
Keep the System Prompt Clean: Why Developers Should Stop Mixing It With Project Instructions
How to separate system prompts from project instructions for better AI development workflow using standardized metadata files.| Seuros Blog
How to separate system prompts from project instructions for better AI development workflow using standardized metadata files.| Seuros Blog
I took the past week off to work on a little side project. More on that at some point, but at its heart it’s an extension of what I worked on with my translation package tinbox. (The new project uses translated sources to bootstrap a knowledge database.) Building in an environment which has less pressure / deadlines gives you space to experiment, so I both tried out a bunch of new tools and also experimented with different ways of using my tried-and-tested development tools/processes. Along...| Alex Strick van Linschoten
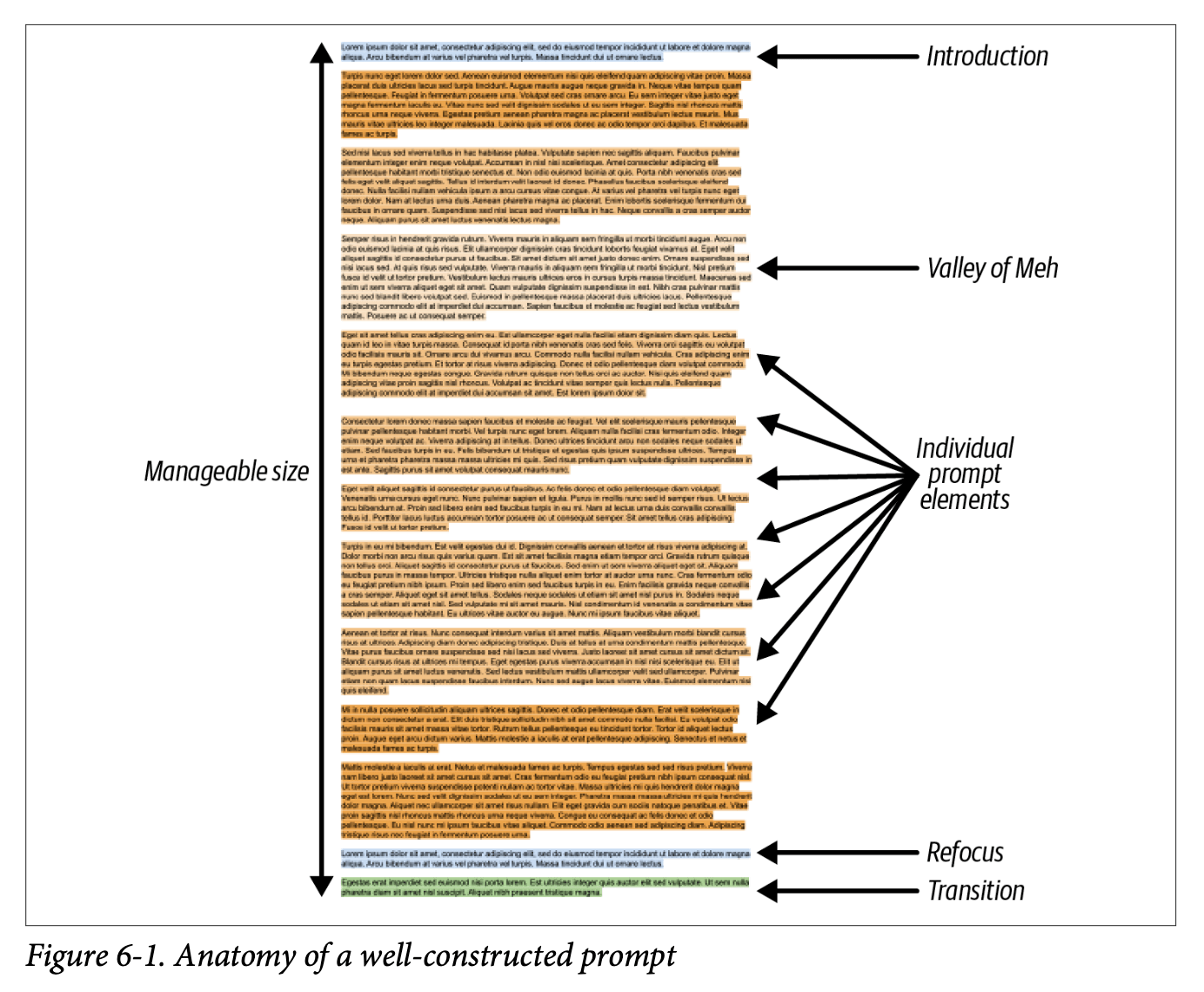
