Learn exactly which quantized LLMs you can run locally on an RTX 3090 with 24GB VRAM. This guide covers model sizes, context length limits, and optimal quantization settings for efficient inference.| Hardware Corner
We search the Web for the best refurbished computers. Find out what laptop or desktop suites you the most and what to look fore in recertified computer.| Hardware Corner
Learn how speculative decoding accelerates large language model inference by 4–5x without sacrificing output quality. Step-by-step setup for llama.cpp, and LM Studio| Hardware Corner
You’ve spent weeks picking out the parts for a powerful new computer. It has a top-tier CPU, plenty of fast storage, and maybe even a respectable graphics card. You download your first large language…| Hardware Corner
Learn what context length in large language models (LLMs) is, how it impacts VRAM usage and speed, and practical ways to optimize performance on local GPUs.| Hardware Corner
Explore the list of Qwen model variations, their file formats (GGML, GGUF, GPTQ, and HF), and understand the hardware requirements for local inference.| www.hardware-corner.net
Discover how quantization can make large language models accessible on your own hardware. Practical overview of popular formats like GGUF, GPTQ, and AWQ.| Hardware Corner
Large Language Models (LLMs) have rapidly emerged as powerful tools capable of understanding and generating human-like text, translating languages, writing different kinds of creative content…| Hardware Corner
NVIDIA’s Jet-Nemotron claims a 45x VRAM reduction for local LLMs. Here’s what that really means for speed, context length, and consumer GPUs.| Hardware Corner
The stream of mini-PCs built around AMD’s Ryzen AI 300 “Strix Halo” platform continues, this time with a new model named the X+ RIVAL. While the market is quickly becoming crowded with similar…| Hardware Corner
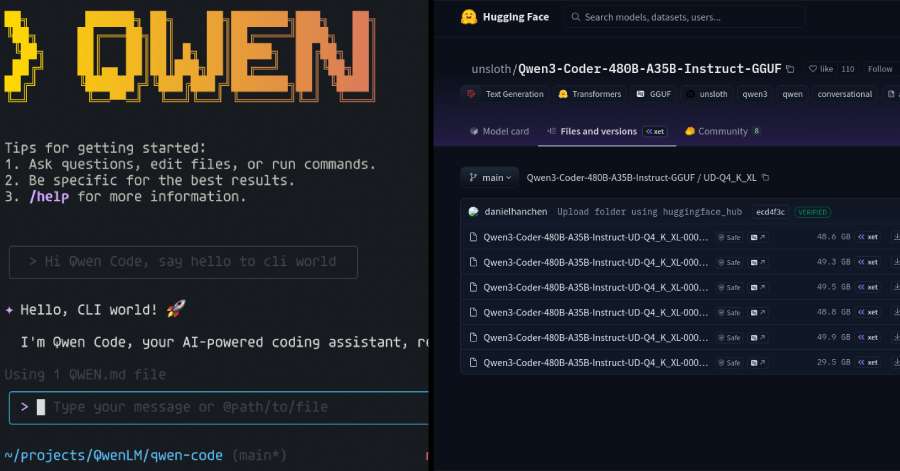
In a significant development for the AI community, the Qwen team has announced the release of its most powerful open agentic code model to date, the Qwen3-Coder-480B-A35B-Instruct.| Hardware Corner
The landscape for high-density, on-premise AI hardware is rapidly evolving, driven almost single-handedly by the arrival of AMD’s Ryzen AI 300 “Strix Halo” series. For the enthusiast dedicated to…| Hardware Corner
The GMK EVO-X2, which was recently showcased at AMD’s “ADVANCING AI” Summit, is designed to meet this need, packing impressive AI processing capabilities into a small form factor.| Hardware Corner
The arrival of AMD’s Ryzen AI MAX+ 395 “Strix Halo” APU has generated considerable interest among local LLM enthusiasts, promising a potent combination of CPU and integrated graphics performance with…| Hardware Corner
Bosman launches the M5 AI Mini-PC with 128GB RAM and Ryzen AI MAX+ for just $1699 — the most affordable Strix Halo system yet for running local LLMs| Hardware Corner
Zotac unveils plans for the Magnus EA mini-PC with AMD Strix Halo APU, aiming to bring powerful local LLM inference to compact, GPU-free systems.| Hardware Corner
Beelink has unveiled the GTR9 Pro AI Mini, a compact LLM-ready PC powered by the Ryzen AI MAX+ 395 APU with up to 128GB RAM and 110GB usable VRAM—designed for local LLM inference in a small form factor.| Hardware Corner
Chinese manufacturer FAVM has announced FX-EX9, a compact 2-liter Mini-PC powered by AMD’s Ryzen AI MAX+ 395 “Strix Halo” processor, potentially offering new options for enthusiasts running quantized…| Hardware Corner
AMD’s Ryzen AI MAX+ 395 (Strix Halo) brings a unique approach to local AI inference, offering a massive memory allocation advantage over traditional desktop GPUs like the RTX 3090, 4090…| Hardware Corner
GMKtec has officially priced its EVO-X2 SFF/Mini-PC at ~$2,000, positioning it as a potential option for AI enthusiasts looking to run large language models (LLMs) at home.| Hardware Corner
With 96GB of GDDR7 memory, 1.79 TB/s memory bandwidth, RTX PRO 6000 is the first single-card workstation GPU capable of fully loading an 8-bit quantized 70B model such as LLaMA 3.3.| Hardware Corner
While NVIDIA’s newly announced RTX Pro 6000 offers a straightforward 96GB VRAM solution, , a new wave of modified RTX 4090 from China – offering 48GB per card – has emerged as a potential alternative.| Hardware Corner
It is surprisingly straightforward to increase the VRAM of your Mac (Apple Silicone M1/M2/M3 chips) computer and use it to load large language models. Here’s the rundown of my experiments.| Hardware Corner