
Fine-Tuning Gemma 3n for Speech Transcription
Fine-tuning Gemma 3n for German speech transcription using the Unsloth library and carrying out evaluation.| DebuggerCafe
In this article, we are training the Gemma 3n model for transcription and translation of German audio files to English using the Unsloth library and creating a Gradio application also. The post Training Gemma 3n for Transcription and Translation appeared first on DebuggerCafe.| DebuggerCafe
Fine-tuning Gemma 3n for German speech transcription using the Unsloth library and carrying out evaluation.| DebuggerCafe
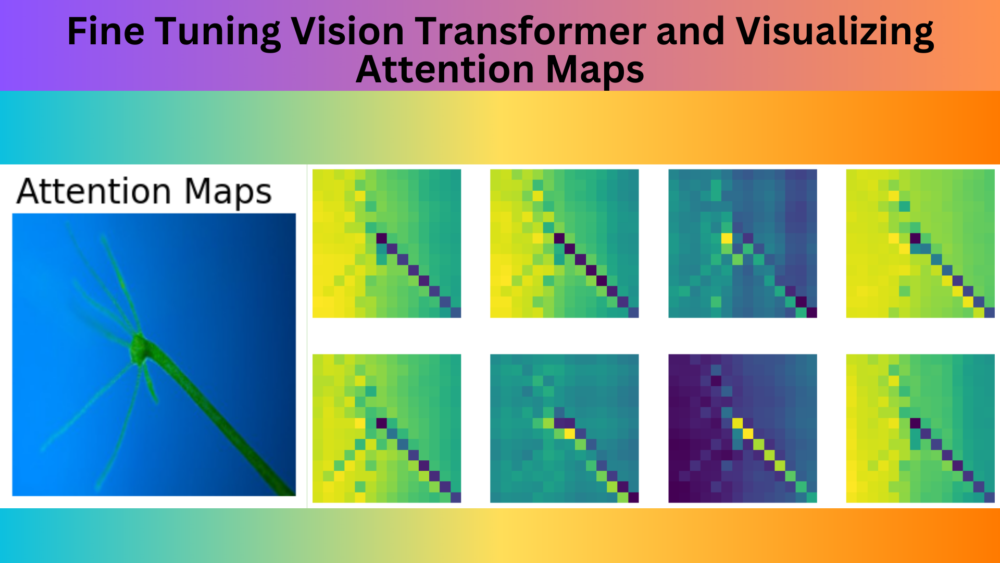
Fine tuning Vision Transformer on a custom image classification dataset and visualizing the attention maps using the trained model.| DebuggerCafe
In this article, we create a multimodal Gradio application with Together AI models for chatting LLMs & VLMs, generating images, and automatic speech transcription using OpenAI Whisper models. The post Multimodal Gradio App with Together AI appeared first on DebuggerCafe.| DebuggerCafe

Together AI serverless inference for text generation, image generation, and vision language models along with Gradio chat application.| DebuggerCafe
In this article, we create a background replacement application using BiRefNet. We cover the code using Jupyter Notebook and create a Gradio application as well. The post Background Replacement Using BiRefNet appeared first on DebuggerCafe.| DebuggerCafe
In this article, we explore the BiRefNet model for high-resolution dichotomous segmentation. Along with discussing the key elements of the paper, we also create a small background removal codebase usign the pretrained model. The post Introduction to BiRefNet appeared first on DebuggerCafe.| DebuggerCafe

Semantic segmentation using I-JEPA for brain tumor segmentation on the BRISC-2025 dataset with the PyTorch framework.| DebuggerCafe
In this article, we explore deploying LLMs using Runpod, Vast.ai, Docker, and Hugging Face Text Generation Inference. The post Deploying LLMs: Runpod, Vast AI, Docker, and Text Generation Inference appeared first on DebuggerCafe.| DebuggerCafe