A detailed breakdown of Chapter 6 from 'Prompt Engineering for LLMs,' examining prompt structure, document types, and optimization strategies for effective prompt engineering, with practical tips on…| mlops.systems
Had the first of a series of meet-ups I’m organising in which we discuss Chip Huyen’s new book. My notes from reading the chapter follow this, and then I’ll try to summarise what we discussed in the group. At a high-level, I really enjoyed the final part of the chapter where she got into how she was thinking about the practice of ‘AI Engineering’ and how it differs from ML engineering. Also the use of the term ‘model adaptation’ was an interesting way of encompassing all the dif...| Alex Strick van Linschoten
Here are the final notes from ‘Prompt Engineering for LLMs’, a book I’ve been reading over the past few days (and enjoying!). Chapter 10: Evaluating LLM Applications The chapter begins with an interesting anecdote about GitHub Copilot - the first code written in their repository was the evaluation harness, highlighting the importance of testing in LLM applications. The authors, who worked on the project from its inception, emphasise this as a best practice. Evaluation Framework When eva...| Alex Strick van Linschoten
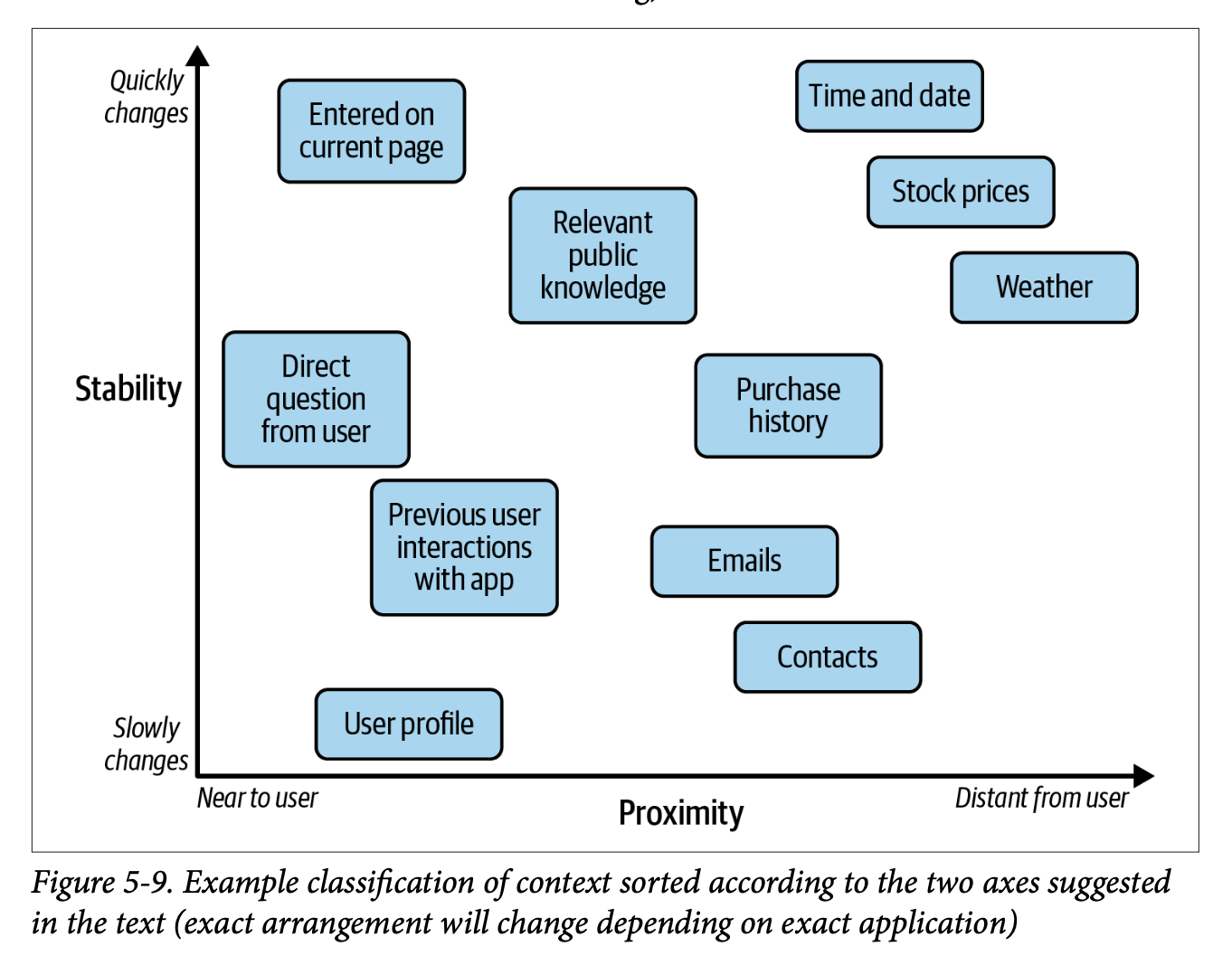
Chapter 5 of 'Prompt Engineering for LLMs' explores static content (fixed instructions and few-shot examples) versus dynamic content (runtime-assembled context like RAG) in prompts, offering…| mlops.systems
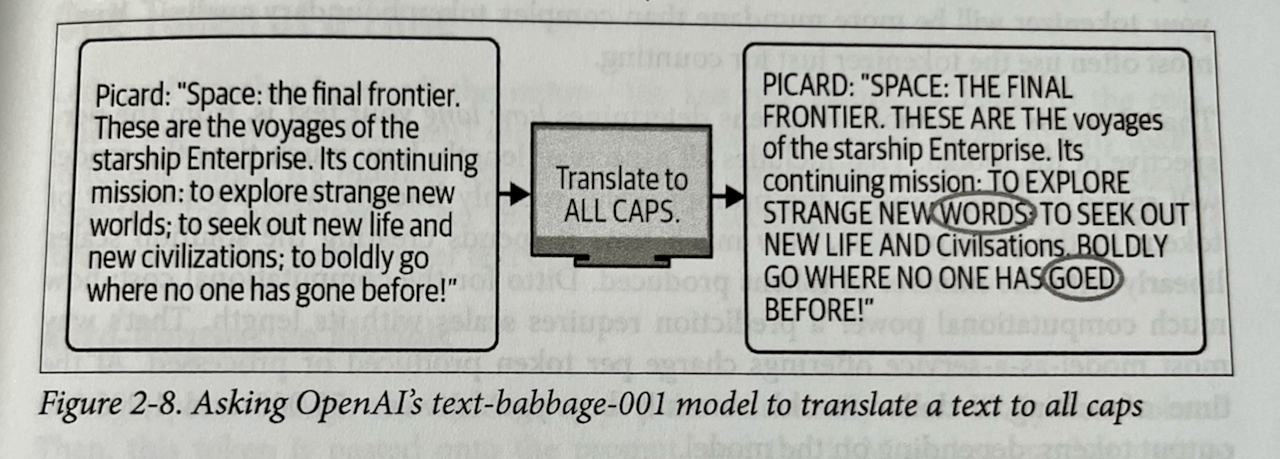
Summary notes from the first two chapters of 'Prompt Engineering for LLMs'.| mlops.systems

I was reading Concise Thoughts: Impact of Output Length on LLM Reasoning and Cost paper today and thought of applying it to a problem I solved a couple of months back. This paper introduced the Con…| Shekhar Gulati
