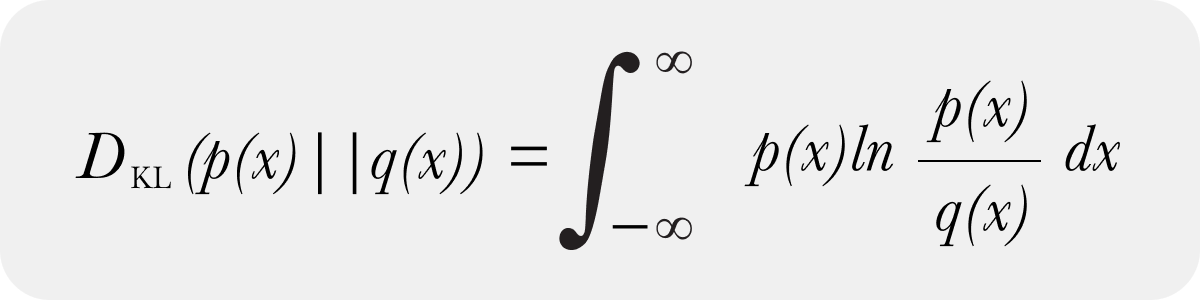September was a busy month product-wise for Arize AX, with updates to make AI agent engineering faster and easier. From session and trace evals to Alyx’s new synthetic data generation...| Arize AI
Coding agents have become the focal point of modern software development. Tools like Cursor, Claude Code, Codex, Cline, Windsurf, Devin, and many more are revolutionalizing how engineers write and ship... The post Optimizing Coding Agent Rules (CLAUDE.md, agents.md, ./clinerules, .cursor/rules) for Improved Accuracy appeared first on Arize AI.| Arize AI
Austin, Texas-based Keller Williams Realty, LLC is the world’s largest real estate franchise by agent count. It has more than 1,000 market center offices and 161,000 affiliated agents. The franchise... The post Keller Williams: Rise of the Agent Engineer appeared first on Arize AI.| Arize AI
Thanks to Aparna Dhinakaran and Elizabeth Hutton for their contributions to this piece. When building and testing AI agents, one practical question that arises is whether to use the same... The post Should I Use the Same LLM for My Eval as My Agent? Testing Self-Evaluation Bias appeared first on Arize AI.| Arize AI
Thanks to Hamel Husain and Eugene Yan for reviewing this piece Evals are becoming the predominant approach for how AI engineers systematically evaluate the quality of the LLM generated outputs.... The post Testing Binary vs Score Evals on the Latest Models appeared first on Arize AI.| Arize AI
Large language models are increasingly used to turn complex study output into plain-English summaries. But how do we know which models are safest and most reliable for healthcare? In this... The post Atropos Health’s Arjun Mukerji, PhD, Explains RWESummary: A Framework and Test for Choosing LLMs to Summarize Real-World Evidence (RWE) Studies appeared first on Arize AI.| Arize AI
Trunk Tools is building the brain behind construction, transforming the $13 trillion construction industry. As a premier AI agent platform for the built environment, Trunk Tools deploys solutions that streamline... The post Rise of the Agent Engineer: Trunk Tools’ Bobby Vinson appeared first on Arize AI.| Arize AI
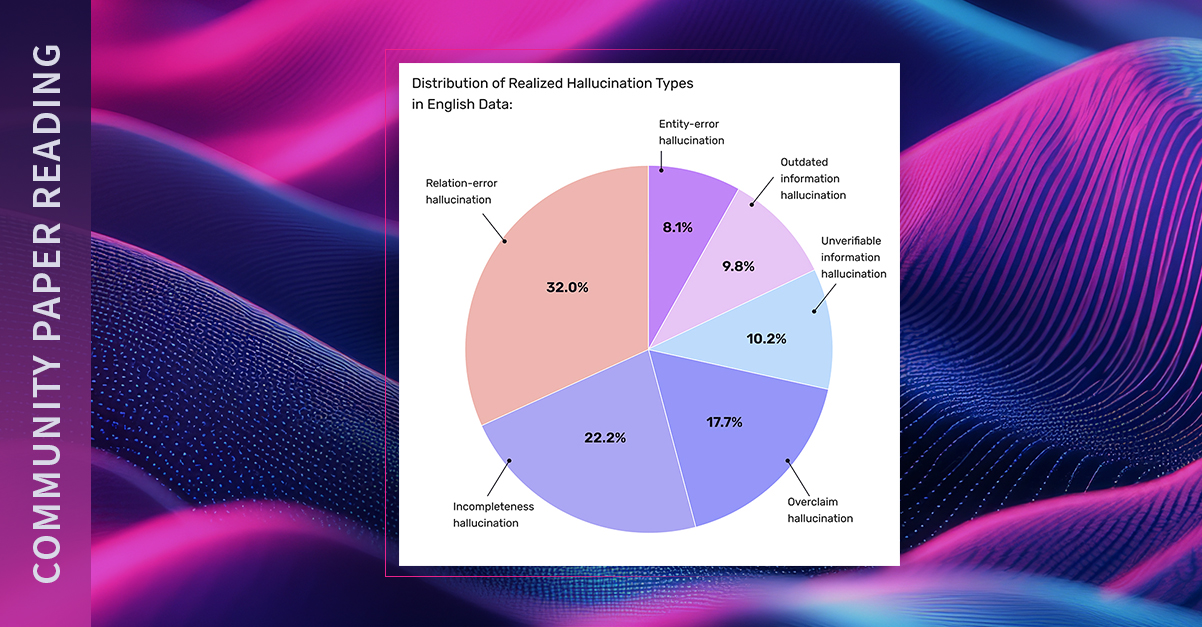
Over the past few weeks, the Arize team has generated the largest public dataset of hallucinations, as well as a series of fine-tuned evaluation models. We wanted to create a...| Arize AI