Image classification using I-JEPA PyTorch by adding a linear layer on top of the frozen backbone and training for brain tumor classification.| DebuggerCafe
In this article, we use a pretrained I-JEPA model for image similarity. We specifically use the ViT-H I-JEPA trained with 14x14 patches. The post JEPA Series Part 2: Image Similarity with I-JEPA appeared first on DebuggerCafe.| DebuggerCafe

I-JEPA methodoly teaches a vision transformer model to predict parts of an image in the latent space rather than the pixel space.| DebuggerCafe

Fine-tuning SmolLM2-135M Instruct model on the WMT14 French-to-English subset for machine translation using a small language model.| DebuggerCafe
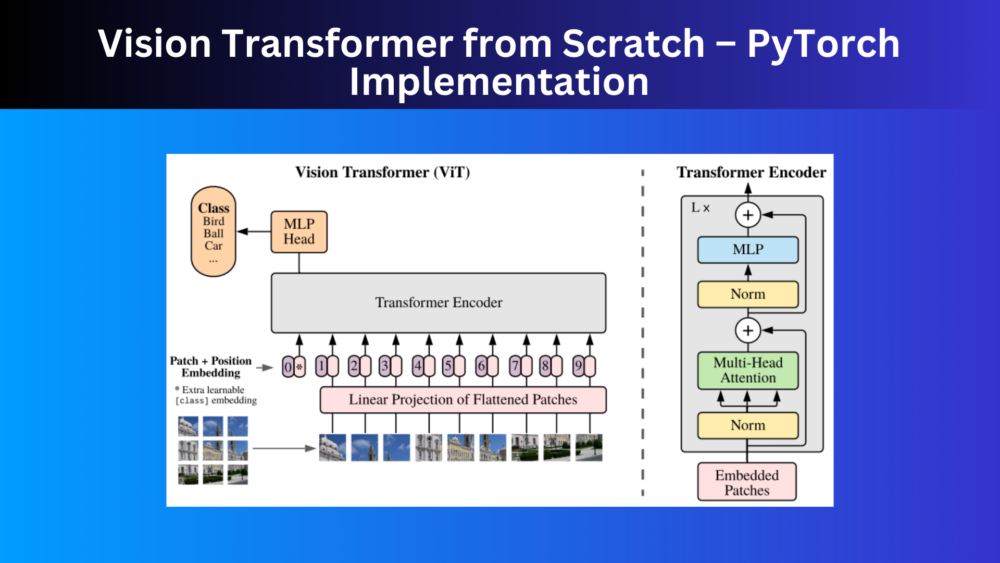
Implementation of the Vision Transformer model from scratch (Dosovitskiy et al.) using the PyTorch Deep Learning framework.| DebuggerCafe

