Login
From:
vLLM Blog
(Uncensored)
subscribe
vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction | vLLM Blog
https://blog.vllm.ai/2024/09/05/perf-update.html
links
backlinks
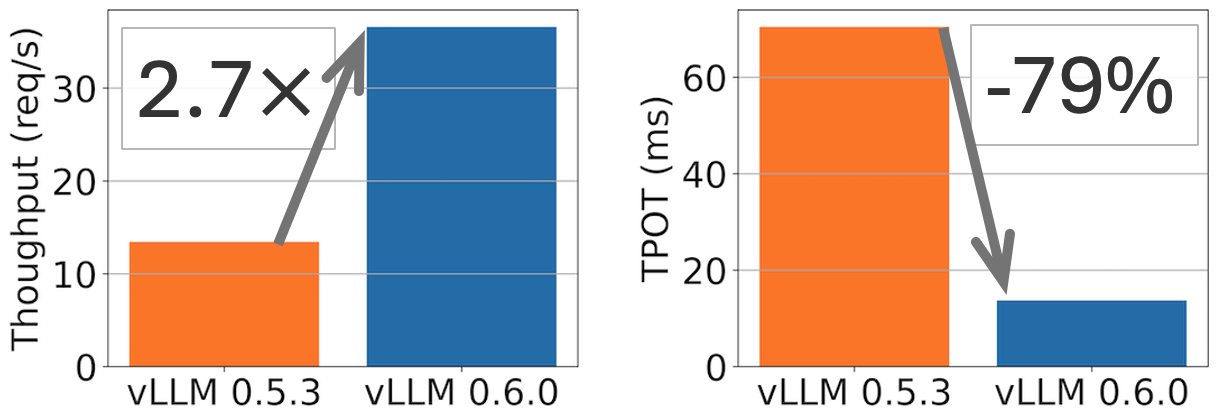
TL;DR: vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on Llama 8B model, and 1.8x higher throughput and 2x less TPOT on Llama 70B model.
Roast topics
Find topics
Roast it!
Roast topics
Find topics
Find it!
Roast topics
Find topics
Find it!