
Modular: MAX GPU: State of the Art Throughput on a New GenAI platform
Measuring state of the art GPU performance compared to vLLM on Modular's MAX 24.6| www.modular.com
Measuring state of the art GPU performance compared to vLLM on Modular's MAX 24.6| www.modular.com

Learn how to deploy MAX pipelines to cloud| docs.modular.com

Create a GPU-enabled Kubernetes cluster with the cloud provider of your choice and deploy Llama 3.1 with MAX using Helm.| docs.modular.com

Learn how to use our benchmarking script to measure the performance of MAX.| docs.modular.com

Platforms like TensorFlow, PyTorch, and CUDA do not focus on modularity - there, we said it! They are sprawling technologies with thousands of evolving interdependent pieces that have grown organically into complicated structures over time. AI software developers must deal with this sprawl while deploying workloads to server, mobile devices, microcontrollers, and web browsers using multiple hardware platforms and accelerators.| www.modular.com
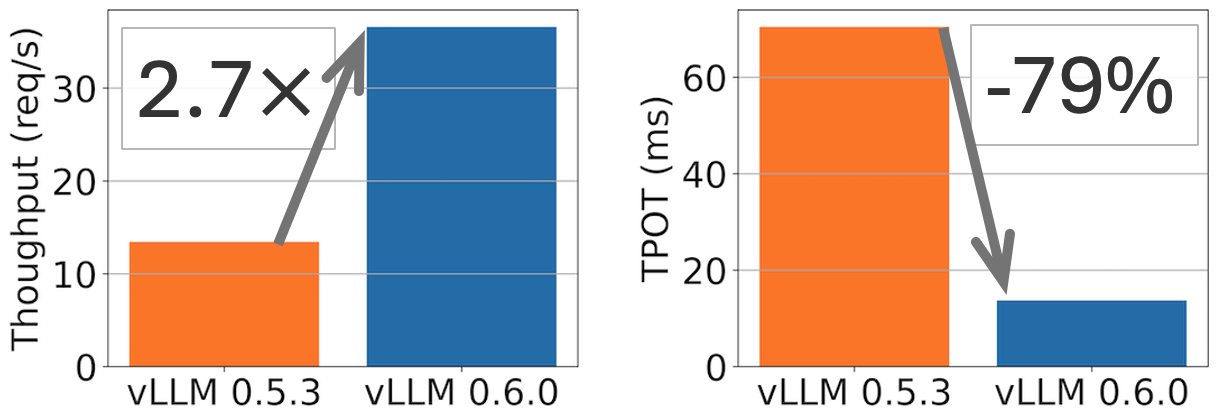
TL;DR: vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on Llama 8B model, and 1.8x higher throughput and 2x less TPOT on Llama 70B model.| vLLM Blog