Qwen2.5-VL is the newest member in the Qwen Vision Language family, capable of image captioning, video captioning, and object detection.| DebuggerCafe
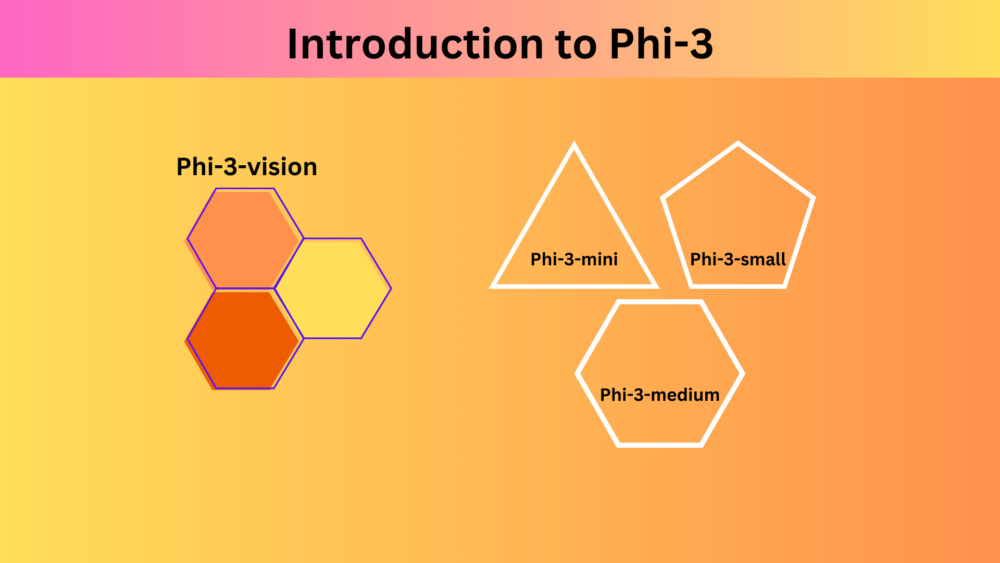
In this article, we cover the summary of the Phi-3 technical report including the architecture, the dataset curation strategy, benchmarks, and Phi-3 vision capabilities.| DebuggerCafe
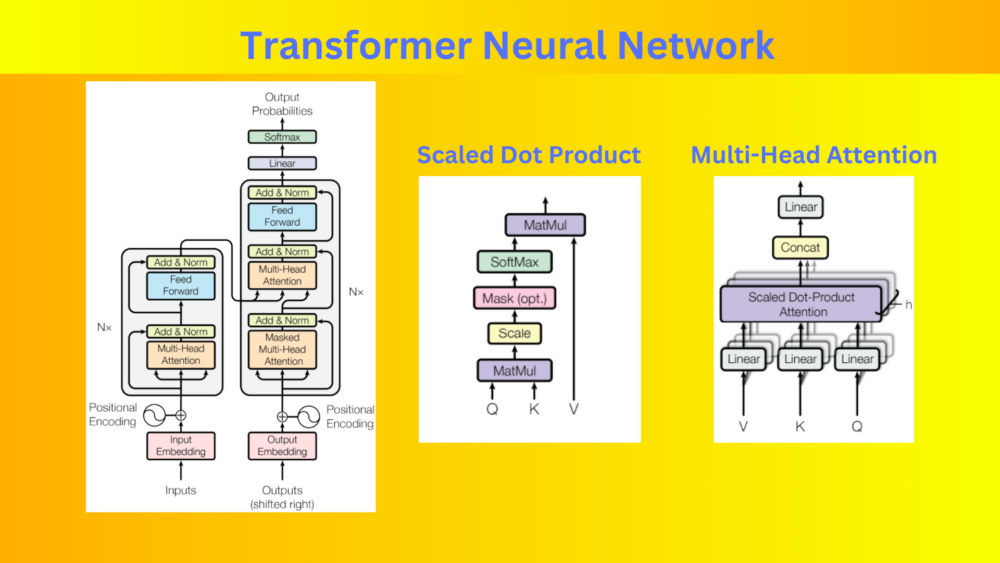
Understand the components, pretraining, and results of the Transformer Neural Network by breaking down the Attention is All You Need paper.| DebuggerCafe

