It takes a Kraken to scan billions of source files - Software Heritage
How CodeCommons uses SWH-fuse and the Kraken compressed graph to map open source: 8K files/sec and solving 10K process scaling.| Software Heritage
Queue scheduler announcement For the lifetime of the Apocrita HPC cluster, the queue scheduler software wehave been using to allocate jobs to individual compute nodes has been a variantof Grid Engine. Over the past few years, the company who own this software haschanged hands a few times, and we feel that development has stagnated in termsof features, while bugs have not been resolved to our satisfaction. The majority of HPC sites have been using the open source Slurm scheduler forsome time a...| QMUL ITS Research Blog
Reducing the maximum runtime for Open OnDemand sessions to 24 hours On Monday 3rd November 2025, we will be implementing a change to reduce themaximum runtime for all Open OnDemand applications from 240 hours (10 days) to24 hours. Over the past 12 months, we have observed a growing number of Open OnDemandsessions remaining idle for several days. These long-running, inactive sessionsoccupy valuable cluster resources, contributing to longer queueing times for allusers. As the number of Open OnD...| QMUL ITS Research Blog
brought to you by the ITS Research team at QMUL| blog.hpc.qmul.ac.uk
Mercedes-Benz passt die Preise seiner Ladetarife von MB.CHARGE in Deutschland an – dabei gibt es Änderungen in jeder Richtung. Während die Grundgebühr für den größten Ladetarif „Public L“ von 12,90 Euro auf 9,90 Euro gesenkt wird, gibt es deutliche Änderungen bei den Ladekosten sowie bei deren Übersichtlichkeit. Wer zukünftig mittels MB.CHARGE Ladetarif lädt, muss sich auf eine neue Preisstruktur bei Mercedes-Benz einstellen. Während die Grundegebühr für den MB.Charge Publi...| Mercedes-Benz Passion Blog mit smart, Maybach, AMG & EQ MBpassion
In the early years of High-Performance Computing (HPC), managing workloads across a cluster of machines was largely a manual effort. Users had to log into specific nodes, assign jobs by hand, and often write custom scripts to keep track of resources. While this approach was manageable in small labs with a handful of machines, it … continue reading The post Before Slurm: The Challenge of Managing Clusters appeared first on ITOps Times.| ITOps Times
Error parsing meta tag attribute “keywords”: No content.| AMD ROCm Blogs
This blog is part of a series of walkthroughs of Life Science AI models, stemming from this article.| AMD ROCm Blogs
How CodeCommons uses SWH-fuse and the Kraken compressed graph to map open source: 8K files/sec and solving 10K process scaling.| Software Heritage

Ultra Ethernet is Accelerating AI with Open Standards| Ultra Ethernet Consortium

Most of readers know that power of GPU changes the way of cheminformatics. I introduced nvMolkit which is developed by NVIDIA for cheminformatics tasks. Now we can handle huge amount of data in sho…| Is life worth living?

