Setting up Spark locally is not easy! Especially if you are simultaneously trying to learn Spark. If you > Don't know how to start working with Spark locally > Don't know what the recommended tools are to work with Spark (like which IDE or data storage table formats) > Try and try, and then give up, only to end up trying to use one of the cloud providers or give up altogether. This post is for you! You can have a fully functioning local Spark development environment with all the bells and whi...| www.startdataengineering.com
1. Introduction 2. Joins & Group bys are two of the most commonly used operations in data warehousing 2.1. Joins are used to create denormalized dimension tables & to enrich fact tables with dimensions for reporting 2.1.1. When to use joins 2.1.2. How to use joins 2.1.3. Things to watch out for when joining 2.2. Group bys are the cornerstone of reporting 2.| Posts on Start Data Engineering
1. Introduction 2. CTE for short clean code & temp tables for re-usability 2.1. CTEs make medium-complex SQL easy to understand 2.2. Temp table enables you to reuse logic multiple times in a session 2.3. Performance depends on the execution engine 3. Conclusion 4. Recommended reading 1. Introduction As a data engineer, CTEs(Common Table Expression) are one of the best techniques you can use to improve query readability.| Posts on Start Data Engineering
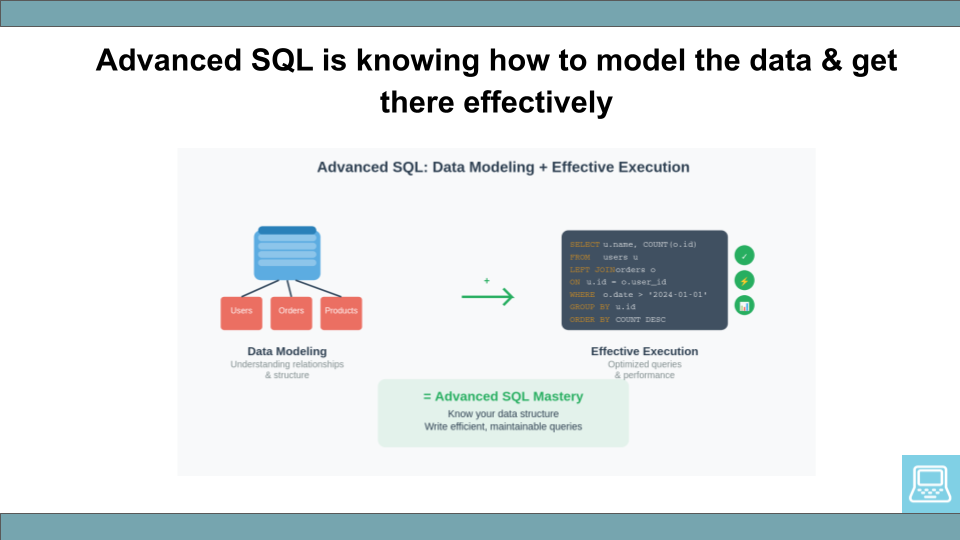
Most data engineering job descriptions these days expect "knowledge of advanced SQL," but ask any data engineer that question, and you will get a different answer every time. Are you > Frustrated that "advanced SQL" ebooks or Udemy courses aren't really all that advanced! > Wondering where you can learn more about writing advanced SQL queries? > Frustrated by job descriptions requiring "Advanced SQL", but no one really knows what that means? It can be especially demotivating when seeking a ...| www.startdataengineering.com
Every data engineering interview includes a SQL round. If you are: > Worried about job descriptions asking for advanced SQL, but you are not sure what advanced SQL means for an interview > Having anxiety about being unable to get a job > Frustrated with online SQL courses teaching the basic dialects, but not a step-by-step approach to problem solving If so, this post is for you. Imagine being able to dissect any SQL problem and make the interviewer say, I need this person on my team. That is ...| www.startdataengineering.com
Extracting data is one of the critical skills for data engineering. If you have wondered > How to get started for the first time extracting data from an API > What are some good resources to learn API data extraction? > If there are any recommendations, guides, videos, etc., for dealing with APIs in Python > Which Python library to use to extract data from an API > I don't know what I don't know. Am I missing any libraries? Then this post is for you. Imagine being able to mentally visualize h...| www.startdataengineering.com
1. Introduction 1.1. Code and setup 2. MERGE INTO is used to UPDATE/DELETE/INSERT rows into a target table based on data in the source table 3. SCD2 table pipeline: INSERT new data, UPDATE existing data, and DELETE stale data 3.1. Source includes 2 versions of upstream customer data: one for insert and the other for update 3.2. Updates to the target table 4.| Start Data Engineering
Over the past decade, every department has wanted to be data-driven, and data engineering teams are under more pressure than ever. If you have been an engineer for over a few years, you would have seen your world change from a 'well-planned data model' to a 'dump everything in S3 and get some data for the end-user'. Data engineers are under a lot of stress caused by : > The Business is becoming too complex, and every department wants to become data-driven; thus, expectations from the data tea...| www.startdataengineering.com
If you have worked at a company that moves fast (or claims to), you've inevitably had to deal with your pipelines breaking because the upstream team decided to change the data schema! If you are > Frequently in meetings, fixing pipeline issues due to schema changes > Stressed, unable to deliver quality work, always in a hurry to put out the next fire > Working with teams who have to prioritize speed over everything This post is for you. Constantly dealing with broken pipelines due to upstream...| www.startdataengineering.com
Whether you are setting up visual studio code for your colleagues or want to improve your workflow, tons of extensions are available. If you have wondered > What are the best visual studio code extensions for data engineers? > How do I share my visual studio code environment with my colleagues? > How does Visual Studio code user/workspace/devcontainers/profiles work? Then this post is for you! Imagine being able to quickly set up Visual Studio Code on any laptop exactly how you want it. You w...| www.startdataengineering.com
