Bring Cloud-grade governance and observability on-prem. Unified Stream Manager is GA in Confluent Platform 8.1 — your single view for hybrid Apache Kafka operations.| Confluent: Data in motion
Tableflow on Confluent Cloud now supports Delta Lake, Unity Catalog, and Azure (EA) for secure, governed, real-time analytics from Apache Kafka data - no ETL or custom pipelines required.| Confluent: Data in motion
Unlock real-time context for AI with Confluent’s Real-Time Context Engine. Evaluate, process, and serve trustworthy context continuously in Confluent Cloud.| Confluent: Data in motion
Transform real-time Kafka data into governed, AI-ready Delta Lake tables with Confluent Tableflow and Databricks Unity Catalog. Simplify pipelines, ensure governance, and unlock real-time analytics and AI.| Confluent: Data in motion
Explore updates from Confluent Cloud’s Q4 2025 release, including new capabilities and availability for Streaming Agents, new Real-Time Context Engine, and more.| Confluent: Data in motion
Bring cloud-native operations to private Kafka. Confluent Private Cloud adds a gateway, intelligent replication, and unified governance—without sacrificing control.| Confluent: Data in motion
Explore new Streaming Agents features — Agent Definition, Observability & Debugging, and access to Real-Time Context Engine — to build intelligent, context-aware AI on Confluent.| Confluent: Data in motion
Planning an Apache Kafka® migration? Learn how to estimate migration expenses, reduce costs, and compare self-managed vs managed real-time data platforms with expert insight.| Confluent: Data in motion
Explore how Confluent Cloud achieves 99.99% uptime and how you can architect for resilience, multi-region failover, and predictable performance.| Confluent: Data in motion
Explore the hidden costs of real-time streaming—compare infrastructure, ops, and ROI for Confluent Cloud and self-managed Apache Kafka®. Learn how autoscaling and governance lower TCO.| Confluent
Find technical tutorials, best practices, customer stories, and industry news related to Apache Kafka, Confluent, and real-time data technologies.| Confluent