It has been clear for some time that Japan wants to have a certain amount of economic and technical independence when it comes to cloud computing in the| The Next Platform
Table of Contents External links The problem Initial solution: 105s First flamegraph Bytes instead of strings: 72s Manual parsing: 61s Inline hash keys: 50s Faster hash function: 41s A new flame graph Perf it is Something simple: allocating the right size: 41s memchr for scanning: 47s memchr crate: 29s get_unchecked: 28s Manual SIMD: 29s Profiling Revisiting the key function: 23s PtrHash perfect hash function: 17s Larger masks: 15s Reduce pattern matching: 14s Memory map: 12s Parallelization:...| CuriousCoding
I realise the title is a bit of a mouthful. It was either that or “No-copy IPC lock-free queue for variable length messages”. Naming is hard. DISCLAIMER: It’s not uncommon that one needs to send messages to another process as fast as possible, but 99% of the cases the best answer for that is boost::interprocess[1]. […]| ReachableCode
The EPICURE project was prominently featured at ISC High Performance 2025, the foremost European conference on high-performance computing (HPC), held in Hamburg, Germany, from June 10-13, […]| EPICURE
A story about writing high-performance code for a custom accelerator in a RISC-V CPU, with the help of some semi-automated tools.| SYSTEMF @ EPFL
brought to you by the ITS Research team at QMUL| blog.hpc.qmul.ac.uk
The post Laying the Groundwork for 2025: Sylabs’ Vision for Secure Multi-Cloud Solutions appeared first on Sylabs.| Sylabs
The post Sylabs Announces SingularityCE 4.1.0 with Enhanced Docker Integration and Advanced User Autonomy appeared first on Sylabs.| Sylabs
brought to you by the ITS Research team at QMUL| blog.hpc.qmul.ac.uk
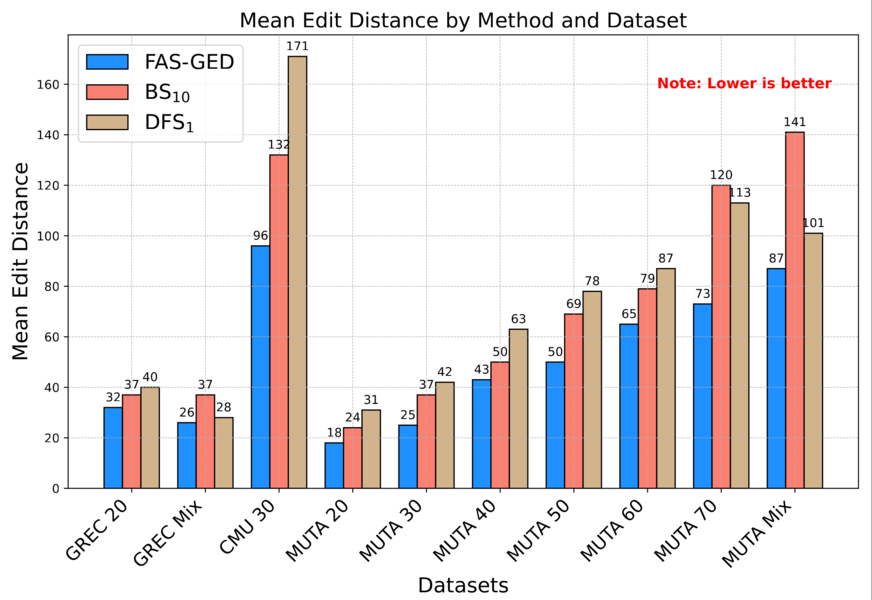
Poster in institute repository: https://doi.org/10.34734/FZJ-2024-06811| JSC Accelerating Devices Lab
Table of Contents Questions and remarks on PTHash paper Ideas for improvement Parameters Align packed vectors to cachelines Prefetching Faster modulo operations Store dictionary \(D\) sorted using Elias-Fano coding How many bits of \(n\) and hash entropy do we need? Ideas for faster construction Implementation log Hashing function Bitpacking crates Construction Fastmod TODO Try out fastdivide and reciprocal crates First benchmark Faster bucket computation Branchless, for real now! (aka the tr...| CuriousCoding
brought to you by the ITS Research team at QMUL| blog.hpc.qmul.ac.uk
For me, SC19 was about the fusion of machine learning and scientific computing. I learned about new technologies from Nvidia, Graphcore, and Cerebras Systems and spoke on a panel about the role of MLPerf in benchmarking HPC systems for machine learning and the many lessons learned. The post SuperComputing 19: HPC Meets Machine Learning appeared first on Real World Tech.| Real World Tech
brought to you by the ITS Research team at QMUL| blog.hpc.qmul.ac.uk

