Over the past few years large language models (LLMs) have shown remarkable capabilities on various tasks, such as reasoning, knowledge retrieval, and generation. However, it is still challenging for LLMs to solve tasks that require long inputs, because they typically have limitations on input length, and hence, cannot utilize the full context. This issue hinders long context tasks, such as long summarization, question answering, and code completion.| research.google
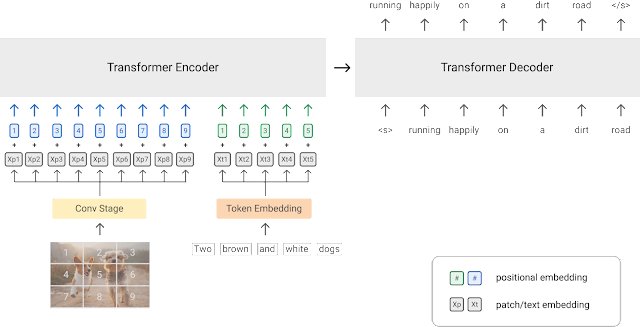
Posted by Zirui Wang, Student Researcher and Yuan Cao, Research Scientist, Google Research, Brain Team Vision-language modeling grounds language un...| research.google
Wearable devices that measure physiological and behavioral signals have become commonplace. There is growing evidence that these devices can have a meaningful impact promoting healthy behaviors, detecting diseases, and improving the design and implementation of treatments. These devices generate vast amounts of continuous, longitudinal, and multimodal data. However, raw data from signals like electrodermal activity or accelerometer values are difficult for consumers and experts to interpret. ...| research.google
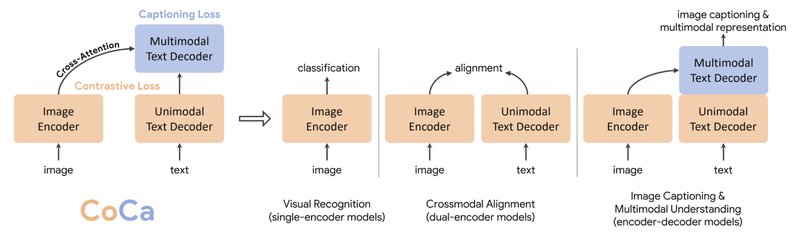
Posted by Zirui Wang and Jiahui Yu, Research Scientists, Google Research, Brain Team Oftentimes, machine learning (ML) model developers begin their...| research.google
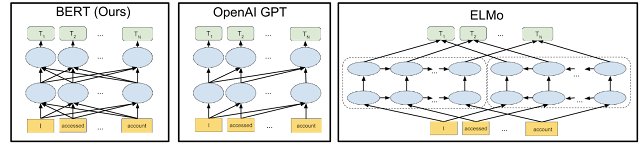
Posted by Jacob Devlin and Ming-Wei Chang, Research Scientists, Google AI Language One of the biggest challenges in natural language processing (NL...| research.google
Posted by Danny Driess, Student Researcher, and Pete Florence, Research Scientist, Robotics at Google Recent years have seen tremendous advances ac...| research.google
More and more products and services are being deployed on the web, and this presents new challenges and opportunities for measurement of user experience on a large scale. There is a strong need for user-centered metrics for web applications, which can be used to measure progress towards key goals, and drive product decisions. In this note, we describe the HEART framework for user-centered metrics, as well as a process for mapping product goals to metrics. We include practical examples of how ...| research.google
The Web has millions of datasets, and that number continues to grow rapidly. Many of these datasets are intricately connected through complex relationships. Google Dataset Search helps users navigate this landscape by indexing metadata from diverse sources (e.g., government, academic, and institutional repositories) and allowing users to search for datasets based on topics, formats, publication dates, and more. Understanding the relationships between datasets, particularly from the perspectiv...| research.google
Generative AI has fundamentally reshaped our expectations of technology. We've seen the power of large-scale cloud-based models to create, reason and assist in incredible ways. However, the next great technological leap isn't just about making cloud models bigger; it's about embedding their intelligence directly into our immediate, personal environment. For AI to be truly assistive — proactively helping us navigate our day, translating conversations in real-time, or understanding our physic...| research.google
Posted Keerthana Gopalakrishnan and Kanishka Rao, Google Research, Robotics at Google Major recent advances in multiple subfields of machine learni...| research.google