Big news for developers! AWS Lambda's Kafka Event Source Mapping now supports Confluent Schema Registry. This update simplifies building event-driven applications.| Confluent: Data in motion
Cross-cloud Cluster Linking enables fully managed, offset-preserving Kafka replication across clouds for disaster recovery, data sharing, and analytics.| Confluent: Data in motion
Quickly troubleshoot Kafka Streams apps with new health metrics in Confluent Cloud. Spot bottlenecks, monitor RocksDB, and reduce MTTR—no extra code.| Confluent: Data in motion
At Current 2025 in New Orleans (Oct 29–30), developers, data engineers, operators, architects & tech execs unlock real-time data + AI insights.| Confluent: Data in motion
Learn how Confluent is reinforcing trust, including bolstering its security posture and compliance capabilities and providing detailed, transparent documentation.| Confluent: Data in motion
Learn how Confluent Tableflow and a shift-left approach solve data lake governance challenges—improving quality, trust, and analytics readiness.| Confluent: Data in motion
See how Confluent and its partner ecosystem are making it easier to use real-time data streaming as the fuel for your agentic AI and advanced analytics applications.| Confluent: Data in motion
Learn how to scale Kafka Streams applications to handle massive throughput with partitioning, scaling strategies, tuning, and monitoring.| Confluent: Data in motion
Choose the right Apache Kafka® multi-cluster replication pattern and run an audit-ready DR/HA program with lag SLOs, drills, and drift control.| Confluent: Data in motion
Learn how to handle data transformation, schema evolution, and security in Kafka Connect with best practices for consistency, enrichment, and format conversions.| Confluent
Confluent Cloud for Government is now FedRAMP 20x Low authorized—enabling agencies to securely modernize data streaming with cloud-native Kafka.| Confluent
Our new Tiered Storage feature allows for infinite Kafka data retention in Confluent Platform, improving scalability, cost efficiency, and ease of use.| Confluent