Benchmark Beasts Team to Compete at ISC25 Conference in Hamburg, Germany| PSC
Unification of Memory on the Grace Hopper Nodes The delivery of new GPUs for research is continuing, most notable is the newIsambard-AI cluster atBristol. As new cutting-edge GPUs are released, software engineers aretasked with being made aware of the new architectures and features these newGPUs offer. The new Grace-Hopper GH200 nodes, as announced in a previous blogpost, consist of a 72-core NVIDIA Grace CPU and anH100 Tensor Core GPU. One of the key innovations is the NVIDIA NVLinkChip-2-Ch...| QMUL ITS Research Blog
brought to you by the ITS Research team at QMUL| blog.hpc.qmul.ac.uk

In this post we present a brief preview of AMD's Next-Gen Fortran Compiler, our new open source Fortran complier optimized for AMD GPUs using OpenMP offloading, offering direct interface to ROCm and HIP.| ROCm Blogs

High Performance Computing Achievements Recognized by Peers, Editors of Leading Trade Press Magazine at SC24 Conference in Atlanta| PSC
Every couple of years, Lawrence Livermore National Laboratory gets to install the world’s fastest supercomputer. And thankfully the HPC center usually| The Next Platform
A Short Guide to PyTorch DDP In this blog post, we explore whattorchrun andDistributedDataParallelare and how they can be used to speed up your neural network training by usingmultiple GPUs. Neural networks, or even deep neural networks, are popular models for machinelearning. Mathematically, they can be interpreted as nested functions withmillions of parameters. If the parameters are tuned well, they can be used tomake predictions, such as when given a photo, it predicts what that photoconta...| QMUL ITS Research Blog

Nscale, a fully vertically integrated AI cloud platform, today announced the acquisition of Kontena, a leader in high-density modular data| Data Centre & Network News
This year’s ECTC, held at the end of May, will continue its focus on the role of packaging in keeping silicon scaling on track.| Tech Design Forum
Mil/aero specialist Abaco Systems refined its workflow across multiple design sites after the pandemic constrained collaboration.| Tech Design Forum
brought to you by the ITS Research team at QMUL| blog.hpc.qmul.ac.uk
On March 1st, I was speaking on NoSQL day meet up in Minsk, Belarus.| Alexey Ragozin

IBTA Releases Updated InfiniBand and RoCE Integrators List of Interoperable and Compliant Devices Demand for High-Performance Computing (HPC), Artificial Intelligence (AI) and Cloud infrastructures for compute and data intensive applications continues to grow while answering the call for faster interconnects to transfer massive amounts of data between servers and between servers and storage. To keep up with demand, the InfiniBand […]| RoCE Initiative
By Bill Lee The ever-increasing need for higher performance in the world of supercomputing demands interconnect solutions provide continuously faster speeds, lower latency and advanced telemetry and configuration options. The InfiniBand® Trade Association (IBTA) continues to meet these industry demands by providing enhancements to InfiniBand scalability and optimization. With the public availability of the InfiniBand Architecture Specification Volume 1 Release […]| RoCE Initiative
InfiniBand Architecture Specification Volume 1 Release 1.4 Includes Faster Network Signaling Rate, New Telemetry and Configuration Capabilities and an Integration of the RoCE and Virtualization Annexes BEAVERTON, Ore. – April 21, 2020 – The InfiniBand® Trade Association (IBTA), a global organization dedicated to maintaining and furthering the InfiniBand specification, today announced the public availability of the InfiniBand Architecture Specification […]| RoCE Initiative
By Rupert Dance This past April, the IBTA’s Plugfest 35 became the first event to both test and verify HDR 200Gb/s InfiniBand products, opening the door for high performance compute (HPC) systems to achieve new levels of speed and performance. This event, held at the University of New Hampshire Interoperability Laboratory (UNH-IOL), included thorough compliance and interoperability testing of each […]| RoCE Initiative

