
anon8231489123/ShareGPT_Vicuna_unfiltered · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.| huggingface.co
We’re on a journey to advance and democratize artificial intelligence through open source and open science.| huggingface.co
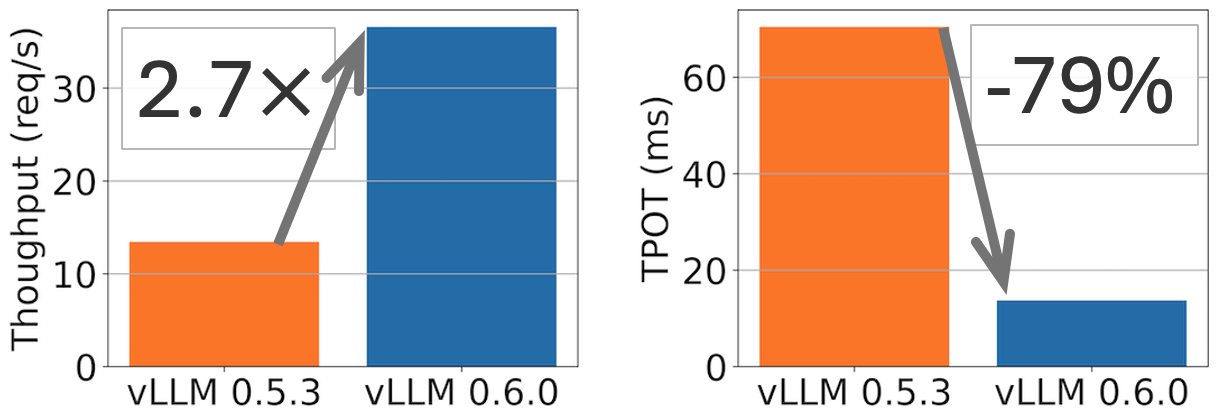
TL;DR: vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on Llama 8B model, and 1.8x higher throughput and 2x less TPOT on Llama 70B model.| vLLM Blog
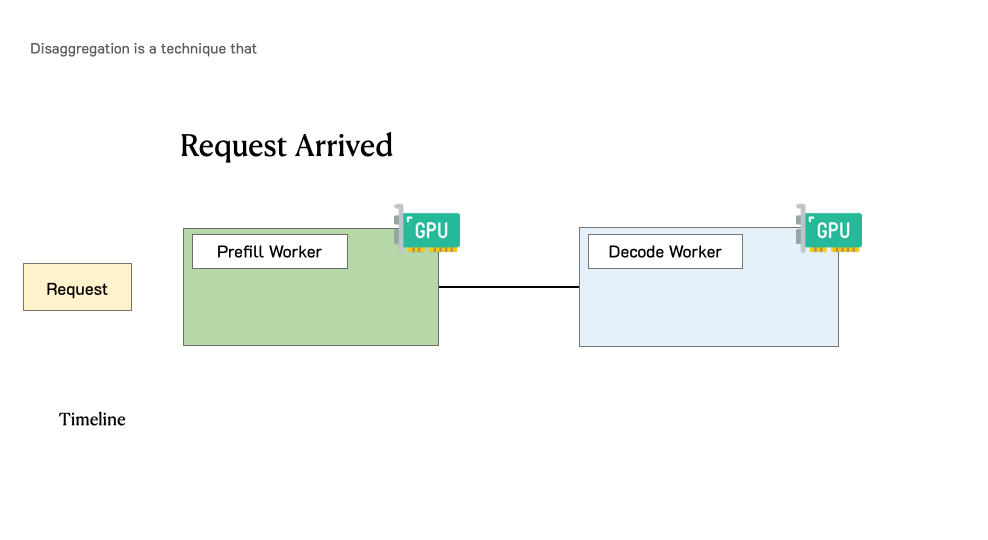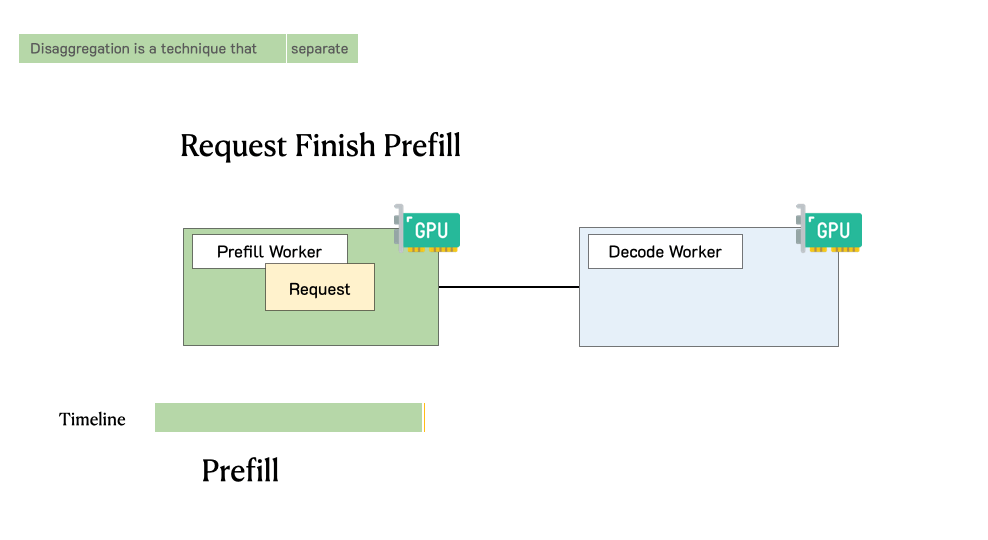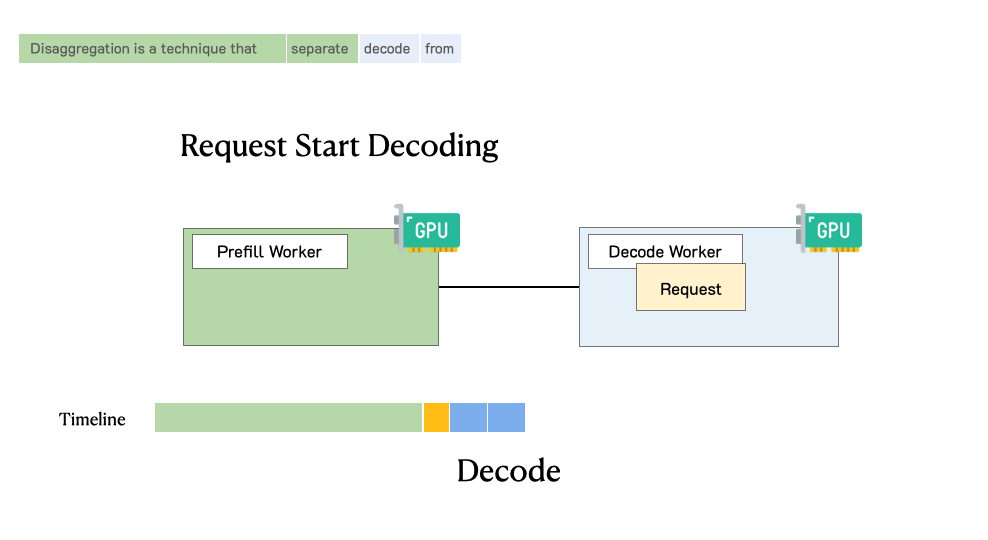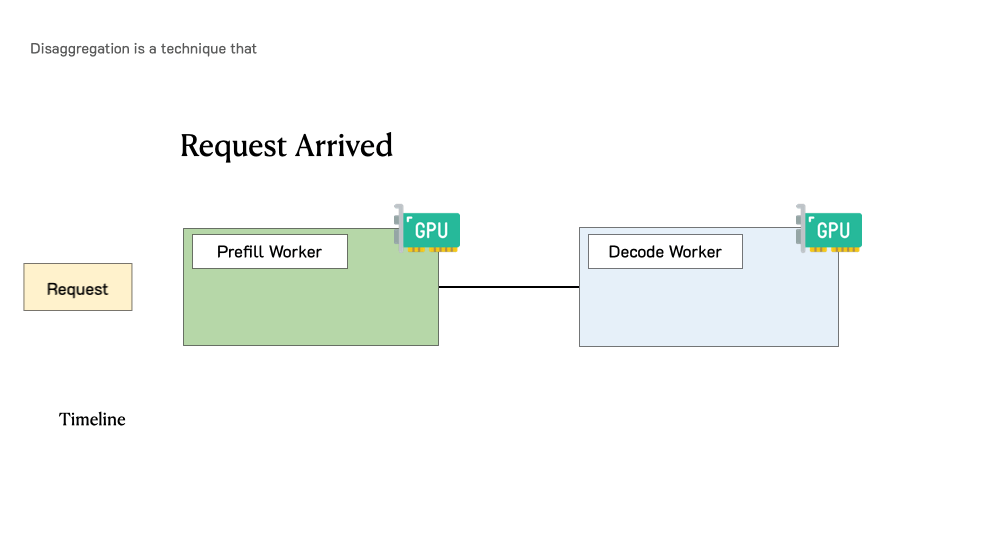
TL;DR: LLM apps today have diverse latency requirements. For example, a chatbot may require a fast initial response (e.g., under 0.2 seconds) but moderate speed in decoding which only needs to match human reading speed, whereas code completion requires a fast end-to-end generation time for real-time code suggestions. In this blog post, we show existing serving systems that optimize throughput are not optimal under latency criteria. We advocate using goodput, the number of completed requests p...| hao-ai-lab.github.io