As a data engineer, you would have spent hours trying to figure out the right place to make a change in your repository—I know I have. > You think, "Why is it so difficult to make a simple change?". > You push a simple change (with tests, by the way), and suddenly, production issues start popping up! > Dealing with on-call issues when your repository is spaghetti code with multiple layers of abstracted logic is a special hell that makes data engineers age in dog years! > Messy code leads to...| www.startdataengineering.com
If you've been in the data space long enough, you would have come across really long SQL scripts that someone had written years ago. However, no one dares to touch them, as they may be powering some important part of the data pipeline, and everyone is scared of accidentally breaking them. If you feel > Rough SQL is a good place to start, but it cannot scale after a certain limit > That dogmatic KISS approach leads to unmaintainable systems > The simplest solution that takes the shortest time ...| www.startdataengineering.com
If you’ve worked on a data team, you’ve likely encountered situations where multiple teams define metrics in slightly different ways, leaving you to untangle why discrepancies exist. The root cause of these metric deviations often stems from rapid data utilization without prioritizing long-term maintainability. Imagine this common scenario: a company hires its first data professional, who writes an ad-hoc SQL query to compute a metric. Over time, multiple teams build their own datasets us...| www.startdataengineering.com
System design interviews are usually vague and depend on you (as the interviewee) to guide the interviewer. If you are thinking: How do I prepare for data engineering system design interviews? I struggle to think of questions you would ask in a system design interview for data engineering; I don't have enough interview experience to know what companies ask. Is data engineering "system design" more than choosing between technologies like Spark and Airflow? This post is for you! Imagine being a...| www.startdataengineering.com
If your company has multiple dbt projects, you would have had to use code cross projects. Creating cross-project dependencies is not straightforward in a SQL templating system like dbt. If you are wondering: How to use seed data defined in one dbt project in another, How dbt packages work under the hood, Caveats to be aware of when using assets cross-projects, etc. This post is for you. In this post, we will go over how to use packaging in dbt to reuse assets and how packaging works under the...| www.startdataengineering.com
1. Introduction 2. Analytical databases aggregate large amounts of data 3. Most platforms enable you to do the same thing but have different strengths 3.1. Understand how the platforms process data 3.1.1. A compute engine is a system that transforms data 3.1.2. Metadata catalog stores information about datasets 3.1.3. Data platform support for SQL, Dataframe, and Dataset APIs 3.1.4. Query planner turns your code into concrete execution steps 3.| Posts on Start Data Engineering
Introduction Setup SQL tips 1. Handy functions for common data processing scenarios 1.1. Need to filter on WINDOW function without CTE/Subquery use QUALIFY 1.2. Need the first/last row in a partition, use DISTINCT ON 1.3. STRUCT data types are sorted based on their keys from left to right 1.4. Get the first/last element with ROW_NUMBER() + QUALIFY 1.5. Check if at least one or all boolean values are true with BOOL_OR & BOOL_AND respectively 1.| Start Data Engineering
1. Introduction 2. Code & Data 3. Using nested data types effectively 3.1. Use STRUCT for one-to-one & hierarchical relationships 3.2. Use ARRAY[STRUCT] for one-to-many relationships 3.3. Using nested data types in data processing 3.3.1. STRUCT enables more straightforward data schema and data access 3.3.2. Nested data types can be sorted 3.3.3. UNNEST ARRAY to rows and GROUP rows to ARRAY 3.| Posts on Start Data Engineering
1. Introduction 2. Steps to decide on a data project to build 2.1. Objective 2.2. Research 2.2.1. Job description 2.2.2. Potential referral/hiring manager research 2.2.3. Company research 2.3. Data 2.3.1. Dataset Search 2.3.2. Generate fake data 2.4. Outcome 2.4.1. Visualization 2.5. Presentation 3. Conclusion 4. Read these 1.| Posts on Start Data Engineering
1. Introduction 2. Setup 3. Parts of data engineering 3.1. Requirements 3.1.1. Understand input datasets available 3.1.2. Define what the output dataset will look like 3.1.3. Define SLAs so stakeholders know what to expect 3.1.4. Define checks to ensure the output dataset is usable 3.2. Identify what tool to use to process data 3.3. Data flow architecture 3.| Start Data Engineering
