s normal for everyone else. Source I don’t know how long it takes me to write a talk - as it is usually spread over many weeks/months, worked on as and when I have inspiration.| andydote.co.uk
We have a test suite at work which tests a retry decorator class works as expected. One of the tests checks that when the inner implementation throws an exception, it will log the number of times it has failed: [Test] public async Task ShouldLogRetries() { var mockClient = Substitute.For(); var logger = Subsitute.For(); var sut = new RetryDecorator(mockClient, logger, maxRetries: 3); mockClient .GetContractPdf(Arg.Any()) .Throws(new ContractDownloadException()); try { await sut.GetContractPdf...| andydote.co.uk
Since I have been trying to learn a functional language (Elixir), I have noticed how grating it is when in C# I need to call a few methods in a row, passing the results of one to the next. The bit that really grates is that it reads backwards, i.e. the rightmost function call is invoked first, and the left hand one last, like so: await WriteJsonFile(await QueueParts(await ConvertToModel(await ReadBsxFile(record)))); In Elixir (or F# etc.| andydote.co.uk
When we are developing (internal) Nuget packages at work, the process used is the following: Get latest of master New branch feature-SomethingDescriptive Implement feature Push to GitHub TeamCity builds Publish package to the nuget feed Pull request Merge to master Obviously 3 to 6 can repeat many times if something doesn’t work out quite right. There are a number of problems with this process: Pull-request after publishing Pull requests are a great tool which we use extensively, but in thi...| andydote.co.uk
Having recently finished reading the Building Evolutionary Architectures: Support Constant Change book, I got to thinking about a system which was fairly representative of an architecture which was fine for it’s initial version, but it’s usage had outgrown the architecture. Example System: Document Storage The system in question was a file store for a multi user, internal, desktop based CRM system. The number of users was very small, and the first implementation was just a network file sh...| andydote.co.uk
It’s no secret I am a fan of strong typing - not only do I talk and blog about it a lot, but I also have a library called Stronk which provides strong typed configuration for non dotnet core projects. The problem I come across often is large configurations. For example, given the following project structure (3 applications, all reference the Domain project): DemoService `-- src |-- Domain | |-- Domain.| andydote.co.uk
I’ve been on-call for work over the last week for the first time, and while it wasn’t as alarming (heh) as I thought it might be, I have had a few thoughts on it. Non-action Alarms We have an alarm periodically about an MVC View not getting passed the right kind of model. The resolution is to mark the bug as completed/ignored in YouTrack. Reading the stack trace, I can see that the page is expecting a particular model, but is being given a HandleErrorInfo model, which is an in built type.| andydote.co.uk
I gave a little talk at work recently on my use of Vagrant, what it is, and why it is still useful in a world full of Docker containers. So, What is Vagrant? Vagrant is a product by Hashicorp, and is for scripting the creation of (temporary) virtual machines. It’s pretty fast to create a virtual machine with too, as it creates them from a base image (known as a “box”.| andydote.co.uk
We have a service which consumes messages from a RabbitMQ queue - for each message, it makes a few http calls, collates the results, does a little processing, and then pushes the results to a 3rd party api. One of the main benefits to having this behind a queue is our usage pattern - the queue usually only has a few messages in it per second, but periodically it will get a million or so messages within 30 minutes (so from ~5 messages/second to ~560 messages/second.| andydote.co.uk
While I was developing my Crispin project, I ended up needing to create a bunch of implementations of a single interface, and then use all those implementations at once (for metrics logging). The interface looks like so: public interface IStatisticsWriter { Task WriteCount(string format, params object[] parameters); } And we have a few implementations already: LoggingStatisticsWriter - writes to an ILogger instance StatsdStatisticsWriter - pushes metrics to StatsD InternalStatisticsWriter - a...| andydote.co.uk
When building libraries, not only is it a good idea to have a large suite of Unit Tests, but also a suite of Integration Tests. For one of my libraries (RabbitHarness) I have a set of tests which check it behaves as expected against a real instance of RabbitMQ. Ideally these tests will always be run, but sometimes RabbitMQ just isn’t available such as when running on AppVeyor builds, or if I haven’t started my local RabbitMQ Docker container.| andydote.co.uk
