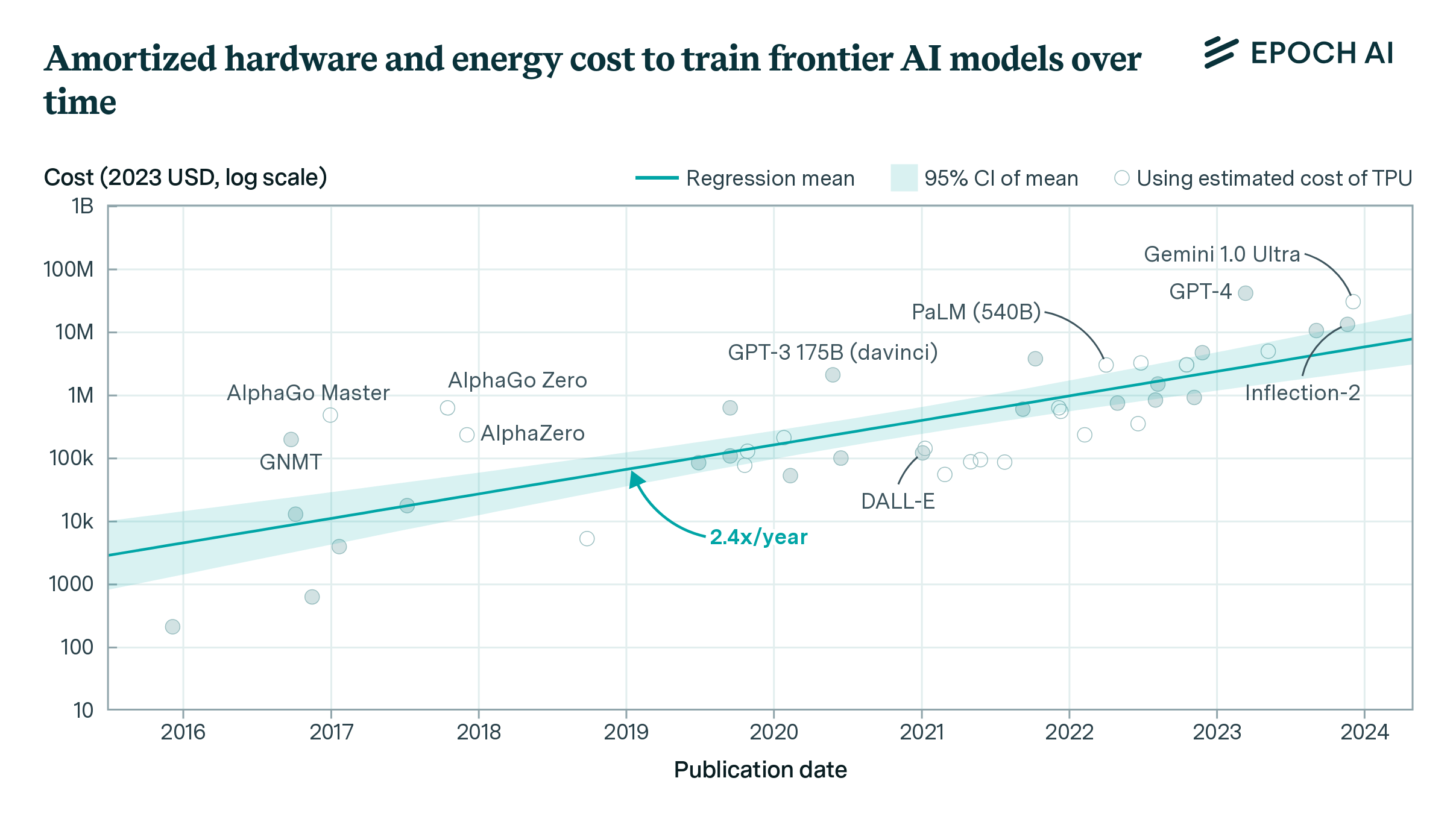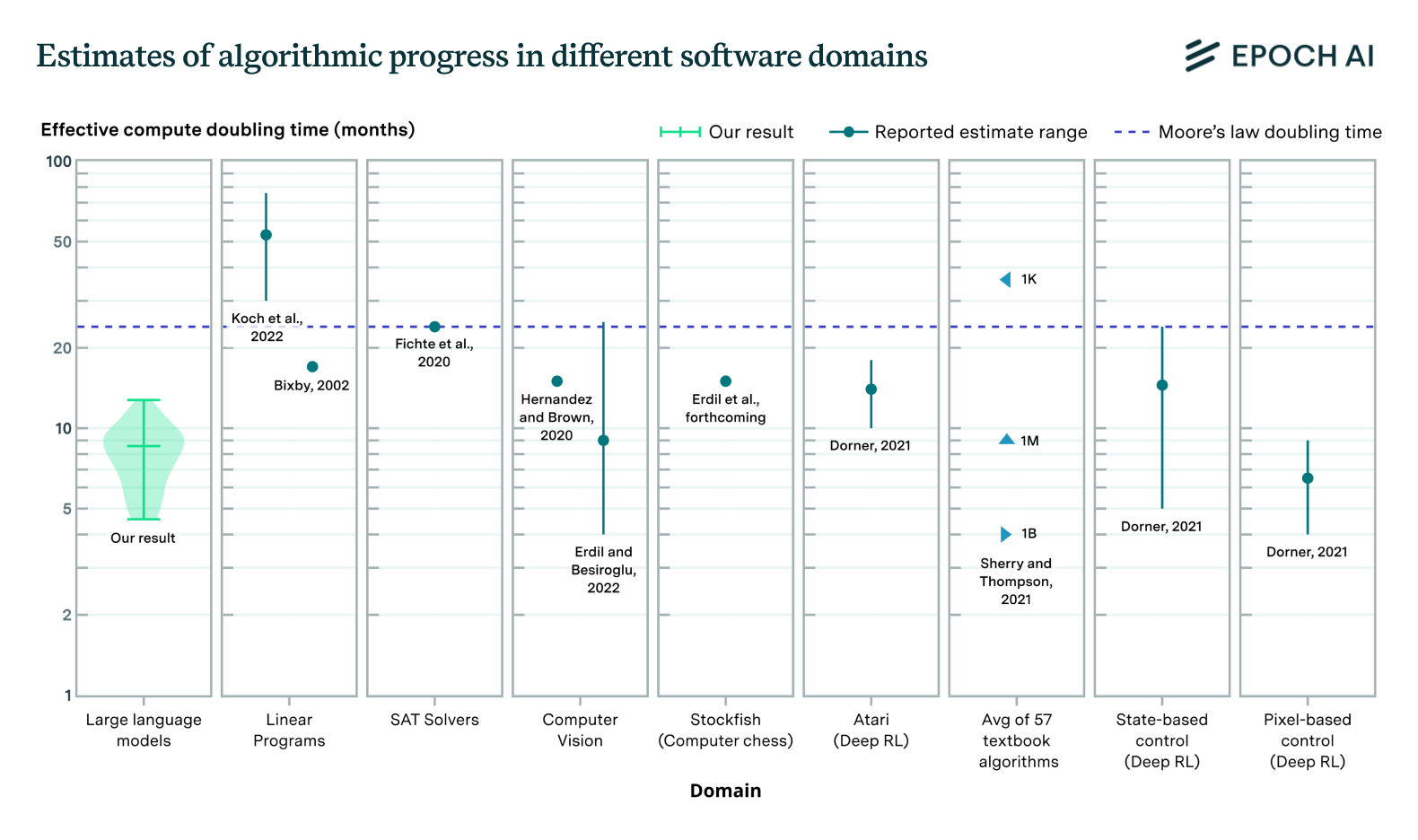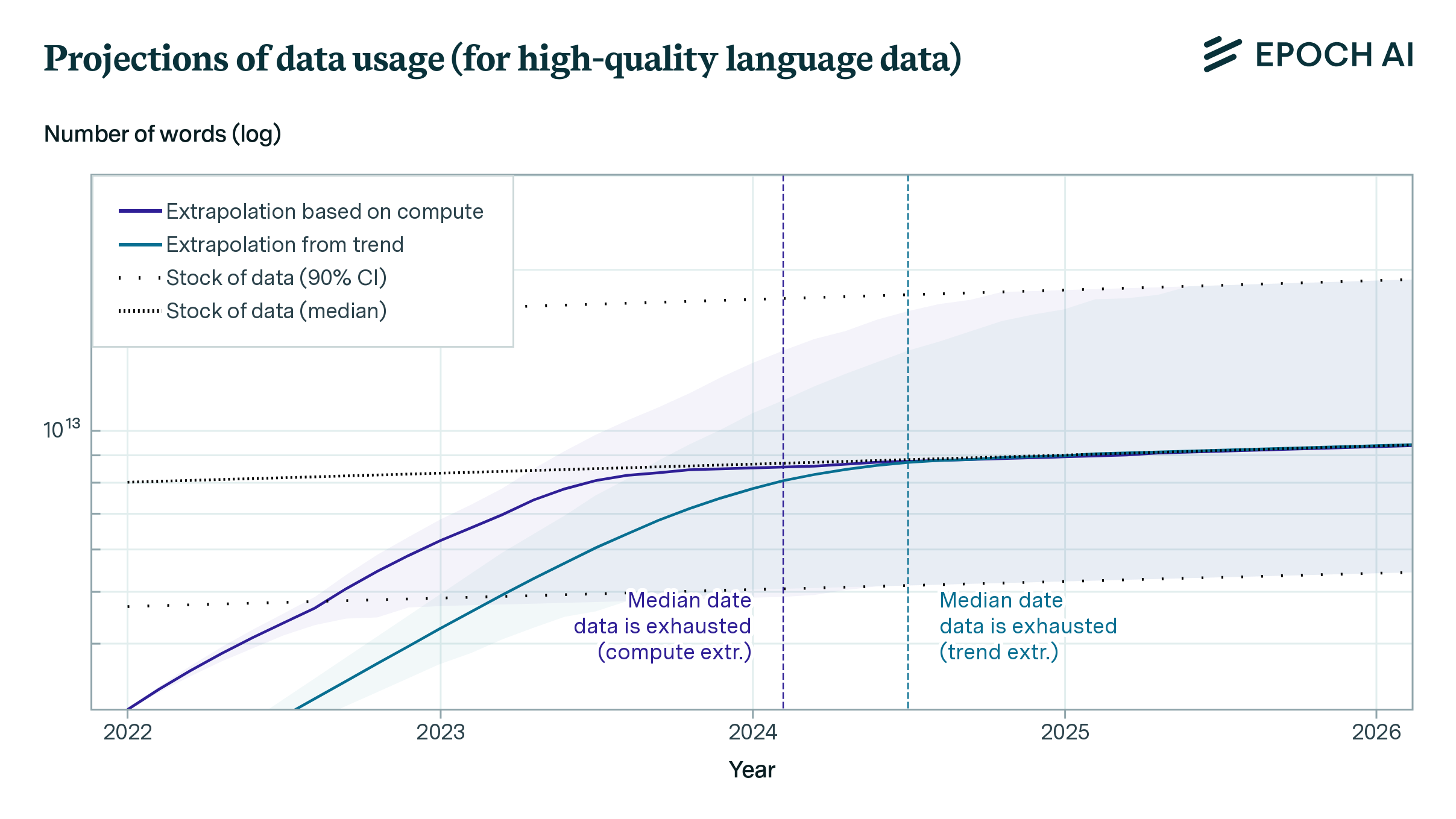
Will We Run Out of ML Data? Projecting Dataset Size Trends | Epoch AI
Based on our previous analysis of trends in dataset size, we project the growth of dataset size in the language and vision domains. We explore the limits of this trend by estimating the total stock of available unlabeled data over the next decades.| Epoch AI