Web apps over SSH can be surprisingly good | Marcus Lewis
Marcus Lewis| Marcus Lewis
Marcus Lewis| Marcus Lewis
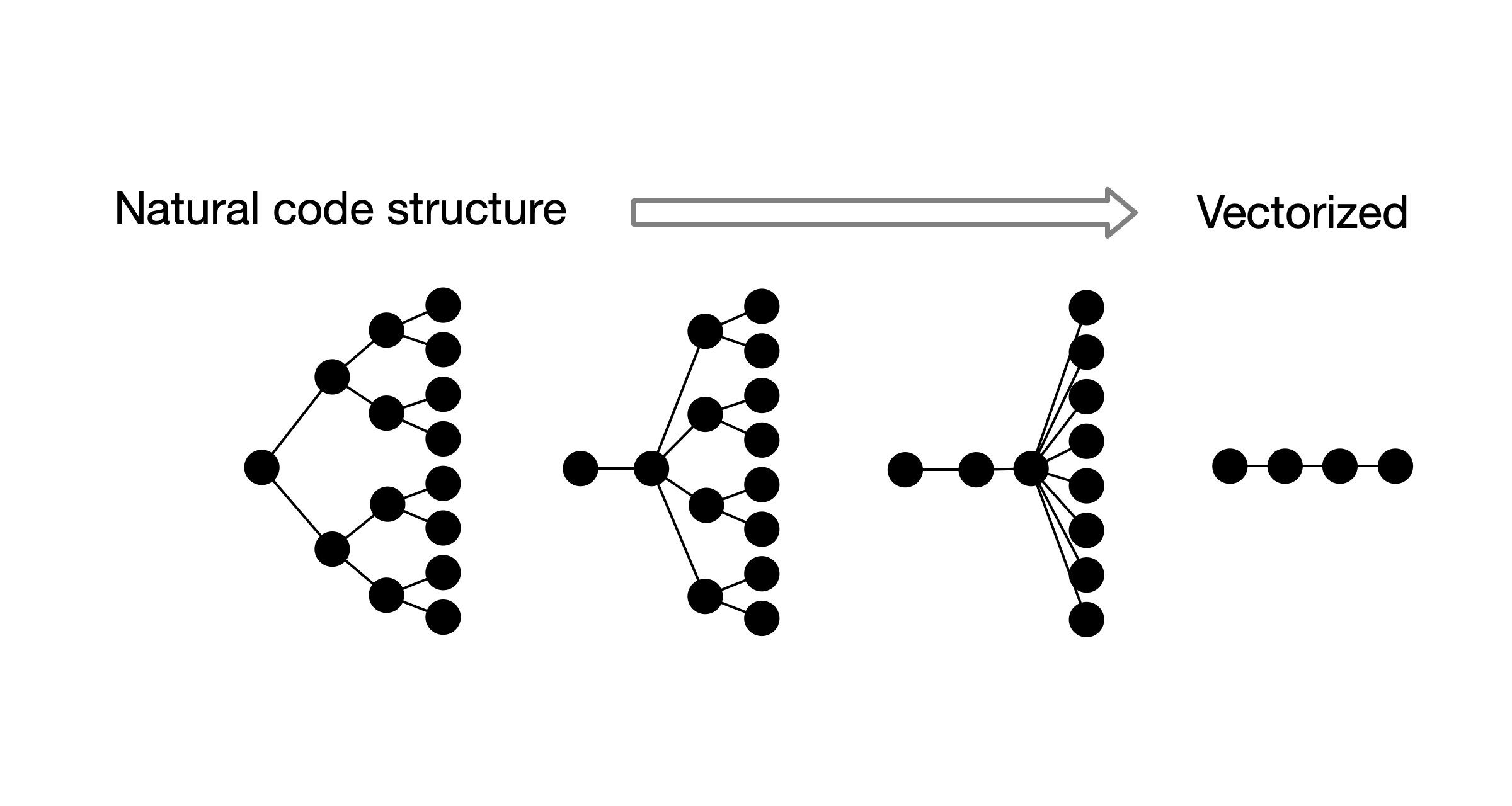
Think of all the client-side code that runs on your devices. Most technical people would say that it falls into two categories: Native apps, which are written for a specific platform and compiled to machine code. The web, which is written in cross-platform interpreted code. This mental model is a misconception. These categories are real, but nothing I mentioned about them is fundamental. The actual thing that distinguishes between these categories is whether the code can render a top-level wi...| Marcus Lewis
Here is a toy function. (To see the code and more plots, check out this notebook.) Figure 1: 80 random observations of a deterministic function (black) and the predicted maximal point in that function (orange), according to a Gaussian process trained on those 80 observations. Intuitively, it seems clear that this function’s highest value probably occurs when x is in the center region. But a Gaussian Process (GP) thinks the highest value is out in a more mediocre region. This isn’t just a ...| Marcus Lewis
(A writeup of a side project that I’m working on. I’ve posted working code on Github for both pytorch and tensorflow.) Imagine a deep neural network that has many chances to query information from its input, rather than just one chance, a network that reacts to the currently accumulated information to select its next query. How might this network work differently from today’s neural networks? I think this type of deep network would be more opportunistic and symbiotic with the input. Rat...| Marcus Lewis
(A cautionary tale, illustrated via a toy example. If you do Bayesian hyperparameter tuning, you will want to know about this. Here’s a notebook with all of my code.) Here are two rotations of a function. We are going to examine how well a Gaussian Process (GP) models this function. I have provided example axis labels, but feel free to substitute your own. In my example scenario, we are training a neural network, first running it for some number of epochs at a high learning rate, then runni...| Marcus Lewis
Marcus Lewis| Marcus Lewis
(2023-11-01 updates: Refreshed the charts, other small tweaks, posted reproducible experiments.)| Marcus Lewis