If you are trying to break into (or land a new) data engineering job, you will inevitably encounter a slew of data engineering tools. The list of tools/frameworks to know can be overwhelming. If you are wondering > What are the parts of data engineering? > Which parts of data engineering are the most important? > Which popular tools should you focus your learning on? > How to build portfolio projects? Then this post is for you. This post will review the critical components of data engineering...| www.startdataengineering.com
Preparing for data engineering interviews can be stressful. There are so many things to learn. In this 'Data Engineering Interview Series', you will learn how to crack each section of the data engineering interview. If you have felt > That you need to practice 100s of Leetcode questions to crack the data engineering interview > That you have no idea where/how to start preparing for the data structures and algorithms interview > That you are not good enough to crack the data structures and alg...| www.startdataengineering.com
Data quality checks are critical for any production pipeline. While there are many ways to implement data quality checks, the greatexpectations library is one of the popular ones. If you have wondered 1. How can you effectively use the greatexpectations library? 2. Why is the greatexpectations library so complex? 3. Why is the greatexpectations library so clunky and has many moving pieces? Then this post is for you. In this post, we will go over the key concepts you’ll need to get up and ru...| www.startdataengineering.com
Data quality is such a broad topic. There are many ways to check the data quality of a dataset, but knowing what checks to run and when can be confusing and unclear. In this post, we will review the main types of data quality checks, where to use them, and what to do if a DQ check fails. By the end of this post, you will not only have a clear understanding of the different types of DQ checks and when to use them, but you'll also be equipped with the knowledge to prioritize which DQ checks to ...| www.startdataengineering.com
Do you use SQL or Python for data processing? Every data engineer will have their preference. Some will swear by Python, stating that it's a Turing-complete language. At the same time, the SQL camp will restate its performance, ease of understanding, etc. Not using the right tool for the job can lead to hard-to-maintain code and sleepless nights! Using the right tool for the job can help you progress the career ladder, but every advice online seems to be 'Just use Python' or 'Just use SQL.' U...| www.startdataengineering.com
Are you a data engineer(or new to data space) wondering why one may need to use Apache Airflow vs. just using cron? Does Apache Airflow feel like an over-optimized solution for a simple problem? Then this post is for you. Understanding the critical features necessary for a data pipelining system will ensure that your output is high quality! Imagine knowing exactly what a complex orchestration system brings to the table; you can make the right tradeoffs for your data architecture. This post wi...| www.startdataengineering.com
An in-significant data project portfolio can help set you apart from the run-of-a-mill candidate. Projects show that you are someone who can learn and adapt. Your portfolio informs a potential employer about your ability to continually learn, your knowledge of data pipeline best practices, and your genuine interest in the data field. Most importantly, it gives you the confidence to pick up new tools and build data pipelines from scratch. But setting up data infrastructure, with coding best pr...| www.startdataengineering.com
You know Python is essential for a data engineer. Does anyone know how much one should learn to become a data engineer? When you're in an interview with a hiring manager, how can you effectively demonstrate your Python proficiency? Imagine knowing exactly how to build resilient and stable data pipelines (using any language). Knowing the foundational ideas for data processing will ensure you can quickly adapt to the ever-changing tools landscape. In this post, we will review the concepts you n...| www.startdataengineering.com
Imagine working for a company that processes a few GBs of data every day but spends hours configuring/debugging large-scale data processing systems! Whoever set up the data infrastructure copied it from some blog/talk by big tech. Now, the responsibility of managing the data team's expenses has fallen on your shoulders. You're under pressure to scrutinize every system expense, no matter how small, in an effort to save some money for the organization. It can be frustrating when data vendors ch...| www.startdataengineering.com
