
Where Honeycomb Fits in the Software Development Lifecycle
In this blog post, Jessitron explains how Honeycomb fits into the software development lifecycle, with some helpful examples.| Honeycomb
In this blog post, Jessitron explains how Honeycomb fits into the software development lifecycle, with some helpful examples.| Honeycomb

In this article, we discuss application performance monitoring, also known as APM - what it is, benefits and challenges, and best practices.| Honeycomb

In part 1 of this OpenTelemetry Best Practices series, Martin Thwaites goes over naming, where consistency and standardization are key.| Honeycomb

Join Lex, SRE at Honeycomb, as he describes the incident retrospective process we abide by, and see why he was pleasantly surprised.| Honeycomb

LLMs demand we modify our behavior and tooling in ways that will benefit even ordinary, deterministic software development. Find out why.| Honeycomb

Phillip Carter provides guidelines around using LLMs in software development, like paying for Claude, asking for small changes, and more.| Honeycomb

Every day I seem to run into yet another post with someone solemnly opining that “writing code has never been the hardest part of software engineering. And hey, that’s smashing.| Honeycomb
Some people can get an AI assistant to write a day’s worth of useful code in ten minutes. Others among us can only watch it crank out hundreds of lines of crap that never works. What’s the difference? The post Will AI Speed Development in Your Legacy App? appeared first on Honeycomb.| Honeycomb
Honeycomb is proud to be named a Visionary in the 2025 Gartner® Magic Quadrant™ for Observability Platforms. We feel that our recognition by Gartner showcases our commitment to help engineering teams gain observability over complex environments—not just for today’s systems, but for whatever comes next. The post Honeycomb Named a Visionary in the 2025 Gartner® Magic Quadrant™ for Observability Platforms appeared first on Honeycomb.| Honeycomb
I’m pleased to announce the public beta of Honeycomb Hosted MCP, along with our first wave of one-click integrations for Cursor, Visual Studio Code, and Claude Desktop. We’re also very excited to announce that Hosted MCP is available on AWS AI Agents marketplace and for all Honeycomb plans (including our free plan!) at no charge. The post Honeycomb In Your IDE? Yes, With Hosted MCP Now Available in AWS Marketplace AI Agents and Tools Category appeared first on Honeycomb.| Honeycomb

SAN FRANCISCO – July 16 2025 – Honeycomb , the creators of observability, today announced the availability of the Honeycomb Hosted Model Context Protocol (MCP) Server in the new AI Agents and Tools category of AWS Marketplace. Customers can now use AWS Marketplace to easily discover, buy, and deploy AI agents solutions, including Honeycomb’s MCP server, using their AWS accounts.| Honeycomb
Over and over, we’ve seen that teams who invest in adding rich, relevant context to their telemetry end up debugging faster and collaborating more effectively during incidents. Getting meaningful context added can feel like a big cross-team project, but some of the highest-leverage improvements don’t require app code changes or coordination across services. The post The Fast Path to More Useful Telemetry appeared first on Honeycomb.| Honeycomb
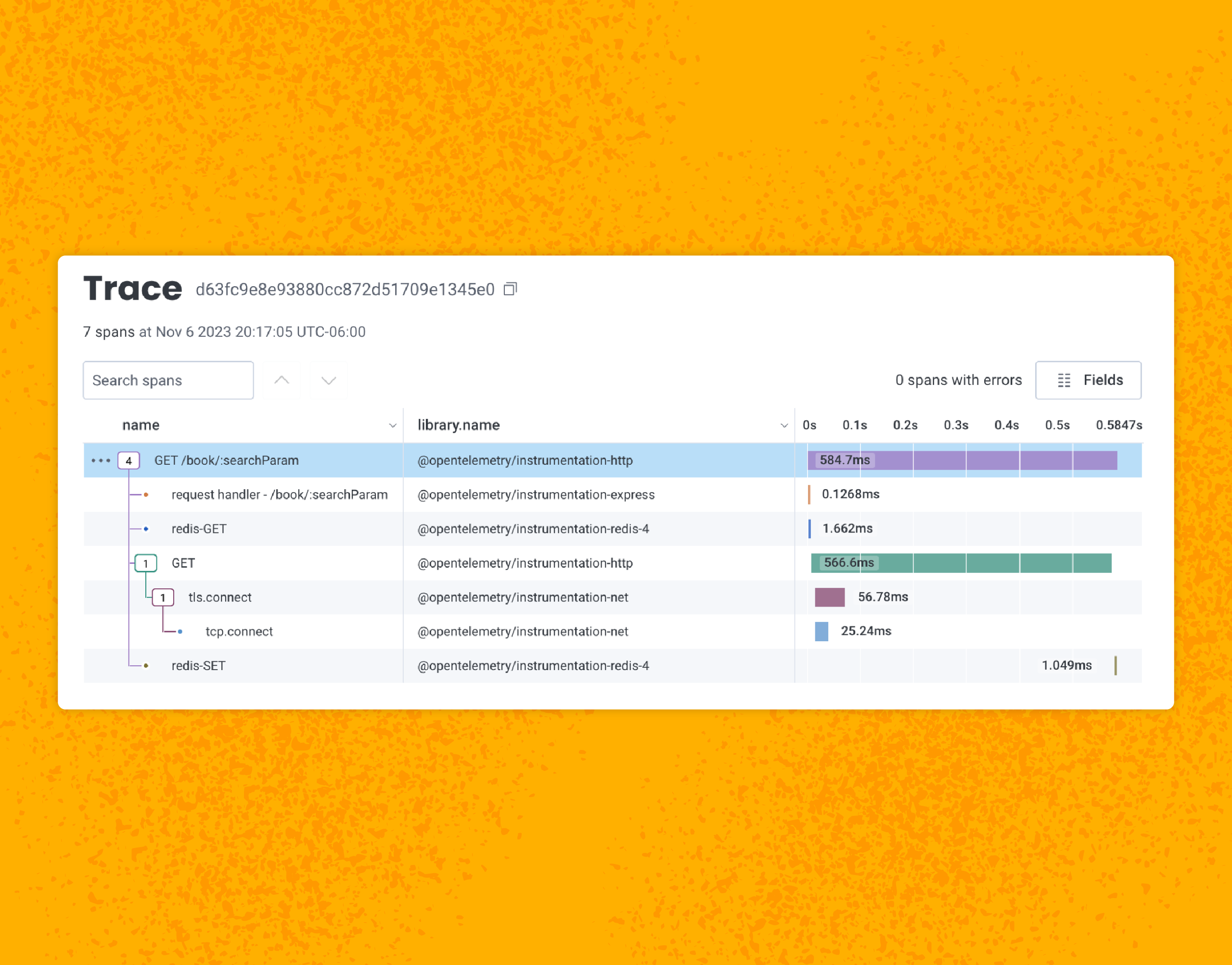
In this post, we’ll describe what traces are, how they work, and the value traces provide in observability, helping stakeholders understand their systems and delivering reliable services at scale and performance. The post What Are Traces? A Developer’s Guide to Distributed Tracing appeared first on Honeycomb.| Honeycomb