Dremel is a scalable, interactive ad-hoc query system for analysis of read-only nested data. By combining multi-level execution trees and columnar data layout, it is capable of running aggregation queries over trillion-row tables in seconds. The system scales to thousands of CPUs and petabytes of data, and has thousands of users at Google. In this paper, we describe the architecture and implementation of Dremel, and explain how it complements MapReduce-based computing. We present a novel colu...| research.google
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, suc...| research.google
The efficacy of machine learning (ML) models depends on both algorithms and data. Training data defines what we want our models to learn, and testing data provides the means by which empirical progress is measured. Benchmark datasets such as SQuAD, GLUE, and ImageNet define the entire world within which models exist and operate, yet research continues to focus on critiquing and improving the models, e.g., via shared-task challenges or Kaggle contests, rather than critiquing and improving the...| research.google
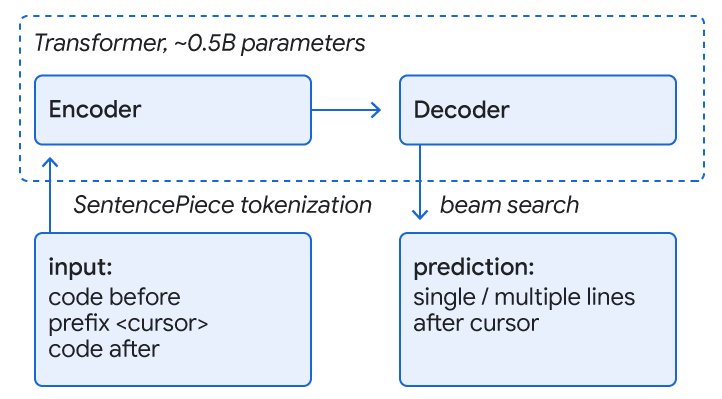
Posted by Maxim Tabachnyk, Staff Software Engineer and Stoyan Nikolov, Senior Engineering Manager, Google Research Update — 2022/09/06: This post...| research.google
Posted by Joshua Bloch, Software EngineerI remember vividly Jon Bentley's first Algorithms lecture at CMU, where he asked all of us incoming Ph.D. ...| research.google
Predictive models trained on large datasets with sophisticated machine learning (ML) algorithms are widely used throughout industry and academia. Models trained with differentially private ML algorithms provide users with a strong, mathematically rigorous guarantee that details about their personal data will not be revealed by the model or its predictions.| research.google
Posted by Krishna Giri Narra, Software Engineer, Google, and Chiyuan Zhang, Research Scientist, Google Research Ad technology providers widely use ...| research.google
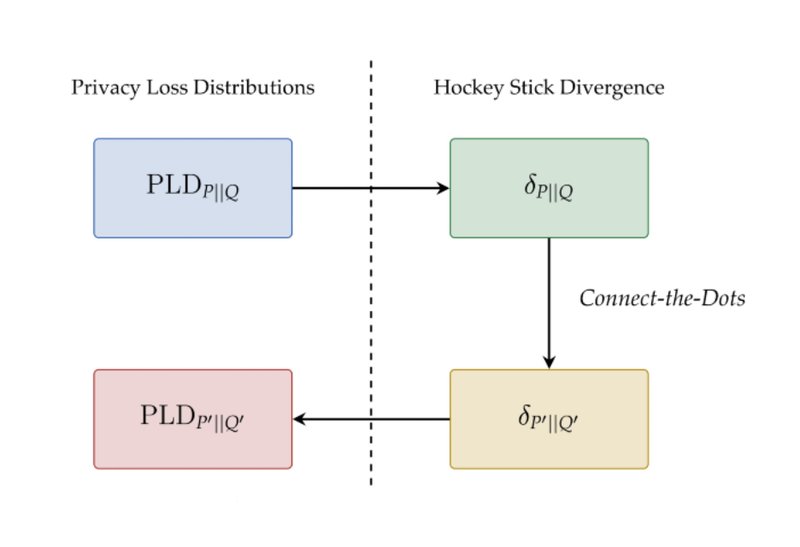
Posted by Pritish Kamath and Pasin Manurangsi, Research Scientists, Google Research Differential privacy (DP) is an approach that enables data anal...| research.google
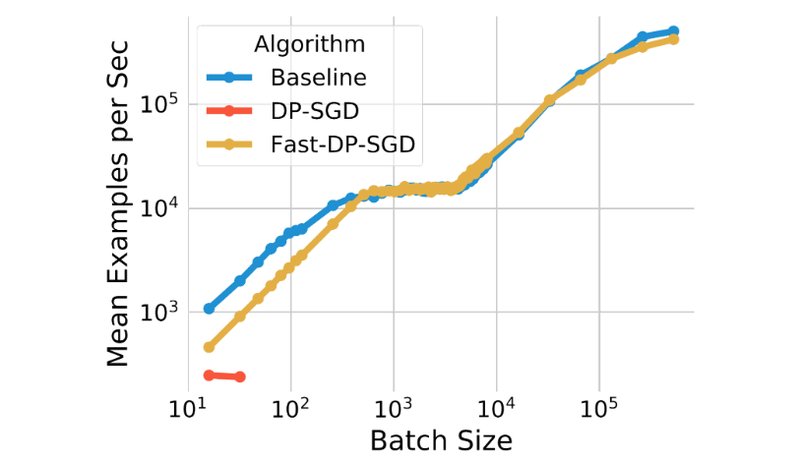
In today's world, machine learning (ML) models are becoming more ubiquitous. While they provide great utility, such models may sometimes accidentally remember sensitive information from their training data. Differential privacy (DP) offers a rigorous mathematical framework to protect user privacy by injecting "noise" during the model training procedure, making it harder for the model to remember information unique to individual data points. It is desirable to have techniques that provide the ...| research.google
Textbooks are a cornerstone of education, but they have a fundamental limitation: they are a one-size-fits-all medium. The manual creation of textbooks demands significant human effort, and as a result they lack alternative perspectives, multiple formats and tailored variations that can make learning more effective and engaging. At Google, we’re exploring how we can use generative AI (GenAI) to automatically generate alternative representations or personalized examples, while preserving the...| research.google
As AI becomes more integrated into our lives, building it with privacy at its core is a critical frontier for the field. Differential privacy (DP) offers a mathematically robust solution by adding calibrated noise to prevent memorization. However, applying DP to LLMs introduces trade-offs. Understanding these trade-offs is crucial. Applying DP noise alters traditional scaling laws — rules describing performance dynamics — by reducing training stability (the model's ability to learn consis...| research.google