You want to democratize your company's data to a larger part of your organization. However, trying to teach SQL to nontechnical stakeholders has not gone well. Stakeholders will always choose the easiest way to get what they want: by writing bad queries or opening an ad-hoc request for a data engineer to handle. You hope stakeholders will recognize the power of SQL, but it can be disappointing and frustrating to know that most people do not care about learning SQL but only about getting what ...| www.startdataengineering.com
Have you worked on Snowflake SQL written without concern for maintainability or performance? Most data projects are built without consideration of warehouse costs! You may be a new data engineer brought in to optimize Snowflake usage or suddenly thrust into a cost-reduction project. While the Snowflake contracts are signed by management without your consultation, the cost reduction initiative will fall on you, the data engineer! On top of that, you will be held responsible for skyrocketing co...| www.startdataengineering.com
Working on a large codebase without any tests can be nerve-wracking. One wrong line of code or an in-conspicuous library update can bring down your whole production pipeline! Data pipelines start simple, so engineers skip tests, but the complexity increases rapidly after a while, and the lack of tests can grind down your feature delivery speed. It can be especially tricky to start testing if you are working on a large legacy codebase with few to no tests. In long-running data pipelines, bad c...| www.startdataengineering.com
Docker can be overwhelming to start with. Most data projects use Docker to set up the data infrastructure locally (and often in production as well). Setting up data tools locally without Docker is (usually)a nightmare! The official Docker documentation, while extremely instructive, does not provide a simple guide covering the basics for setting up data infrastructure. With a good understanding of data components and their interactions combined with some networking knowledge, you can easily se...| www.startdataengineering.com
Imagine this scenario: You are on call when suddenly an obscure alert pops up. It just says that your pipeline failed but has no other information. The pipelines you inherited (or didn't build) seem like impenetrable black boxes. When they break, it's a mystery—why did it happen? Where did it go wrong? The feeling is palpable: frustration and anxiety mount as you scramble to resolve the issue swiftly. It's a common struggle, especially for new team members who have yet to unravel the system...| www.startdataengineering.com
Are you part of an under-resourced team where adding time-saving dbt (data build tool) features take a back seat to delivering new datasets? Do you want to incorporate time (& money) saving dbt processes but need more time? While focussing on delivery may help in the short term, the delivery speed will suffer without proper workflow! A good workflow will save time, prevent bad data, and ensure high development speed! Imagine the time (& mental pressure) savings if you didn't have to validate ...| www.startdataengineering.com
Do you need clarification about what Open Table Formats (OTF) are? Is it more than just a pointer to some metadata files that helps you sift through the data quickly? What is the difference between table formats (Apache Iceberg, Apache Hudi, Delta Lake) & file formats (Parquet, ORC)? How do OTFs work? Then this post is for you. Understanding the underlying principle behind open table formats will enable you to deeply understand what happens behind the scenes and make the right decisions when ...| www.startdataengineering.com
Whether you are a new Data Engineer or someone with a few years of experience, you inevitably would have encountered messy data systems that seemed impossible to fix. Working at such a company usually comes with multiple pointless meetings, no clear work expectations, frustration, career stagnation, and ultimately no satisfaction from work! The reasons can be Managerial: Such as politics, red tape, cluelessness of management, influential people dictating roadmap, etc or Technical: Such as no ...| www.startdataengineering.com
Are you a data engineer who can't respond quickly to user requests since your self-serve tool is over-complex with a lot of tech debt? Has your team's over-reliance on so-called self-serve tools (vs. focusing on end-user) caused the company to waste a lot of money? Is your work satisfaction suffering due to slow-moving, technical debt-ridden systems meant to enable end-users to use data effectively? Are you tired of vendors trying to sell you their self-serve data platform while not elaborati...| www.startdataengineering.com