Many engineers & leaders are under pressure to apply sampling for cost savings purposes, but are concerned with the impacts on data quality.| Honeycomb
At LDX3 in London last week, two roundtables I hosted with engineering leaders confirmed what many of us are starting to feel: observability isn’t just important—it’s becoming essential to how modern teams navigate the pressure to move fast and stay resilient. The post Is Your Observability Strategy Boardroom-Ready? appeared first on Honeycomb.| Honeycomb

Claude Code added OpenTelemetry metric and log support in a recent release, which led Austin to ask, can Claude Code observe itself?| Honeycomb
With this release, you can more easily build and reconfigure telemetry pipelines and sample safely with the ability to easily pull full-fidelity data from your own archive whenever you need it. The post Observability Without Tradeoffs: Introducing Powerful New Honeycomb Telemetry Pipeline Features appeared first on Honeycomb.| Honeycomb

SAN FRANCISCO – June 24, 2025 – Honeycomb , the creators of observability, today announced a major milestone in helping enterprises maximize the value of their observability data. Building towards the industry’s first fully integrated telemetry pipeline , Honeycomb adds the ability to access archived telemetry data with a single click for full fidelity analysis from low cost storage, as well as powerful new ways to sample telemetry data and control costs.| Honeycomb

In part 2 of this OpenTelemetry Best Practices series, Martin Thwaites goes over agents, the Collector, coded instrumentation, & more.| Honeycomb

honeycomb.io is an observability platform designed to help engineering teams find and solve complex issues in their cloud applications| www.honeycomb.io

In this blog post, Charity Majors goes over the reasons it's time to version observability, and what to expect from observability 2.0.| Honeycomb

I’ve said this before, but I’m saying it again: observability is not a synonym for monitoring, and there are no three pillars. The pillars are bullshit. Briefly: monitoring is how you manage your known-unknowns,...| Honeycomb

Our Authors' Cut series takes a deep dive into our O’Reilly Observability Engineering book. Join us for this session on structured events.| Honeycomb

SRE Fred Hebert provides you with a list of questions to ask about potential AI solutions, including where humans should be involved.| Honeycomb

See how HelloFresh uses Honeycomb to help its service teams focus on creating business value by experimenting and delivering new features by reducing the friction of toiling against infrastructure and production issues.| Honeycomb