Discover Google Research. We publish research papers across a wide range of domains and share our latest developments in AI and science research.| research.google
Classifying unsafe ad content has proven an enticing problem space for leveraging large language models (LLMs). The inherent complexity involved in identifying policy-violating content demands solutions capable of deep contextual and cultural understanding, areas of relative strength for LLMs over traditional machine learning systems. But fine-tuning LLMs for such complex tasks requires high-fidelity training data that is difficult and expensive to curate at the necessary quality and scale. S...| research.google
For AI models to perform well on diverse medical tasks and to meaningfully assist in clinician, researcher and patient workflows (like generating radiology reports or summarizing health information), they often require advanced reasoning and the ability to utilize specialized, up-to-date medical knowledge. In addition, strong performance requires models to move beyond short passages of text to understand complex multimodal data, including images, videos, and the extensive length and breadth o...| research.google
Wearable devices, from smartwatches to fitness trackers, have become ubiquitous, continuously capturing a rich stream of data about our lives. They record our heart rate, count our steps, track our fitness and sleep, and much more. This deluge of information holds immense potential for personalized health and wellness. However, while we can easily see what our body is doing (e.g., a heart rate of 150 bpm), the crucial context of why (say, "a brisk uphill run" vs. "a stressful public speaking ...| research.google
Neural embedding models have become a cornerstone of modern information retrieval (IR). Given a query from a user (e.g., “How tall is Mt Everest?”), the goal of IR is to find information relevant to the query from a very large collection of data (e.g., the billions of documents, images, or videos on the Web). Embedding models transform each datapoint into a single-vector “embedding”, such that semantically similar datapoints are transformed into mathematically similar vectors. The emb...| research.google
Many real-world planning tasks involve both harder “quantitative” constraints (e.g., budgets or scheduling requirements) and softer “qualitative” objectives (e.g., user preferences expressed in natural language). Consider someone planning a week-long vacation. Typically, this planning would be subject to various clearly quantifiable constraints, such as budget, travel logistics, and visiting attractions only when they are open, in addition to a number of constraints based on personal ...| research.google
The digital age offers ever growing access to vast amounts of knowledge, yet much remains locked behind complex language and specialist jargon. While complexity is often necessary in expert discourse, it can become a barrier when users need to understand information critical to their lives, such as navigating health information, understanding legal language, or grasping financial details. Tools that let users produce a simplified version of complex text that they encounter online can empower ...| research.google