Are you looking to better yourself as a data engineer? But, when you look at job postings or company tech stack, you are overwhelmed by the sheer amount of tools you have to learn! Do you feel like you are just winging it and need a solid plan? Choosing what to learn among 100s of tools/frameworks can lead to analysis paralysis. The result is feeling overwhelmed, confused, and developing imposter syndrome, which is not helpful! What if you can have a fun and impactful career? You can be a for...| www.startdataengineering.com
Stream processing differs from batch; one needs to be mindful of the system's memory, event order, and system recovery in case of failures. However, understanding the fundamental concepts of time attributes, cluster memory, time-bounded joins, and system monitoring will enable you to build resilient and efficient streaming pipelines. If you are looking for an end-to-end streaming tutorial or a project to understand the foundational skills required to build streaming pipelines, this post is fo...| www.startdataengineering.com
As data engineers, you might have heard the terms functional data pipeline, factory pattern, singleton pattern, etc. One can quickly look up the implementation, but it can be tricky to understand what they are precisely and when to (& when not to) use them. Blindly following a pattern can help in some cases, but not knowing the caveats of a design will lead to hard-to-maintain and brittle code! While writing clean and easy-to-read code takes years of experience, you can accelerate that by und...| www.startdataengineering.com
Setting up data infra is one of the most complex parts of starting a data engineering project. Overwhelmed trying to set up data infrastructure with code? Or using dev ops practices such as CI/CD for data pipelines? In that case, this post will help! This post will cover the critical concepts of setting up data infrastructure, development workflow, and sample data projects that follow this pattern. We will also use a data project template that runs Airflow, Postgres, & Metabase to demonstrate...| www.startdataengineering.com
Frustrated trying to pry data pipeline requirements out of end users? Is scope creep preventing you from delivering data projects on time? You assume that the end-users know (and communicate) exactly what they want, but that is rarely the case! Adhoc feature/change requests throw off your delivery timelines. You want to deliver on time and make an impact, but you are interrupted constantly! Requirements gathering is rough, but it doesn't have to be! We go over five steps you can follow, to wo...| www.startdataengineering.com
Do you feel overworked and underpaid? Are you a data engineer labeled as a data analyst, with a data analyst pay? Are you struggling to prepare efficiently for data engineering interviews? You want to work on problems that interest you, be able to earn a good salary and be acknowledged for your skills. But, landing such a job can seem daunting and almost impossible. In this post, we will go over 5 steps to help you land a data engineering role that pays well and enables you to work on interes...| www.startdataengineering.com
Struggling with setting up a local development environment for your python data projects? Then this post is for you! In this post, you will learn how to set up a local development environment for data projects using docker. By the end of this post, you will know how to set up your local development environment the right way with docker. You will be able to increase developer ergonomics, increase development velocity and reduce bugs.| www.startdataengineering.com
Data engineering project for beginners, using AWS Redshift, Apache Spark in AWS EMR, Postgres and orchestrated by Apache Airflow.| www.startdataengineering.com
Confused by all the "data lake vs data warehouse" articles? Struggling to understand what the differences between data lakes and warehouses are? Then this post is for you. We go over what data lakes and warehouses are. We also cover the key points to consider when choosing your lake and warehouse tools.| www.startdataengineering.com
Struggling to come up with a data engineering project idea? Overwhelmed by all the setup necessary to start building a data engineering project? Don't know where to get data for your side project? Then this post is for you. We will go over the key components, and help you understand what you need to design and build your data projects. We will do this using a sample end-to-end data engineering project.| www.startdataengineering.com
Worried about introducing data pipeline bugs, regressions, or introducing breaking changes? Then this post is for you. In this post, you will learn what CI is, why it is crucial to have data tests as part of CI, and how to create a CI pipeline that automatically runs data tests on pull requests using Github Actions.| www.startdataengineering.com