In our mission to design an elastically scaling, cloud-native Apache Kafka, we built Confluent Cloud to be an event-driven system with a seamless serverless experience.| Confluent
We’ll show you 12 major benefits of cloud-native data systems, reasons to move your tech to the cloud, and what to consider when building a truly cloud-native data platform.| Confluent
Confluent Cloud expands Apache Kafka's multi-tenancy features to provide a fully cloud-native solution with automated capacity planning, scaling, and cost-efficient, pay-as-you-go pricing.| Confluent
Stream, connect, process, and govern your data with a unified Data Streaming Platform built on the heritage of Apache Kafka® and Apache Flink®.| Confluent
This post covers how Apache Kafka and its Streams API are used for storing and processing all the articles ever published by The New York Times| Confluent
What we’ve done to evolve from cloud Kafka to Confluent Cloud, a data streaming platform that’s 10X better than Kafka in elasticity, storage, resiliency, and more.| Confluent
As mission-critical data infrastructure, Apache Kafka’s resiliency is non-negotiable. Learn how Confluent Cloud builds 10x higher resilience into its cloud-native services.| Confluent
Confluent unveils scalable, cost-effective event streaming with infinite data storage in Kafka, combining past and real-time events to unlock powerful new use cases.| Confluent
In Confluent Engineering, we focus on speed, scale, and performance. Here are some tips and best practices to help you run Apache Kafka in an optimized, cloud-native system.| Confluent
Kafka is horizontally scalable, but it's not enough. So we made Confluent Cloud 10x more elastic - 10x faster to scale up to GB/s or down to zero, easier to use, and cost-effective.| Confluent
Discover why hyperscaler-hosted Apache Kafka® services drive up costs with hidden expenses and ops overhead—and how Confluent Cloud cuts infra costs by 60% or more.| Confluent
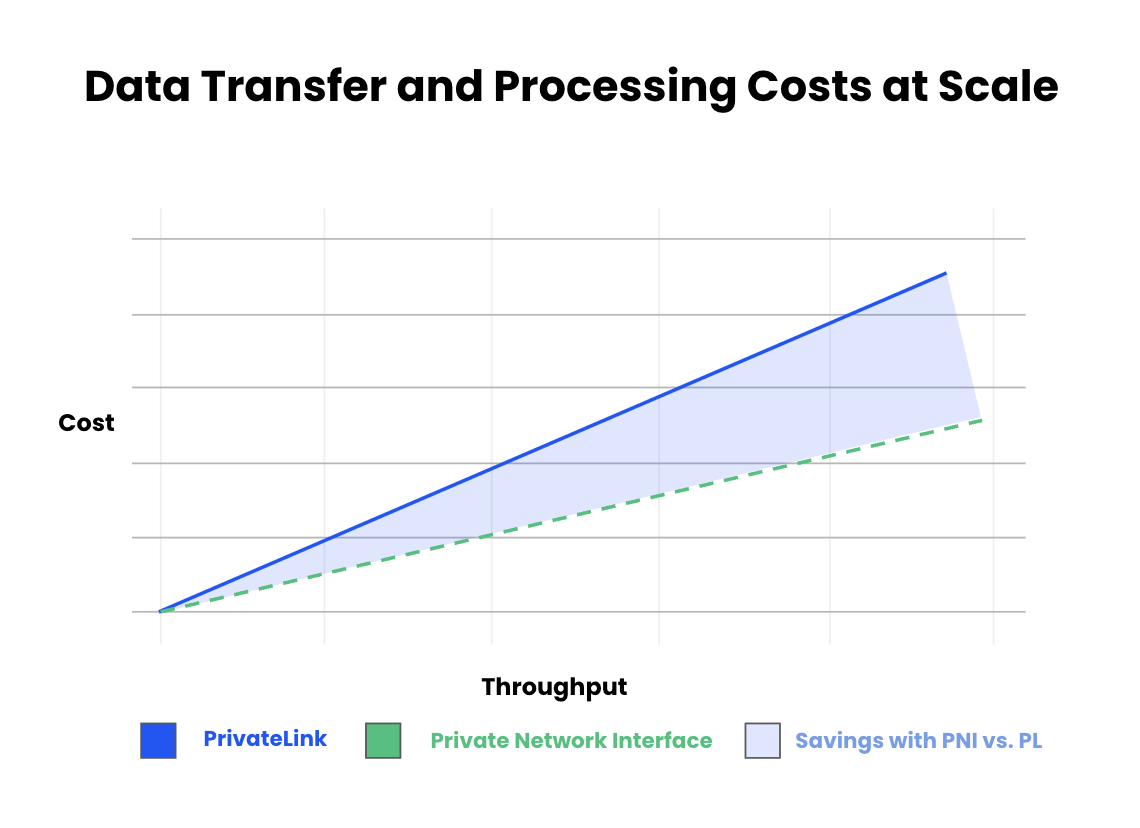
Discover how Confluent’s new Private Network Interface (PNI) on AWS delivers secure, low-latency Kafka connectivity while cutting networking costs by up to 50%.| Confluent