In this article, we follow a code-first approach to text classification using PyTorch, NLP, and Deep Learning.| DebuggerCafe
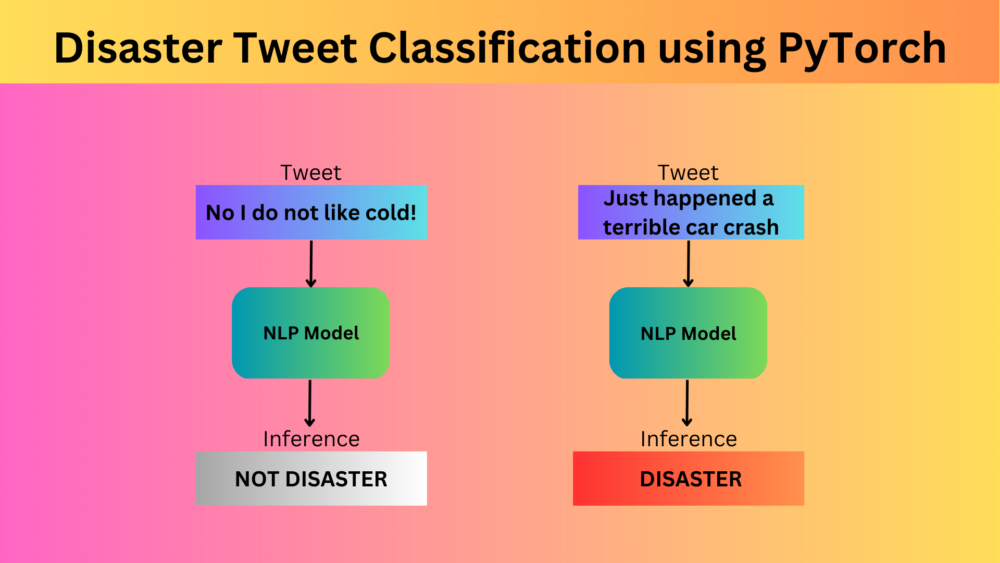
In disaster tweet classification, we train a simple PyTorch language model using a single embedding layer and a linear layer.| DebuggerCafe
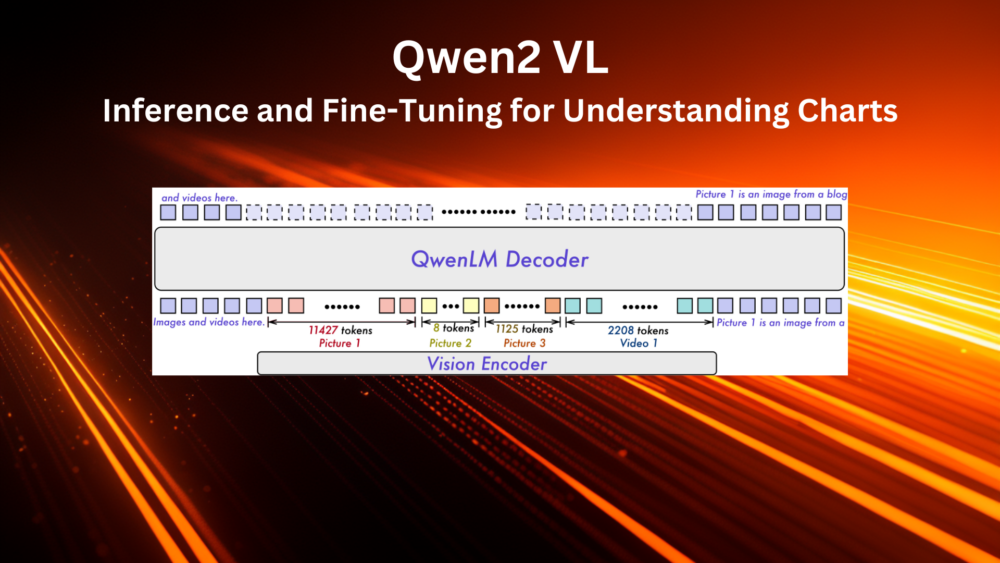
Qwen2 VL is a Vision Language model with the Qwen2 Language Decoder and Vision Transformer model from DFN as the image encoder.| DebuggerCafe

Fine-tuning Llama 3.2 Vision on a LaTeX2OCR dataset to predict raw LaTeX equations from images and creating a Gradio application.| DebuggerCafe

Llama 3.2 Vision model is a multimodal VLM from Meta belonging to the Llama 3 family that brings the capability to feed images to the model.| DebuggerCafe