The machine learning community has consistently found that while modern machine learning (ML) models are powerful, they often need to be fine-tuned on domain-specific data to maximize performance. This can be problematic or even impossible, as informative data is often privacy-sensitive. Differential privacy (DP) allows us to train ML models while rigorously guaranteeing that the learned model respects the privacy of its training data, by injecting noise into the training process.| research.google
In the pursuit of scientific advances, researchers combine ingenuity and creativity with insight and expertise grounded in literature to generate novel and viable research directions and to guide the exploration that follows. In many fields, this presents a breadth and depth conundrum, since it is challenging to navigate the rapid growth in the rate of scientific publications while integrating insights from unfamiliar domains. Yet overcoming such challenges is critical, as evidenced by the ma...| research.google
AI models are increasingly applied in high-stakes domains like health and conservation. Data quality carries an elevated significance in high-stakes AI due to its heightened downstream impact, impacting predictions like cancer detection, wildlife poaching, and loan allocations. Paradoxically, data is the most under-valued and de-glamorised aspect of AI. In this paper, we report on data practices in high-stakes AI, from interviews with 53 AI practitioners in India, East and West African countr...| research.google
Google's Borg system is a cluster manager that runs hundreds of thousands of jobs, from many thousands of different applications, across a number of clusters each with up to tens of thousands of machines. | research.google
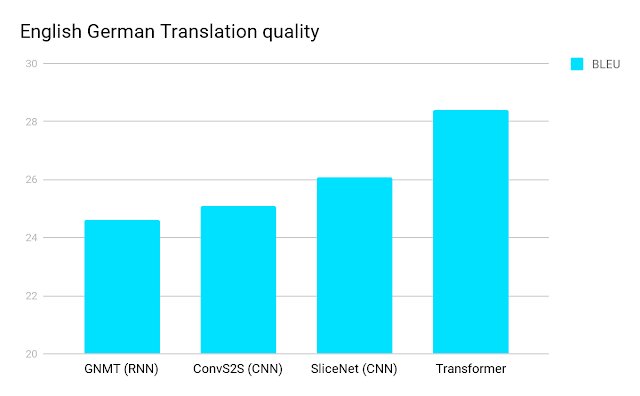
Posted by Jakob Uszkoreit, Software Engineer, Natural Language Understanding Neural networks, in particular recurrent neural networks (RNNs), are n...| research.google
While quantum processors in the noisy intermediate-scale quantum (NISQ) era demonstrate remarkable potential, they are susceptible to errors, i.e., noise, that accumulate over time and limit the number of qubits they can effectively handle. This poses a fundamental question: despite the limitations of noise in quantum computing, can these systems still provide practical value and outperform classical supercomputers in specific applications?| research.google
Quantum computers offer promising applications in many fields, ranging from chemistry and drug discovery to optimization and cryptography. Most of these applications require billions if not trillions of operations to execute reliably — not much compared to what your web browser is doing right now. But quantum information is delicate, and even state-of-the-art quantum devices will typically experience at least one failure in every thousand operations. To achieve their potential, performance ...| research.google
SQL has been extremely successful as the de facto standard language for working with data. Virtually all mainstream database-like systems use SQL as their primary query language. But SQL is an old language with significant design problems, making it difficult to learn, difficult to use, and difficult to extend. Many have observed these challenges with SQL, and proposed solutions involving new languages. New language adoption is a significant obstacle for users, and none of the potential repla...| research.google
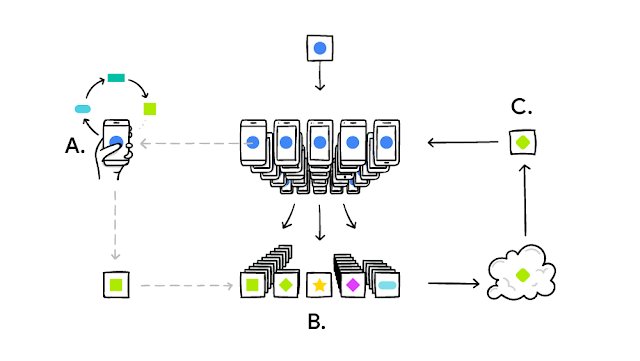
Posted by Brendan McMahan and Daniel Ramage, Research ScientistsStandard machine learning approaches require centralizing the training data on one ...| research.google
Posted by Jacob Devlin and Ming-Wei Chang, Research Scientists, Google AI Language One of the biggest challenges in natural language processing (NL...| research.google