CCP Games shares how Honeycomb is critical to EVE Online’s continued evolution & their migration from monolith to microservices with Quasar.| Honeycomb
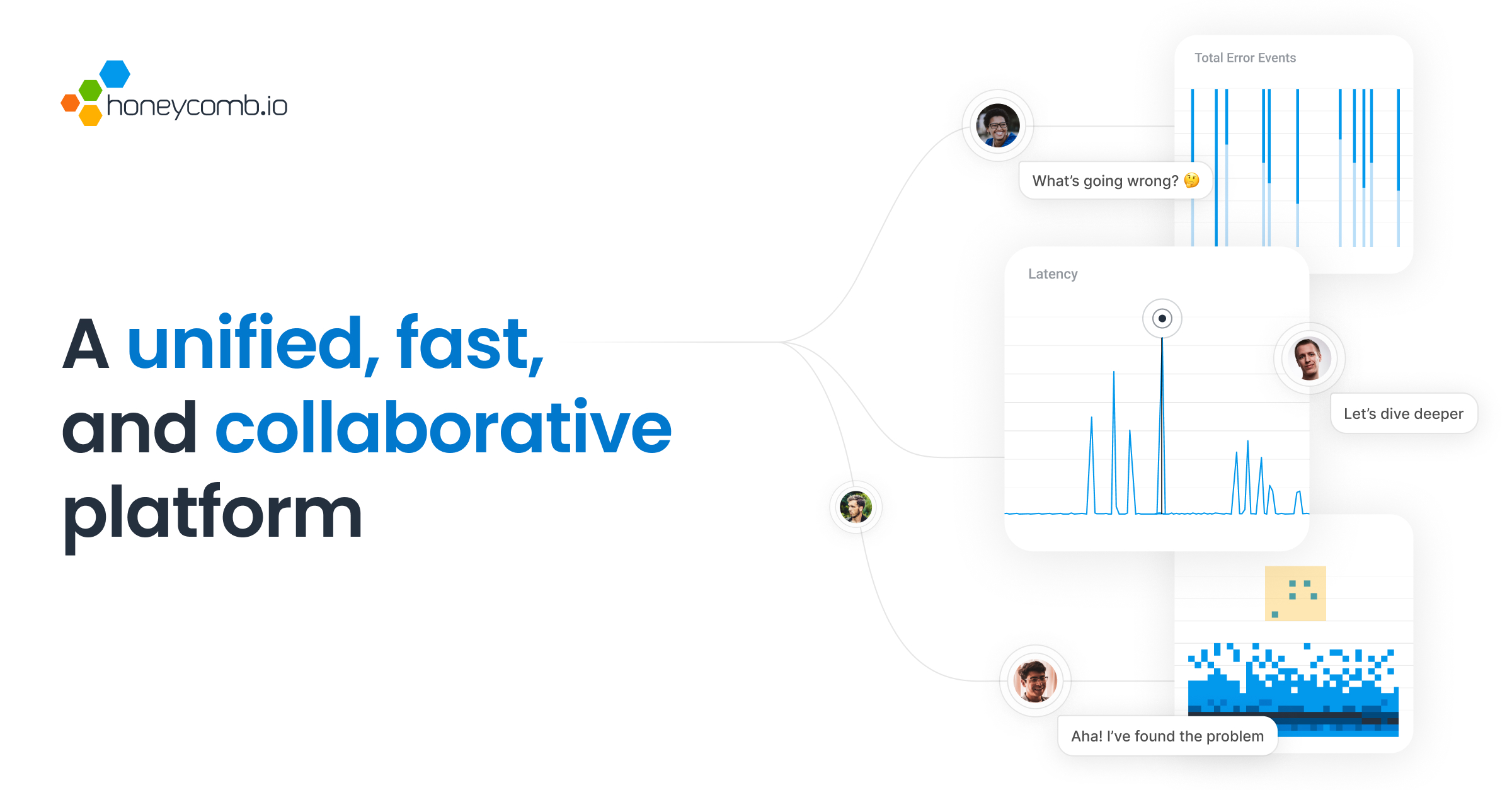
The Honeycomb observability platform provides a single source of truth for your data with robust anomaly detection & dynamic visualizations.| Honeycomb
See how users experience your systems in complex and unpredictable environments. Book a live demo of Honeycomb's observability solution.| www.honeycomb.io