Unsloth provides memory efficient and fast inference & training of LLMs with support for several models like Meta Llama, Google Gemma, & Phi.| DebuggerCafe
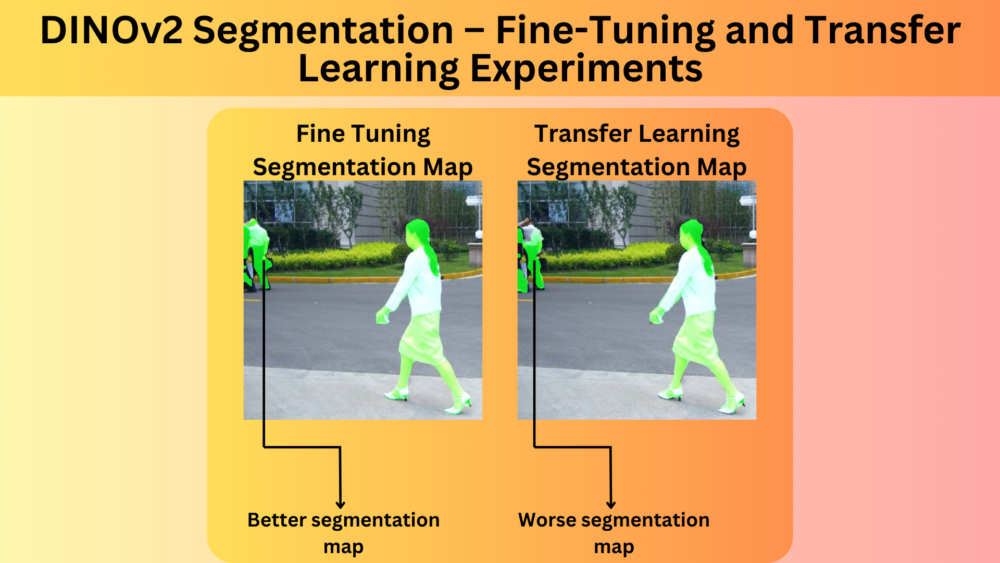
Carrying out DINOv2 segmentation experiments for fine-tuning and transfer learning and comparing the results.| DebuggerCafe

Modifying the DINOv2 model for semantic segmentation and training the model on the Penn-Fudan Pedestrian Segmentation Dataset.| DebuggerCafe

Exploring DINOv2 for image classification and comparing fine-tuning and transfer learning results on a custom dataset.| DebuggerCafe

