
Rafael Harth — AI Alignment Forum
Rafael Harth's profile on the AI Alignment Forum — A community blog devoted to technical AI alignment research| www.alignmentforum.org
Rafael Harth's profile on the AI Alignment Forum — A community blog devoted to technical AI alignment research| www.alignmentforum.org
Rohin Shah's profile on the AI Alignment Forum — A community blog devoted to technical AI alignment research| www.alignmentforum.org
John Schulman's profile on the AI Alignment Forum — A community blog devoted to technical AI alignment research| www.alignmentforum.org
danieldewey's profile on the AI Alignment Forum — A community blog devoted to technical AI alignment research| www.alignmentforum.org
Beth Barnes's profile on the AI Alignment Forum — A community blog devoted to technical AI alignment research| www.alignmentforum.org
Akbir Khan's profile on the AI Alignment Forum — A community blog devoted to technical AI alignment research| www.alignmentforum.org
Note: If you’ll forgive the shameless self-promotion, applications for my MATS stream are open until Sept 12. I help people write a mech interp paper…| www.alignmentforum.org
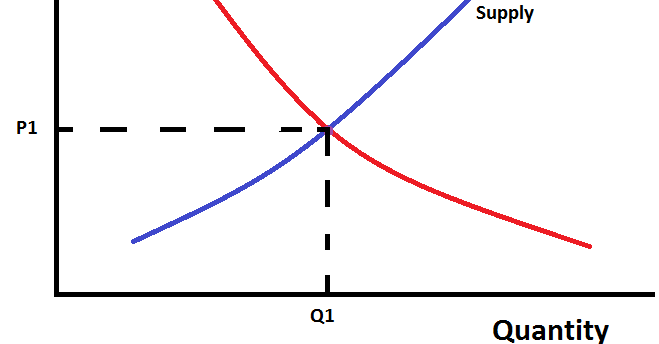
There’s a funny thing where economics education paradoxically makes people DUMBER at thinking about future AI. Econ textbooks teach concepts & frames that are great for most things, but counterproductive for thinking about AGI. Here are 4 examples…| www.alignmentforum.org

Interpretability provides access to AI systems' internal mechanisms, offering a window into how models process information and make decisions.| www.alignmentforum.org
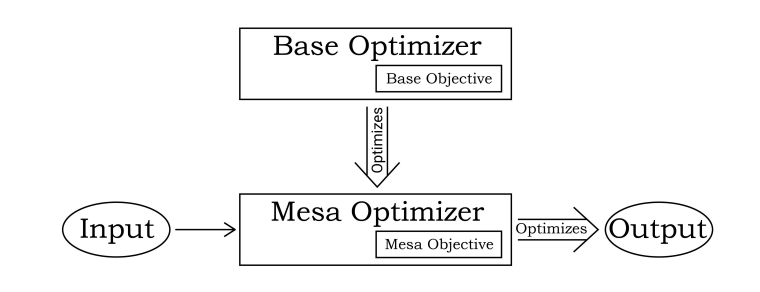
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under John Wentworth …| www.alignmentforum.org

An agent is corrigible when it robustly acts opposite of the trope of "be careful what you wish for" by cautiously reflecting on itself as a flawed tool and focusing on empowering the principal to fix its flaws and mistakes.| www.alignmentforum.org