We caught up with Michael Garski, Director of Platform Engineering at Fender, to hear how things are going with Honeycomb for Frontend Observability.| Honeycomb
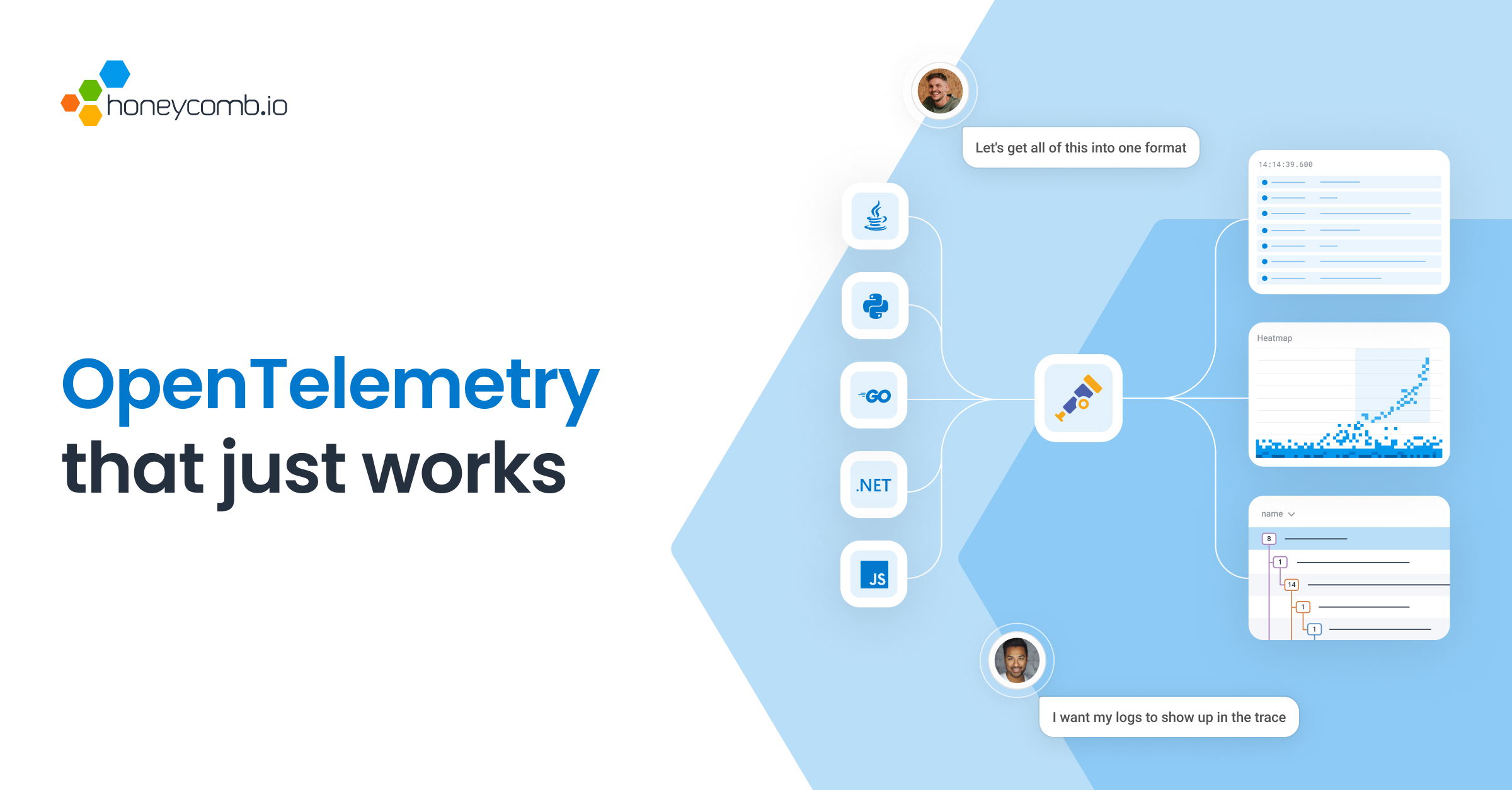
Unlock the true value of OpenTelemetry with Honeycomb. Navigate between traces, logs, and metrics in one place to resolve issues faster.| Honeycomb

In this article, SRE Reid talks through Honeycomb's internal SLOs and how different they are than at, say, a Google type. Learn more!| Honeycomb

In this article, Charity Majors goes over the simple, technical distinction between observability 1.0 and observability 2.0.| Honeycomb

The search-first problem-solving approach—meaning “open up the log search tool” (Splunk, ELK, Loggly, SumoLogic, Scalyr, etc)—is a costly and time-consuming operation during which the true source of a problem is rarely pinpointed in short...| Honeycomb

In part 6 of his series, Nick goes over techniques that grant teams and orgs the capacity to treat prod as a veritable source of information.| Honeycomb

In this post, guest author Jeremy Blythe goes over Semantic Conventions in OpenTelemetry, including many best practices for naming.| Honeycomb

Introducing budget rate alerts, which will let you know if you’ve burned more than X% of your budget during a given time window, even if the budget is below 0%.| Honeycomb

This post described two types of alerts - reactive and proactive - and how a CoPE should approach each type.| Honeycomb
Learn how Honeycomb’s unique datastore makes it possible for you to find issues for a single user or complex patterns across multiple users & services.| Honeycomb

Understanding high-cardinality data is essential to observability. Learn about high cardinality best practices for setting up datasets & analysis.| Honeycomb

Confused by all the terminology surrounding observability? Get the definitions and clarifications you need in our observability glossary.| Honeycomb

Instrument code, even if it is written by someone else, by using Honeycomb and OpenTelemetry, mixed with automatic and manual instrumentation.| Honeycomb

It’s the goal of monitoring, logging, and observability tools to help the systems’ “stewards” make sense of signals. Learn more today.| Honeycomb

Patterns can introduce small but meaningful changes that compound over time. Learn how they help you leverage Honeycomb to its full extent.| Honeycomb