DINOv2 is a self-supervised computer vision model which learns robust visual features that can be used for downstream tasks.| DebuggerCafe
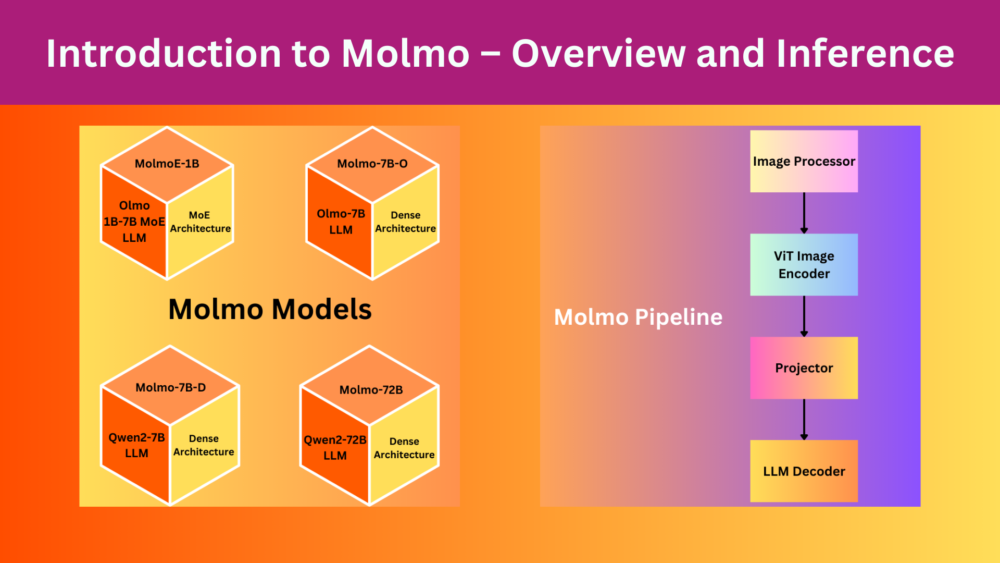
Molmo is a family of new VLMs trained using the PixMo group of datasets that can describe images and also point & count objects in image.| DebuggerCafe
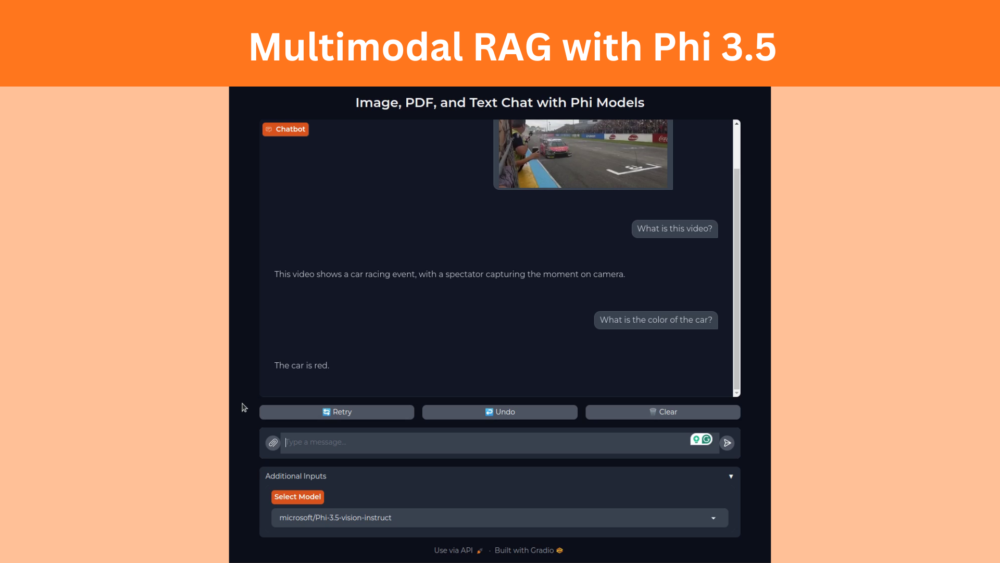
Multimodal RAG Chat application to chat with PDFs, text files, images, and videos using Phi-3.5 family of language models.| DebuggerCafe

Instruction tuning the OPT-125M model by training it on the Open Assistant Guanaco dataset using Hugging Face Transformers.| DebuggerCafe

Instruction tuning the GPT2 model on the Alpaca dataset using the Hugging Face Transformers library and the SFT Trainer pipine.| DebuggerCafe

OpenELM is a family of efficient language models from Apple with completely open-source weights, training, and evaluation code.| DebuggerCafe
Contact DebuggerCafe for Machine Learning, Deep Learning, and AI.| DebuggerCafe

In this article, we will be fine tuning the LRASPP MobileNetV3 segmentation model on the KITTI dataset with two different approaches and compare the results.| DebuggerCafe

Fine-tuning the Phi 1.5 model on the BBC News Summary dataset for Text Summarization using Hugging Face Transformers.| DebuggerCafe

Phi 1.5 is a 1.3 Billion Parameters LLM by Microsoft which is capable of coding, common sense reasoning, and is adept in chain of thoughts.| DebuggerCafe

Instruction following Jupyter Notebook interface with a QLoRA fine-tuned Phi 1.5 model and the Hugging Face Transformers library.| DebuggerCafe

Fine tuning Phi 1.5 using QLoRA on the Stanford Alpaca instruction tuning dataset with the Hugging Face Transformers library.| DebuggerCafe

Training a robust facial keypoint detection model by fine-tuning the pretrained ResNet50 model with the PyTorch framework,| DebuggerCafe