This post is a summary of a stream I did last night where I implemented all of this. If you want to watch me grumble my way through it, it’s available on YouTube here. In my Crispin project, I wanted the ability to support loading Toggles by both name and ID, for all operations. As I use mediator to send messages from my controllers to the handlers in the domain, this means that I had to either:| andydote.co.uk
The trouble with testing containers is that usually the test ends up very tightly coupled to the implementation. Let’s see an example. If we start off with an interface and implementation of a “cache”, which in this case is just going to store a single string value. public interface ICache { string Value { get; set; } } public class Cache { public string Value { get; set; } } We then setup our container (StructureMap in this case) to return the same instance of the cache whenever an ICa...| andydote.co.uk
TLDR: I still don’t like Repositories! Recently I had a discussion with a commenter on my The problems with, and solutions to Repositories post, and felt it was worth expanding on how I don’t use repositories. My applications tend to use the mediator pattern to keep things decoupled (using the Mediatr library), and this means that I end up with “handler” classes which process messages; they load something from storage, call domain methods, and then write it back to storage, possibly r...| andydote.co.uk
This article has been updated after feedback from .Net Junkie (Godfather of SimpleInjector). I now have a working SimpleInjector implementation of this, and am very appreciative of him for taking the time to help me :) Serilog is one of the main set of libraries I use on a regular basis, and while it is great at logging, it does cause something in our codebase that I am less happy about.| andydote.co.uk
I have been trying to actually be productive in my evenings and weekends, but I find I often end up not getting as much done as I feel I could have. I end up browsing imgur, reading slashdot, reddit, twitter, etc. rather than reading books, writing or anything else. The first point doesn’t fit in anywhere else, but somewhere I saw a tip about keeping a house clean (I think):| andydote.co.uk
I hit an problem the recently with Terraform, when I was trying to hook up a Lambda Trigger to a Kinesis stream. Both the lambda itself, and the stream creation succeeded within Terraform, but the trigger would just stay stuck on “creating…” for at least 5 minutes, before I got bored of waiting and killed the process. Several attempts at doing this had the same issue. The code looked something along the lines of this:| andydote.co.uk
Hosting a static website with S3 is really easy, especially from terraform: First off, we want a public readable S3 bucket policy, but we want to apply this only to one specific bucket. To achive that we can use Terraform’s template_file data block to merge in a value: { "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadGetObject", "Effect": "Allow", "Principal": "*", "Action": [ "s3:GetObject" ], "Resource": [ "arn:aws:s3:::${bucket_name}/*" ] } ] } As you can see the interpolati...| andydote.co.uk
Programmers have a fascination with writing frameworks for some reason. There are many problems with writing frameworks: Opinions Frameworks are opinionated, and will follow their author’s opinions on how things should be done, such as application structure, configuration, and methodology. The problem this gives is that not everyone will agree with the author, or their framework’s opinions. Even if they really like part of how the framework works, they might not like another part, or migh...| andydote.co.uk
I have been writing simple webhook type applications using Claudiajs, which in behind the scenes is using Aws’s Lambda and Api Gateway to make things happen, but I really wanted to understand what exactly it was doing for me, and how I could achieve the same results using Terraform. The Lambda Function I started off with a simple NodeJS function, in a file called index.js exports.handler = function(event, context, callback) { callback(null, { statusCode: '200', body: JSON.| andydote.co.uk
Often when developing something, I have the need to check how a function or library works. For example, I always have to check for this question: Does Directory.ListFiles(".\\temp\\") return a list of filenames, a list of relative filepaths, or a list of rooted filepaths? It returns relative filepaths by the way: Directory.ListFiles(".\\temp\\"); [ ".\temp\NuCrunch.Tests.csproj", ".\temp\packages.config", ".\temp\Scratchpad.cs" ] Now that there is a C# Interactive window in Visual Studio, you...| andydote.co.uk
Having recently watched Greg Young’s excellent talk on 8 Lines of Code I was thinking about how this kind of thinking applies to the mediator pattern, and specifically the MediatR implementation. I have written about the advantages of CQRS with MediatR before, but having used it for a long time now, there are some parts which cause friction on a regular basis. The problems Discoverability The biggest issue first. You have a controller with the following constructor:| andydote.co.uk