Should you test in production? This practice has gotten a bad rap despite the fact that we actually do it all the time. Here are some things to consider.| Honeycomb

When considering a Kubernetes migration, it’s imperative to assess the 'cost' in terms of resources and time - and why you want to migrate.| Honeycomb
Here's how to evaluate and track on-call health to make sure your on-call engineers aren't burning out from poor work/life balance.| Honeycomb

Engineers are often stuck between a rock and a hard place: address tech debt, or ship new features? Get VP of Engineering Emily's take.| Honeycomb
This post discusses the limitations of auto-instrumentation and how a CoPE can help teams overcome them with custom instrumentation.| Honeycomb

Linting provides a cheap feedback loop, requires little setup, and can capture risky patterns. See which linter we chose and why.| Honeycomb

Improve your team's engineering time and get fast feedback on service reliability with actionable Service Level Objectives (SLOs) from Honeycomb.| Honeycomb

With Honeycomb Metrics, use one interface to diagnose application application-level issues with observability & system-level issues with metrics. Learn more!| Honeycomb

Automatically compare every attribute on millions of requests to see which traces are tied to bad user experiences with Honeycomb's distributed tracing.| Honeycomb

Issues need to be discovered and resolved in the most efficient way possible. Enter: logs and log analytics!| Honeycomb

In part 4 of Nick Travaglini's CoPE series, Nick goes over the foundation of good observability: telemetry instrumentation.| Honeycomb

In part two of Lex's blog series, we find out: How did our chaos engineering test go? Did our customers experience downtime or latency?| Honeycomb

Ruthie goes over why pair programming is important and offers best practices to make a pairing session effective for both parties. Learn more!| Honeycomb

We recently performed a chaos engineering experiment where we destroyed 1/3 of the infrastructure in our prod environment. Find out why.| Honeycomb

In part 3 of Nick Travaglini's CoPE series, Nick goes over how to staff your CoPE with the right people to affect change in the organization.| Honeycomb

Alex explains distributed column stores, how they work, why they're so fast, and why that's a fundamental requirement for observability.| Honeycomb

In this post, we’ll elaborate on the 4 characteristics a CoPE should embody and why, and how to achieve that status.| Honeycomb

In this post, we’ll talk about the concept of a Center of Production Excellence and how such a group can bolster the greater organization.| Honeycomb

In the context of software development, we can draw several analogies from Jean Baudrillard's work on simulation theory. Let's dive in.| Honeycomb
See how Pax8 empowered their engineering teams to cultivate a culture of excellence while slashing 30% off their budget with Honeycomb.| Honeycomb

In this edition of our Authors' Cut webinar series, we go over what to build vs buy. Hint: it's not as black and white as it seems.| Honeycomb

Rethinking Honeycomb’s engineering ladder to include both scope and ownership in order to define career progression clearly.| Honeycomb
In this post, Charity goes over metrics and logs, and how to get the most value out of your tooling as possible with rising vendor costs.| Honeycomb
Observability is important to understand what’s happening in production, but carving out time to add instrumentation is daunting.| Honeycomb