So you know how it can be overwhelming to choose the right tools for your data pipeline? What if you knew the core components involved in any data pipeline and can always pick the right tools for your data pipeline? Now you can! Use this framework to choose the best tool for your data pipeline.| www.startdataengineering.com
Worried about setting up end-to-end tests for your data pipelines? Wondering if they are worth the effort? Then, this post is for you. In this post, we go over some techniques to set up end-to-end tests. We will also see which components to prioritize while testing.| www.startdataengineering.com
Are you disappointed with online SQL tutorials that aren't deep enough? Are you frustrated knowing that you are missing SQL skills, but can't quite put your finger on it? This post is for you. In this post, we go over a few topics that can take your SQL skills to the next level and help you be a better data engineer.| www.startdataengineering.com
Unclear data engineering job description ? Wondering what responsibilities falls within a data team ? Then this post is for you. In this post we go over the 6 key responsibilities of a data engineer. The number of these responsibilities that you may end up handling depends on your company and team. Teams in smaller companies generally handle all 6 responsibilities, whereas larger sized companies may have individual(or multiple) teams handling one(or a mix) of these responsibilities.| www.startdataengineering.com
In this post, we go over 6 key concepts to help you master window functions. Window functions are one the most powerful features of SQL, they are very useful in analytics and performing operations that cannot be done easily with the standard group by, subquery and filters. Despite this, window functions are not used frequently. If you have ever thought 'window functions are confusing', then this post is for you.| www.startdataengineering.com
You have heard of Common Table Expressions(CTEs), but are not be sure what they are and when to use them. What if you knew exactly what Common Table Expressions(CTEs) were and when to use them? In this post, we go over what CTEs are, and their performance comparisons against subqueries, derived tables, and temp tables to help decide when to use them.| www.startdataengineering.com
This post goes over what the ETL and ELT data pipeline paradigms are. It tries to address the inconsistency in naming conventions and how to understand what they really mean. Finally ends with a comparison of the 2 paradigms and how to use these concepts to build efficient and scalable data pipelines.| www.startdataengineering.com
Trying to incorporate testing in a data pipeline? This post is for you. In this post, we go over 4 types of tests to add to your data pipeline to ensure high-quality data. We also go over how to prioritize adding these tests, while developing new features.| www.startdataengineering.com
Preparing for a data engineering interview and are overwhelmed by all the tools and concepts?. Then this post is for you, in this post we go over the most common tools and concepts you need to know to ace your data engineering interviews.| www.startdataengineering.com
Wondering what is staging and why you need one for your data pipelines? Then this post is for you. In this post, we will go over what exactly a staging area is and why it is crucial for data pipelines.| www.startdataengineering.com
Want to deliver on your data engineering tasks with confidence? Then this post is for you. In this post, we go over a list of steps that you can use to understand what your assigned work is, why it matters and how to deliver great work.| www.startdataengineering.com
Unsure how to load data into a data warehouse? Then this post is for you. In this post, we go over 4 key patterns to load data into a data warehouse. These patterns can help you build resilient and easy-to-use data pipelines. Level up as a data engineer and deliver usable data faster!| www.startdataengineering.com
Frustrated that hiring managers are not reading your Github projects? then this post is for you. In this post, we discuss a way to impress hiring managers by hosting a live dashboard with near real-time data. We will also go over coding best practices such as project structure, automated formatting, and testing to make your code professional. By the end of this post, you will have deployed a live dashboard that you can link to your resume and LinkedIn.| www.startdataengineering.com
Working with a dataset that is too large to fit in memory? Then this post is for you. In this post, we will write memory efficient data pipelines using python generators. We also cover the common generator patterns you will need for your data pipelines.| www.startdataengineering.com