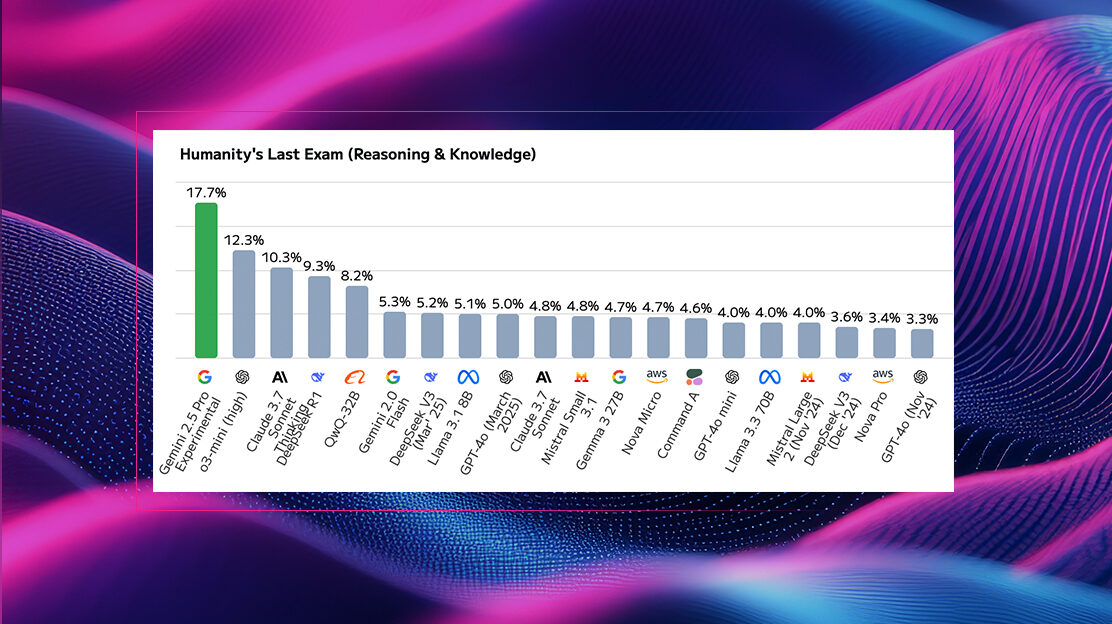
We cover modern AI benchmarks, taking a look at Google's Gemini 2.5 release and its performance on key evaluations like Humanity's Last Exam.| Arize AI
— Technical deep dive inspired by Anthropic’s “Building Effective Agents” In this piece, we’ll take a close look at the orchestrator–worker agent workflow. We’ll unpack its challenges and nuances, then... The post Orchestrator-Worker Agents: A Practical Comparison of Common Agent Frameworks appeared first on Arize AI.| Arize AI
How to evaluate LLM performance across languages for complex cypher query generation using open source tools As organizations expand globally, the need for multilingual AI systems becomes critical. But how... The post Building a Multilingual Cypher Query Evaluation Pipeline appeared first on Arize AI.| Arize AI
AI Evals for Engineers & PMs is a popular, hands‑on Maven course led by Hamel Husain and Shreya Shankar. The course’s goal is simple: “teach a systematic workflow for evaluating...| Arize AI
Where to use KL divergence, a statistical measure that quantifies the difference between one probability distribution from a reference distribution.| Arize AI
Tracing is a powerful tool for understanding the behavior of your LLM application. Leveraging LLM tracing with Arize, you can track down issues around application latency, token usage, runtime exceptions, retrieved documents, embeddings, LLM parameters, prompt templates, tool descriptions, LLM function calls, and more. To get started, you can automatically collect traces from major frameworks and libraries using auto instrumentation from Arize — including for OpenAI, LlamaIndex, Mistral AI,...| Arize AI
When evaluating AI applications, we often look at things like tool calls, parameters, or individual model responses. While this span-level evaluation is useful, it doesn’t always capture the bigger picture...| Arize AI
The Arize Blog covers the latest AI monitoring and AI Observability news from thought leaders. See why developers trust Arize to improve model performance.| Arize AI
Everything you need to know about the popular technique and the importance of evaluating retrieval and model performance throughout development and deployment| Arize AI
With a dizzying array of research papers and new tools, it’s an exciting time to be working at the cutting edge of AI. Given that the space is so new,...| Arize AI