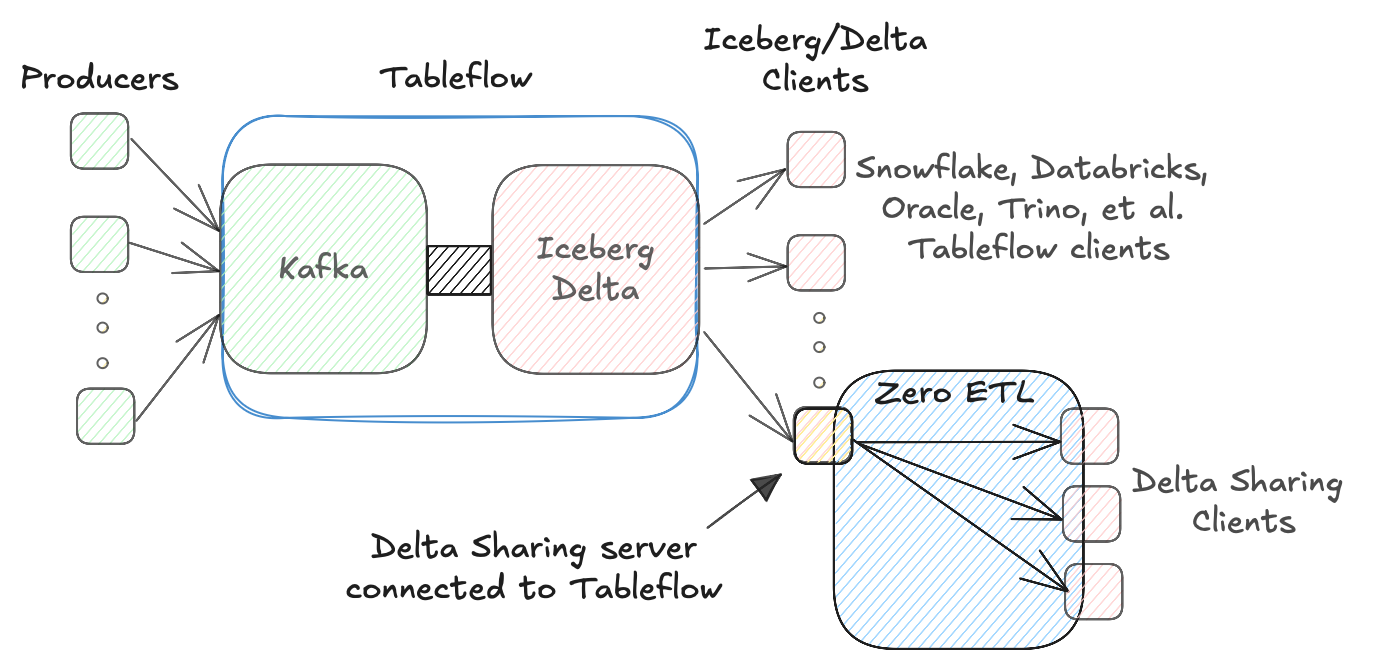
Confluent Tableflow unifies operational and analytical data by integrating Kafka with Zero ETL, leveraging open table formats such as Iceberg and Delta Lake.| Confluent
Confluent Platform 8.0 brings client-side field level encryption (GA), removes ZooKeeper, adds management for Flink with Control Center, and more.| Confluent
Low utilization and operational complexity dramatically increases Kafka costs, so we reinvented Kafka as a cloud-native and complete service to reduce costs for thousands of businesses at any scale.| Confluent
Quantifying the cost of running Kafka is challenging. In part 2, learn how to calculate Kafka costs stemming from the development and operations personnel needed to self-manage clusters.| Confluent
With infinite data retention comes new challenges for durability and safety. Learn how Confluent monitors, audits, and protects Kafka data on a massive scale to uphold our durability SLA.| Confluent
How Confluent built Intelligent Storage, for 10x more scalable and elastic Kafka storage with infinite retention, max cluster uptime, and zero operational burdens.| Confluent
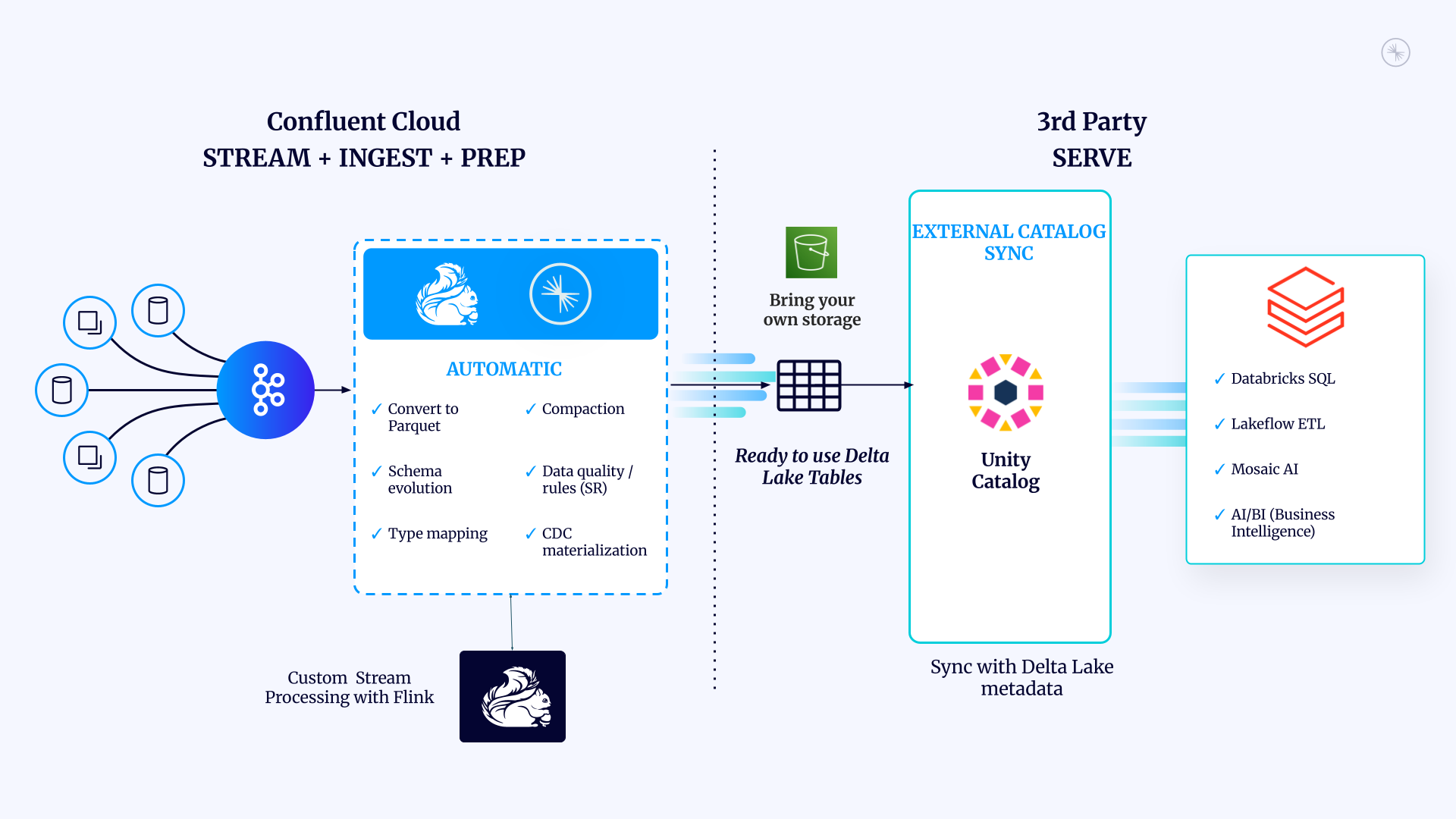
Explore how Confluent’s latest Tableflow update connects Databricks Unity Catalog with Delta Lake to simplify real-time lakehouse data access.| Confluent
Quantifying the cost of running Kafka is challenging. In part 1, learn how to calculate Kafka costs stemming from infrastructure and the impact networking has on your cloud bill.| Confluent
Confluent's data governance solution ensures the availability, integrity, and security of data streams through any cloud. Easily leverage real-time data on enterprise scale.| Confluent
Seamlessly integrate Apache Kafka data into your lakehouse as Apache Iceberg or Delta Lake tables, bridging the operational and analytical divide, with Tableflow. Read more in our blog post.| Confluent
Introducing fully managed Apache Kafka® + Flink for the most robust, cloud-native data streaming platform with stream processing, integration, and streaming analytics in one.| Confluent