If you are overwhelmed with re-engineering a legacy data pipeline, then this post is for you. In this post, we go over 6 key principles to help you figure out the most impactful data features for your end user and how to deliver them.| www.startdataengineering.com
Wondering how to execute a spark job on an AWS EMR cluster, based on a file upload event on S3? Then this post if for you. In this post we go over how to trigger spark jobs on an AWS EMR cluster, using AWS Lambda. The lambda function will execute in response to an S3 upload event. We will go over this event driven pattern with code snippets and set up a fully functioning pipeline.| www.startdataengineering.com
Setting up an ELT data-ops workflow with multiple environments for developers is often extremely time consuming. What if there was a way to speed up this process, so that you could concentrate on modeling your data and delivering value to your end users? The good news is that there is a way. You can leverage dbt cloud to setup an ELT data-ops workflow in a very short time. In this post, we cover how to setup a data-ops workflow for an ELT system. We will go over how to setup dbt, snowflake, C...| www.startdataengineering.com
Spending hundreds of thousands of dollars on vendor BI tools ? Looking for a clean open source alternative ? Then this post is for you. In this post we go over Apache Superset, which is one of the most popular open source visualization tools. We will go over its architecture and build charts and dashboards to visualize data. We will end with a list of pros and cons with using an open source visualization tool like Apache Superset.| www.startdataengineering.com
Wondering how to store a dimension table's history over time and how to join these historical dimension tables with fact tables for analytical querying ? Then this post is for you. In this post, we will go over a popular dimension modeling technique called SCD2, which preserves historical changes. We will also see how to join a fact table with an SCD2 table to get accurate point in time information.| www.startdataengineering.com
Whenever updating a few records in an OLTP table we just use the update command. But what if we have to update millions of records in an OLTP table? If you run a large update, your database will lock those records and other transactions may fail. In this post we look at how a large update can cause lock timeout error and how running batches of smaller updates can eliminate this issue.| www.startdataengineering.com
Wondering how to backfill an hourly SQL query in Apache Airflow ? Then, this post is for you. In this post we go over how to manipulate the execution_date to run backfills with any time granularity. We use an hourly DAG to explain execution_date and how you can manipulate them using Airflow macros.| www.startdataengineering.com
Change data capture(CDC) is a software design pattern in which we track every change(update, insert, delete) to the data in a database and replicate it to other database(s). In this post we will see how to do CDC by reading data from database logs and replicating it to other databases, using the popular open source Singer standard.| www.startdataengineering.com
If you are looking for an easy to setup and simple way to automate, schedule and monitor a 'small' API data pull on the cloud, serverless functions are a good option. In this post we cover what a serverless function can and cannot do, what its pros and cons are and walk through a simple API data pull project. We will be using AWS Lambda and AWS S3 for this project.| www.startdataengineering.com
There are many ways to submit an Apache Spark job to an AWS EMR cluster using Apache Airflow. In this post we go over the steps on how to create a temporary EMR cluster, submit jobs to it, wait for the jobs to complete and terminate the cluster, the Airflow-way.| www.startdataengineering.com
Ensure your data meets basic and business specific data quality constraints. In this post we go over a data quality testing framework called great expectations, which provides powerful functionality to cover the most common test cases and the ability to group them together and run them.| www.startdataengineering.com
With the advent of powerful data warehouses like snowflake, bigquery, redshift spectrum, etc that allow separation of storage and execution, it has become very economical to store data in the data warehouse and then transform them as required. This post goes over how to design such a ELT system using stitch and DBT. The main objective is to keep the code complexity and server management low, while automating as much as possible| www.startdataengineering.com
This post covers key techniques to optimize your Apache Spark code. You will know exactly what distributed data storage and distributed data processing systems are, how they operate and how to use them efficiently. Go beyond the basic syntax and learn 3 powerful strategies to drastically improve the performance of your Apache Spark project.| www.startdataengineering.com