RT-DETR is a Real-Time Detection Transformer model with state-of-the-art performance and speed on image and video inference using PyTorch.| DebuggerCafe
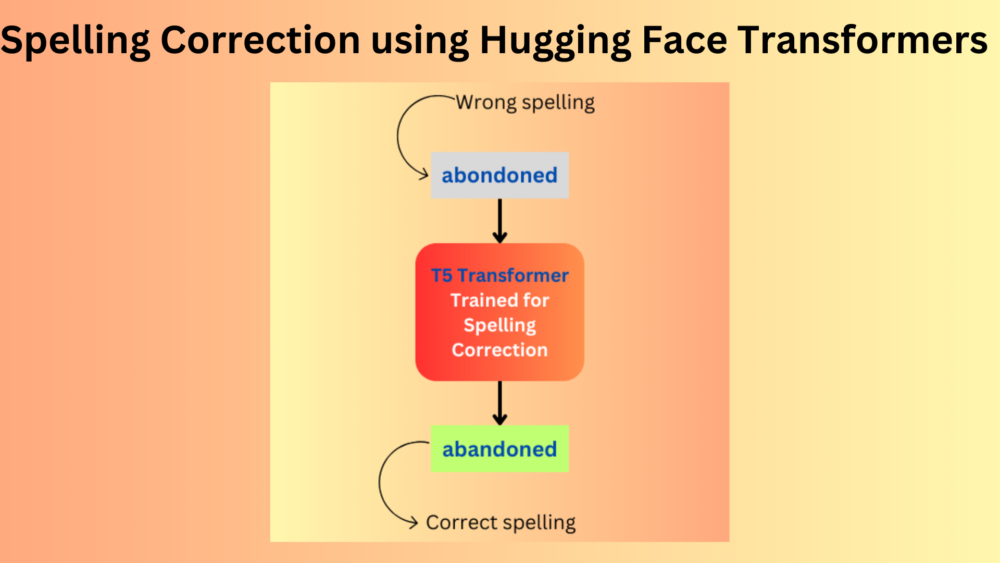
Training a spelling correction model using Hugging Face Transformers using the T5 Transformer model with PyTorch framework.| DebuggerCafe
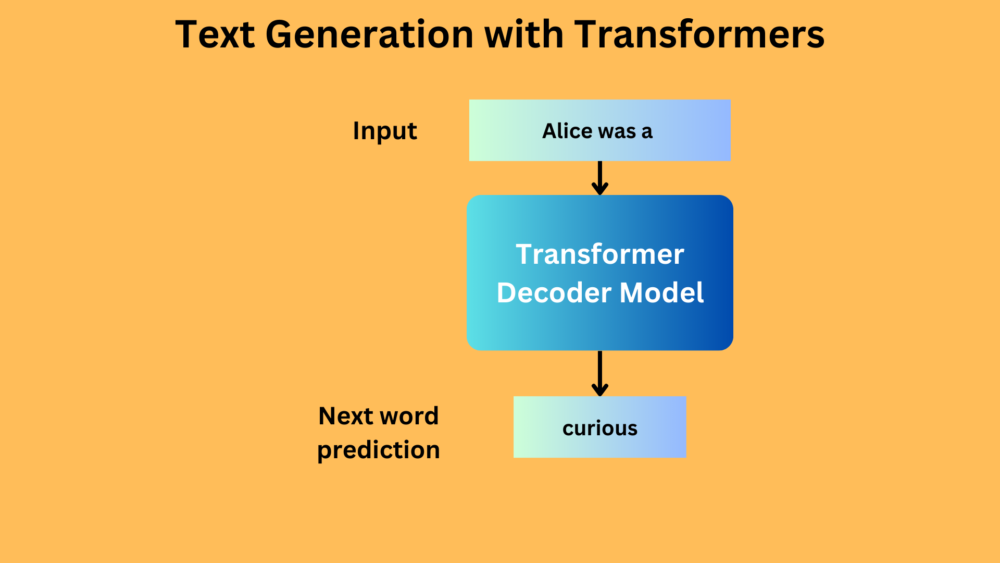
Text generation with Transformers - creating and training a Transformer decoder neural network for text generation using PyTorch.| DebuggerCafe