This is the second post in a sequence mapping out the AI Alignment research landscape. The sequence will likely never be completed, but you can read…| www.alignmentforum.org
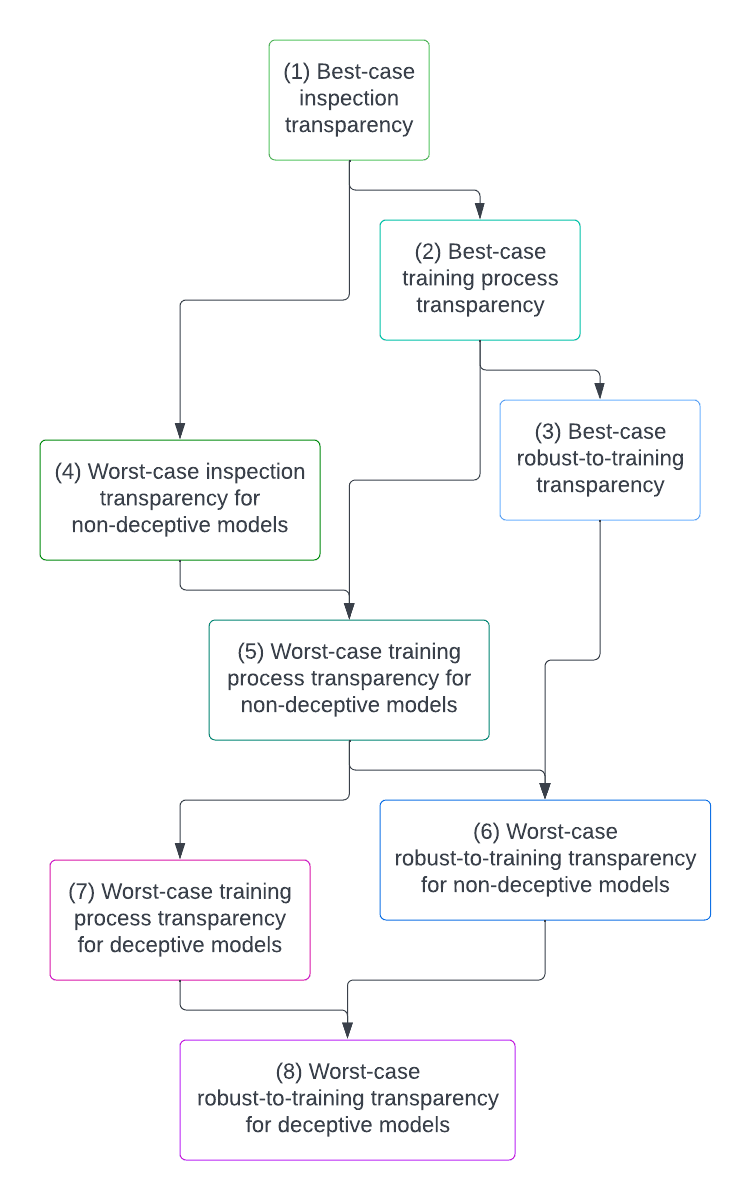
Thanks to Chris Olah, Neel Nanda, Kate Woolverton, Richard Ngo, Buck Shlegeris, Daniel Kokotajlo, Kyle McDonell, Laria Reynolds, Eliezer Yudkowksy, M…| www.alignmentforum.org

ARC explores the challenge of extracting information from AI systems that isn't directly observable in their outputs, i.e "eliciting latent knowledge…| www.alignmentforum.org
This is a response to ARC's first technical report: Eliciting Latent Knowledge. But it should be fairly understandable even if you didn't read ARC's…| www.alignmentforum.org
I wrote this post to get people’s takes on a type of work that seems exciting to me personally; I’m not speaking for Open Phil as a whole. Institutio…| www.alignmentforum.org
Thanks to Roger Grosse, Cem Anil, Sam Bowman, Tamera Lanham, and Mrinank Sharma for helpful discussion and comments on drafts of this post. …| www.alignmentforum.org
TL;DR: This document lays out the case for research on “model organisms of misalignment” – in vitro demonstrations of the kinds of failures that migh…| www.alignmentforum.org
This is an update on the work on AI Safety via Debate that we previously wrote about here. …| www.alignmentforum.org

Tl;dr We want to be able to supervise models with superhuman knowledge of the world and how to manipulate it. For this we need an overseer to be able…| www.alignmentforum.org

Paul Christiano paints a vivid and disturbing picture of how AI could go wrong, not with sudden violent takeover, but through a gradual loss of human…| www.alignmentforum.org

The original draft of Ayeja's report on biological anchors for AI timelines. The report includes quantitative models and forecasts, though the specif…| www.alignmentforum.org
We are no longer accepting submissions. We'll get in touch with winners and make a post about winning proposals sometime in the next month. …| www.alignmentforum.org
Behavior cloning (BC) is, put simply, when you have a bunch of human expert demonstrations and you train your policy to maximize likelihood over the…| www.alignmentforum.org