Apache Kafka is a distributed streaming platform. This post goes over the common scenarios when using Apache Kafka will be beneficial, how to use it and the basic concepts of Apache Kafka| www.startdataengineering.com
Tutorial on what happens when you create an index in a database. Trade offs to be aware of while creating an index and how to use it efficiently.| www.startdataengineering.com
In this article we aim to go over the reasoning behind why someone might want to use dbt. If you are interested in learning dbt checkout this article . Some common questions from Data Engineers about dbt are it is not very clear to me why would I use dbt instead of running SQL queries on Airflow| www.startdataengineering.com
When getting started with Apache Airflow, data engineers have questions similar to the two below “What are people’s opinions of Airflow?”| www.startdataengineering.com
Many data engineers coming from traditional batch processing frameworks have questions about real time data processing systems, like “What kind of data model did you implement, for real-time processing?”| www.startdataengineering.com
One of the most common use cases for Apache Airflow is to run scheduled SQL scripts. Developers who start with Airflow often ask the following questions “How to use airflow to orchestrate sql?”| www.startdataengineering.com
If you are trying to improve your data engineering skills or are the sole data person in your company, it can be hard to know how well your technical skills are developing. Questions like Am I building pipelines the right way? How do I measure up to DEs at bigger tech companies? How do I get feedback on my pipeline design? It can cause a lot of uncertainty in career development! Imagine if you know that your code is on par (or even better than) with pipelines at tech-forward companies and tha...| www.startdataengineering.com
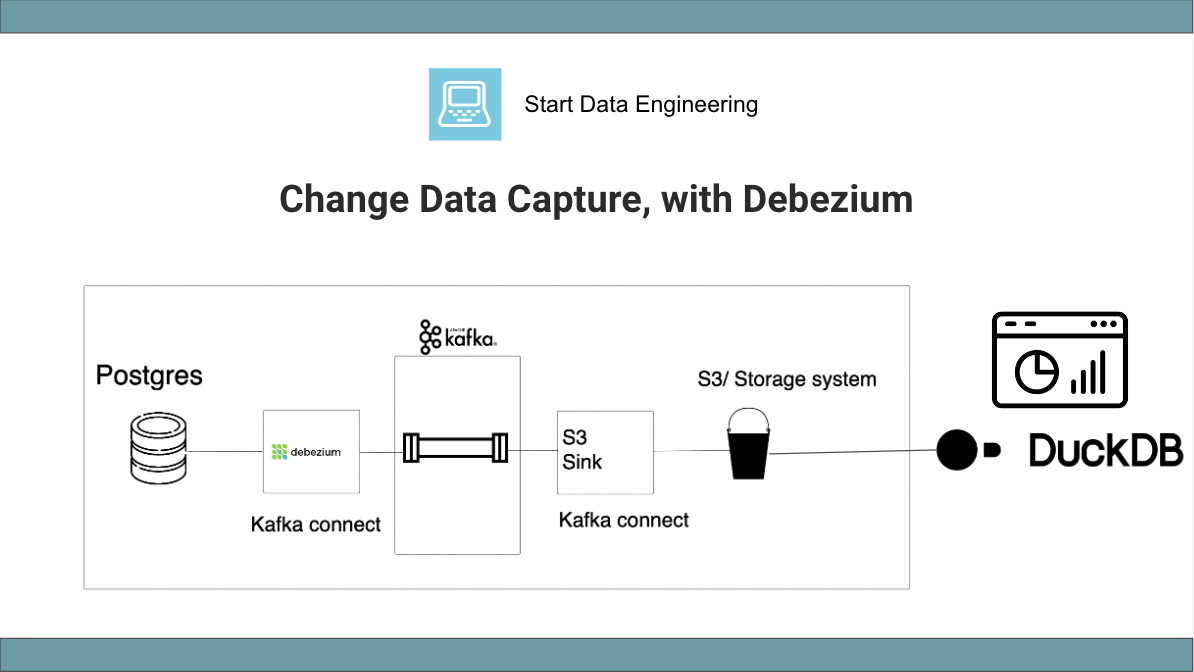
Change data capture is a popular technique to copy data from DBs into warehouses. However, it can be tricky to understand at first. Without working with a CDC system, knowing what it does, why it's needed, or how it works can be challenging. However, understanding the what, why, and how of CDC can help you set up pipelines that are resilient and reliable. If you have wondered what CDC does, why it's needed, and how it works, this post is for you. By the end of this post, you will have a good ...| www.startdataengineering.com
Data pipelines built (and added on to) without a solid foundation will suffer from poor efficiency, slow development speed, long times to triage production issues, and hard testability. What if your data pipelines are elegant and enable you to deliver features quickly? An easy-to-maintain and extendable data pipeline significantly increase developer morale, stakeholder trust, and the business bottom line! Using the correct design pattern will increase feature delivery speed and developer valu...| www.startdataengineering.com
Unclear what a data warehouse is or when to use one? Then this post is for you. In this post, we go over what a data warehouse is, the need for it, and the differences between using an OLTP and OLAP database as a data warehouse.| www.startdataengineering.com
Frustrated with handling data type conversion issues in python? Then this post is for you. In this post, we go over a reusable data type conversion pattern using Pydantic. We will also go over the caveats involved in using this library.| www.startdataengineering.com
Unable to find practical examples of idempotent data pipelines? Then, this post is for you. In this post, we go over a technique that you can use to make your data pipelines professional and data reprocessing a breeze.| www.startdataengineering.com
Using dbt you can test the output of your sql transformations. If you have wondered how to "unit test" your sql transformations in dbt, then this post is for you. In this post, we go over how to write unit tests for your sql transformations with mock inputs/outputs and test them locally. This helps keep the development cycle shorter and enables you to follow a TDD approach for your sql based data pipelines.| www.startdataengineering.com
Key skills required for a data engineer. If you are getting into data engineering, this post gives you a ordered list of topics you can start learning.| www.startdataengineering.com
Confused by all the tools and frameworks available to scale your data pipeline? Then this post is for you. In this post, we go over what scaling is, the different types of scaling, and how to choose scaling strategies for your data pipelines. By the end of this post, you will be able to come up with the correct scaling strategy for any data pipeline.| www.startdataengineering.com