“Sociotechnical” I learned this word from Liz Fong-Jones recently, and it immediately entered my daily lexicon. You know exactly what it means as soon as you hear it, and then you wonder how you...| Honeycomb
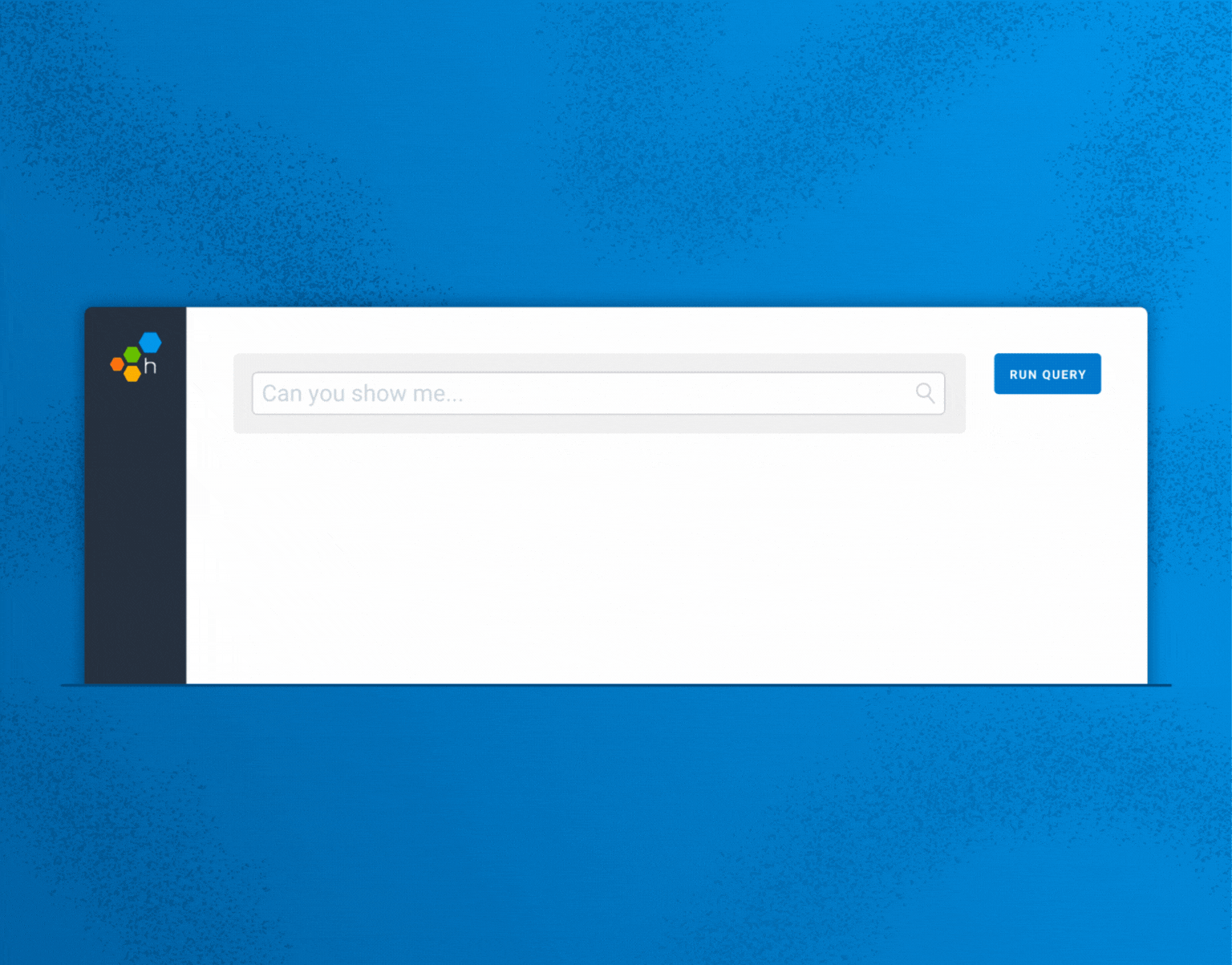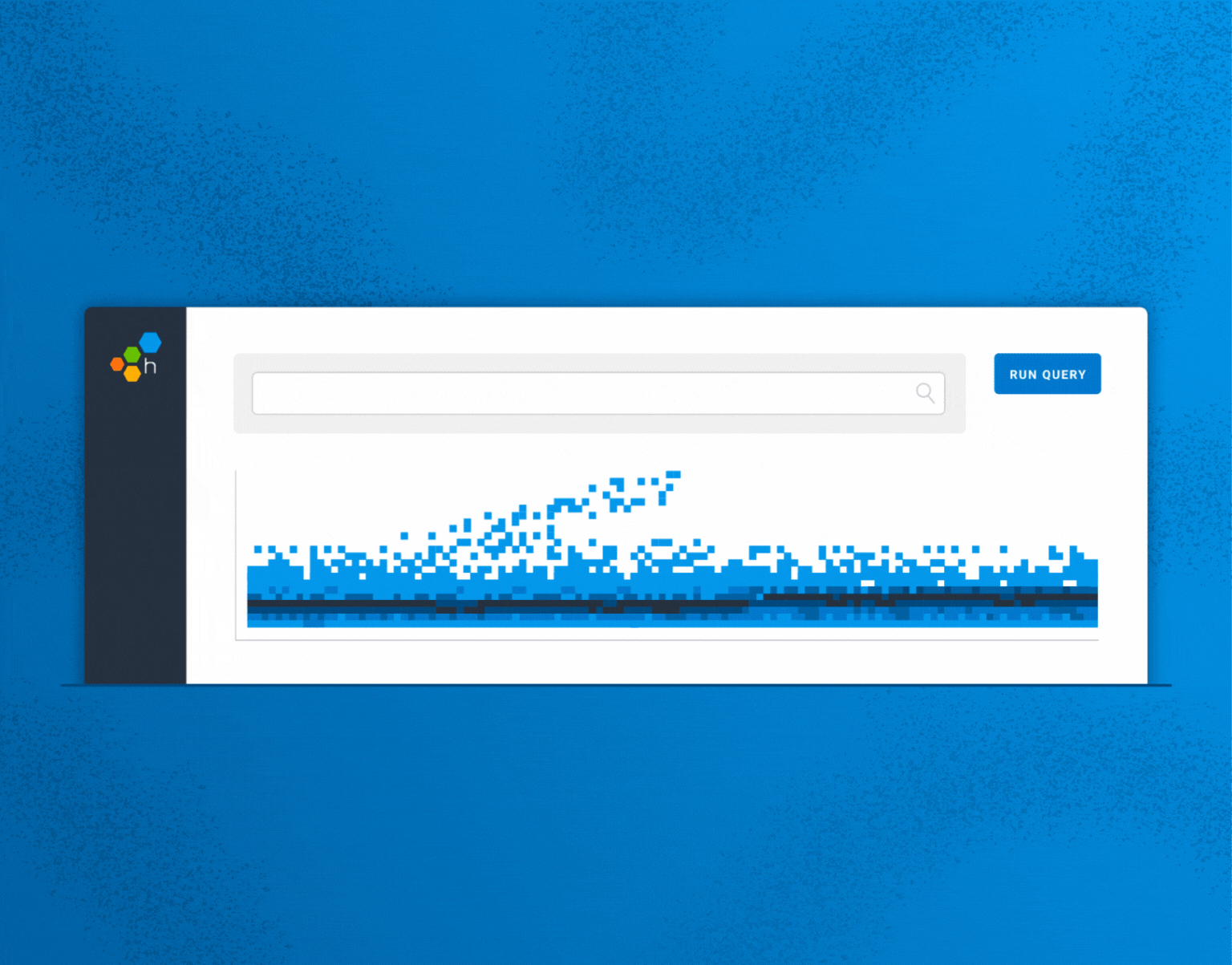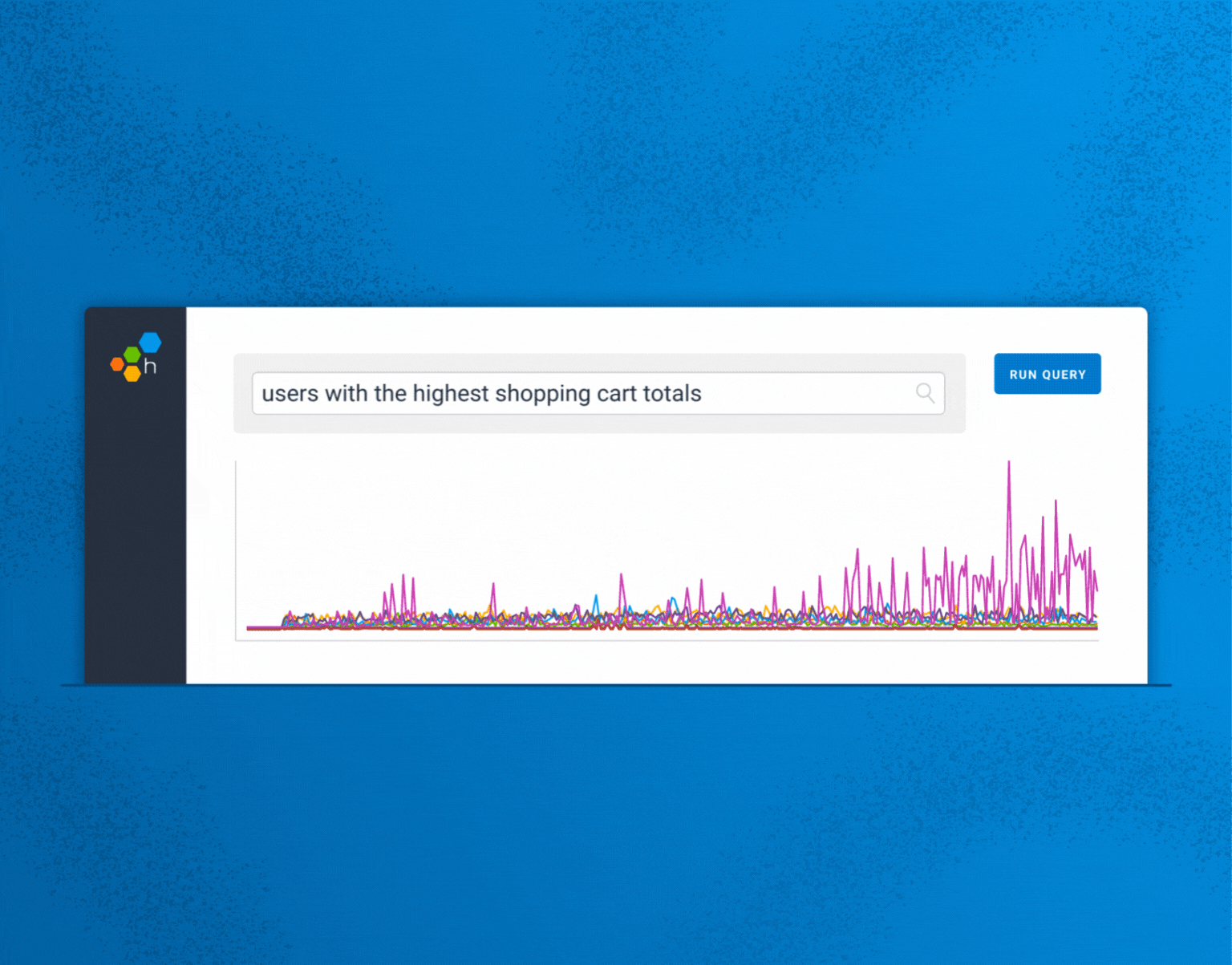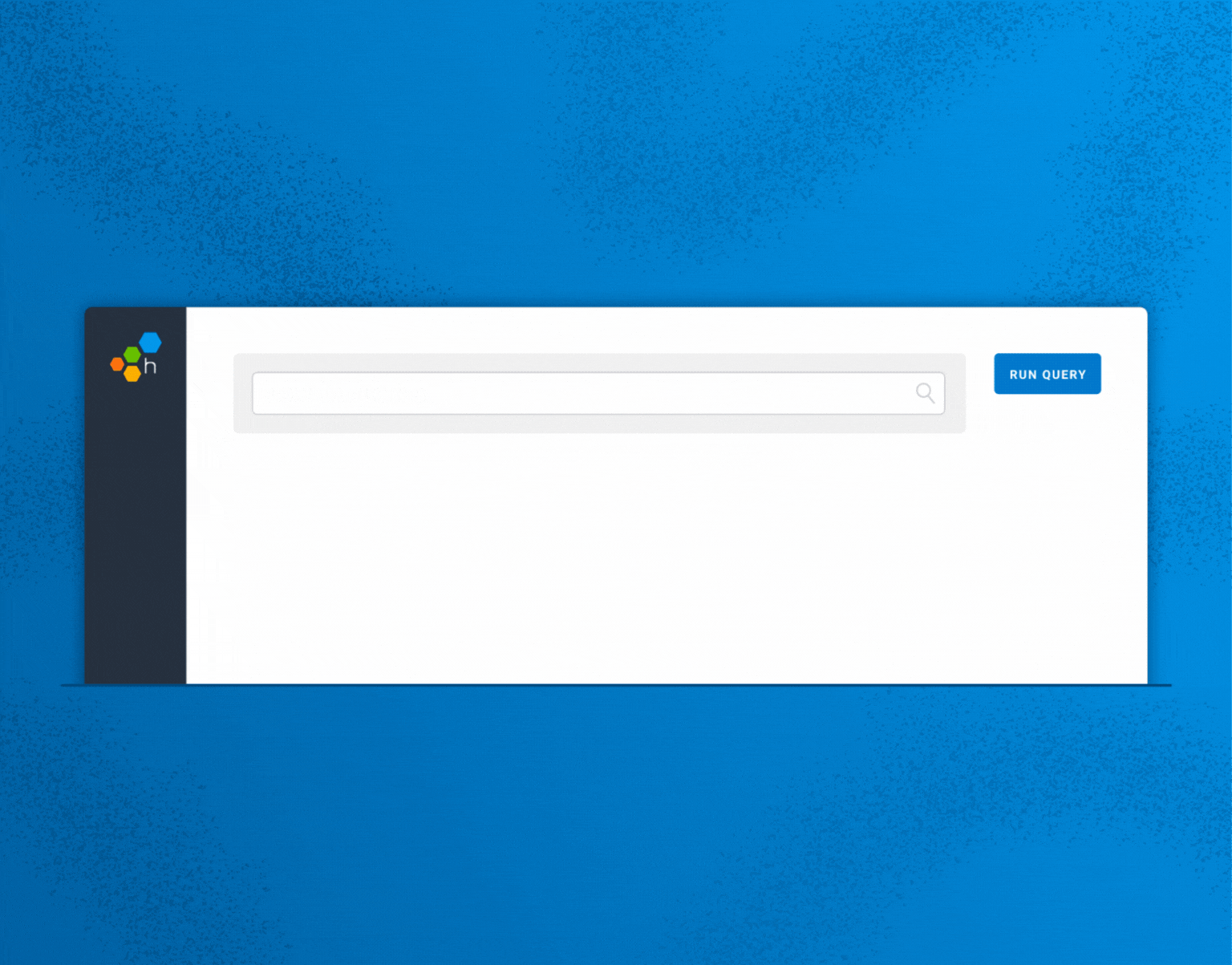
Announcing Query Assistant, the first introduction of AI into Honeycomb. With Query Assistant, you can describe/ask things in plain English.| Honeycomb
At Honeycomb, our mission is to give all software engineers the observability they need to improve their processes & delight their users. Learn more now!| Honeycomb

Getting Query Assistant from concept to feature diverted R&D & marketing resources. So, did investing in LLMs do what we wanted it to do?| Honeycomb

In January 2022, Honeycomb kicked off a one year experiment to have an employee board member. Join Alyson as she describes her experience.| Honeycomb

Honeycomb announces $50 million Series D funding round led by Headline, a Honeycomb backer since 2018. Learn more about the announcement.| Honeycomb

In this post, Phillip talks through the challenges & pitfalls of LLMs we faced when building our Query Assistant - and that you too may face.| Honeycomb

Find the Honeycomb plan that's right for your application. Create better outcomes for your customers and get started for free today.| Honeycomb

Platform engineering works cross-functionally with other SWE teams, optimizing their time to value and helping them own their code in prod.| Honeycomb