Git is great, but creating some git aliases is a great way to make your usages even more efficient. To add any of these you can either copy and paste into the [alias] section of your .gitconfig file or run git config --global alias.NAME 'COMMAND' replacing NAME with the alias to use, and COMMAND with what to run. So without further ado, here are the ones I have created and use on a very regular basis.| andydote.co.uk
As anyone I work with can attest, I a have been prattling on about strong typing everything for quite a while. One of the places I feel people don’t utilise strong typing enough is in application configuration. This manifests in a number of problems in a codebase. The Problems The first problem is when nothing at all is done about it, and you end up with code spattered with this:| andydote.co.uk
I like to make my development life as easy as possible - and removing small irritations is a great way of doing this. Having used Shouldly in anger for a long time, I have to say I feel a little hamstrung when going back to just using NUnit’s assertions. I have been known on a couple of projects which use only NUnit assertions, when trying to solve a test failure with array differences, to install Shouldly, fix the test, then remove Shouldly again!| andydote.co.uk
My new place of work has a lot of nuget packages, and I wanted to understand the dependencies between them. To do this I wrote a simple shell script to find all the packages.config files on my machine, and output all the relationships in a way which I could view them. The format for viewing I use for this is Graphviz’s dot language, and the resulting output can be pasted into WebGraphviz to view.| andydote.co.uk
One of the downsides to microservices I have found is that I end up repeating the same blocks of code over and over for each service. Not only that, but the project setup is repetitive, as all the services use the Single Project Service and Console method. What do we do in every service? Initialise Serilog. Add a Serilog sink to ElasticSearch for Kibana (but only in non-local config.) Hook/Unhook the AppDomain.| andydote.co.uk
This is a follow up post after seeing Michal Franc’s NDC talk on migrating from Monolithic architectures. One point raised was that Database Integration points are a terrible idea - and I wholeheartedly agree. However, there can be a number of situations where a Database Integration is the best or only way to achieve the end goal. This can be either technical; say a tool does not support API querying (looking at you SSRS), or cultural; the other team either don’t have the willingness, tim...| andydote.co.uk
This article is some extra thoughts I had on api structure after reading Derek Comartin. Asides from the benefits that Derek mentions (no fat repositories, thin controllers), there are a number of other advantages that this style of architecture brings. Ease of Testing By using Command and Queries, you end up with some very useful seams for writing tests. For controllers With controllers, you typically use Dependency injection to provide an instance of IMediator:| andydote.co.uk
Quite a number of my projects involve talking to RabbitMQ, and to help check things work as expected, I often have a number of integration tests which talk to a local RabbitMQ instance. While this is fine for tests being run locally, it does cause problems with the build servers - we don’t want to install RabbitMQ on there, and we don’t typically want the build to be dependent on RabbitMQ.| andydote.co.uk
When changing a project’s build script over to Gulpjs, I ran into a problem with one step - creating an AssemblyInfo.cs file. My projects have their version number in the package.json file, and I read that at compile time, pull in some information from the build server, and write that to an AssemblyVersion.cs file. This file is not tracked by git, and I don’t want it showing up as a modification if you run the build script locally.| andydote.co.uk
Recently I have been writing a WebApi project which needs to accept plaintext via the body of a PUT request, and did the logical thing of using the FromBodyAttribute public HttpStatusCode PutKv([FromBody]string content, string keyGreedy) { return HttpStatusCode.OK; } Which didn’t work, with the useful error message of “Unsupported media type.” It turns out that to bind a value type with the FromBody attribute, you have to prefix the body of your request with an =.| andydote.co.uk
I have found that when developing MicroServices, I often want to run them from within Visual Studio, or just as a console application, and not have to bother with the hassle of installing as windows services. In the past I have seen this achieved by creating a Class Library project with all the actual implementation inside it, and then both a Console Application and Windows Service project referencing the library and doing nothing other than calling a .| andydote.co.uk