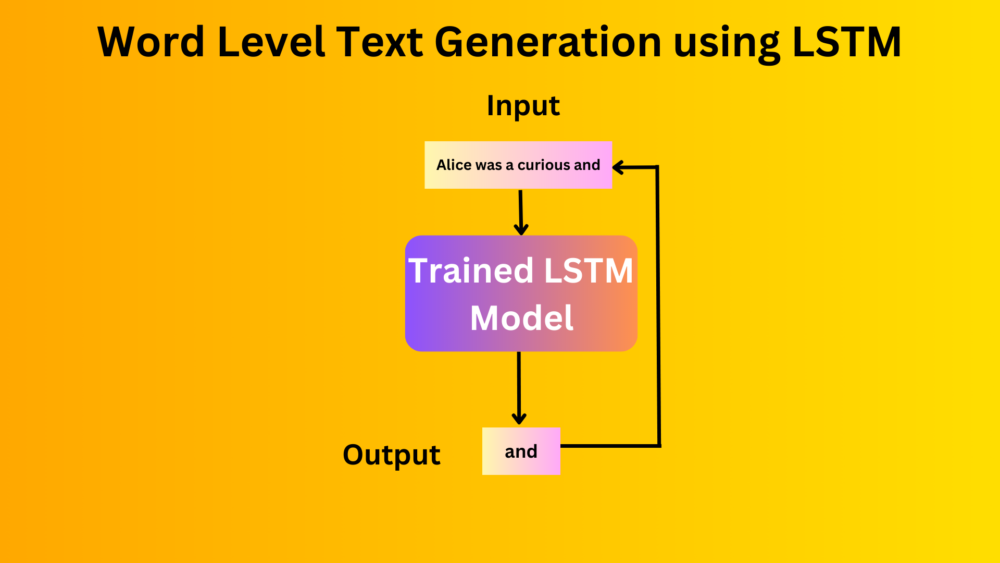
Training an LSTM (Long Short Term Memory) model for Word Level Text Generation using the PyTorch deep learning framework.| DebuggerCafe
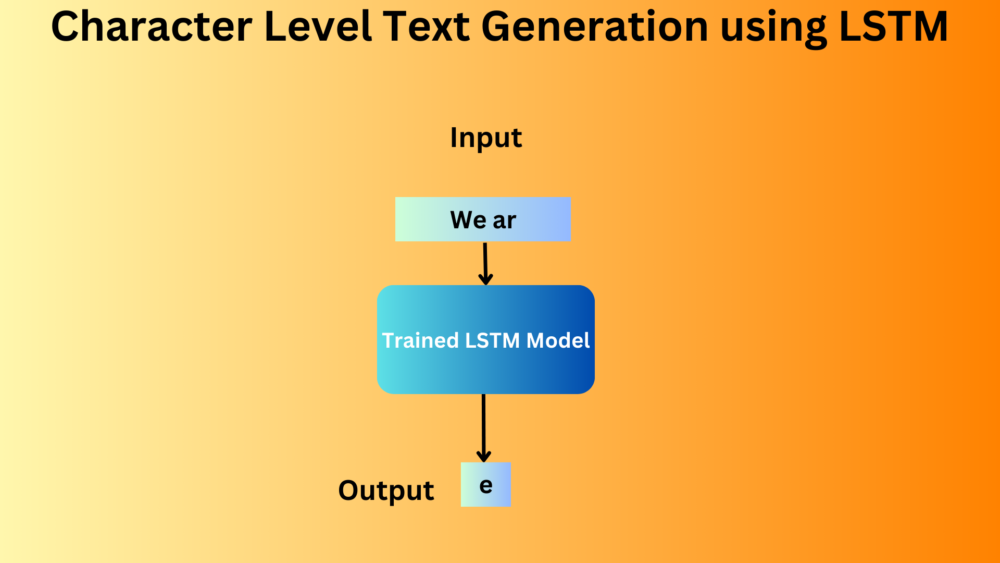
In this blog post, we train a character level text generation LSTM model using the PyTorch deep learning framework.| DebuggerCafe

DebuggerCafe is a website hosting articles on Deep Learning, Machine Learning, and Artificial Intelligence.| DebuggerCafe