Virtual servers and physical servers both have advantages and disadvantages — but one of them comes out ahead for most companies.| ServerWatch
(Most of the hard work here was done by fellow blogger Rashmica - I just verified her instructions and wrote up this post.)| sthbrx.github.io
NAMD is a molecular dynamics program that can use GPU acceleration to speed up its calculations. Recent OpenPOWER machines like the IBM Power Systems S822LC for High Performance Computing (Minsky) come with a new interconnect for GPUs called NVLink, which offers extremely high bandwidth to a number of very powerful Nvidia Pascal P100 GPUs. So they're ideal machines for this sort of workload.| sthbrx.github.io
Introduction| sthbrx.github.io
はじめに 会社で,GCPとかAWSは仮想環境だし,ハードウェア環境が良くわからないからHPCの評価に使いたくないんだよねーみたいな話をしていたとき, そういえばこの話ってどこにも書いてないなと思ったので,常識なのかもしれないけど書いておく. 冒頭でネタバレをするとGCPではハイパースレッディングが有効なので,指定したコア数は物理コアとしては半分にな...| hpc::numa.blog()
20201217追記:よくよく読み返してみるとタイトルが「混合精度」なのに話してることが「高精度」だけで精度を混ぜる話なんにもしてないことに気づいたのでこっそり「前編」だったことにしました.後編は今度書きます. はじめに この記事は数値計算 Advent Calendar 2020の16日目の記事です. みなさん連立一次方程式解いてますか? この研究は脳筋マゾヒストが何も分か...| hpc::numa.blog()
はじめに この記事はスパコンポエムAdC202013日目の記事です. 山田先輩に誘われたはいいものの,私はQiitaのテーマカラーの緑が嫌いなので自分のブログに勝手に書きます. コメントしたいけどQiitaじゃないからコメントできない!!!と思った人はTwitterにでも書いてください.頑張って発掘します. 今回の記事はSX-Aurora TSUBASA (SXAT)です. SXATはスパコンじゃないだろっ...| hpc::numa.blog()
はじめに DD-AVX_v3という名前なのにv1.0とはこれいかに? ま,まぁとりあえずリリースしたんじゃよ githubから落としてこられる↓ https://github.com/t-hishinuma/DD-AVX_v3 DD-AVX_v3ってなに? 一言でいうとSIMDで高速化した倍精度とDouble-Double精度のSparse BLAS. 混合精度のKrylov部分空間法をいかに簡単かつ高速に実装できるかを考えて作ったライブラリ. 悪条件な問題を解こうとしたと...| hpc::numa.blog()
はじめに そろそろTwitterのフォロワーが2500人を迎えるそうです. やはりマイナーな世界だけを深堀りするのでなく, もっと大衆受けする活動をしていくべきだと思いました. そう,つまりマスに訴えかけることでHPC界のヒカキンのような存在になるのです. では皆が見てくれるような一般的な話題ってなんなのか? 私は考えました. google analyticsの結果を見るとこの...| hpc::numa.blog()
はじめに ちょっと前にすぐに導入方法とかコマンドを忘れて仕方がないので, bashrcに関数作ってGCPでよく使うコマンドを整理したので,忘れないうちにここに書いておく. テスト用なんかでマシンを立てて,ペペッとコマンド流したいときにやるための: マシン一覧取得 マシン起動・停止 マシン接続 マシン削除 という作業を瞬殺する バイナリをtar.gzで落としてく...| hpc::numa.blog()
TL; DR 検索するとCineBenchやゲーム系のベンチマークとかいう何をやっているのか良くわからん結果ばっかりで数値計算の役に立たないのしかでてこない. STREAMとDGEMM/SGEMMとFFTをCPUとGPUで回してくれるだけでいいんだ!と思うんだけど,冷静に考えるとそういうライブラリってベンチマーク機能が付いてるわけじゃない (てかSTREAMって使いにくいよね...). ベンチマーク...| hpc::numa.blog()
2011年,5月のリリースでgcc4.6から4倍精度が入った. 昔のブログで軽く使い方を書いたが他のサイトに情報があまり増えてなかったし,私の記事もできが悪かったのでこっちに移転したので改めてまとめてみた. 使い方 簡単な使い方としては, libquadmathを使うことになる. __float128 型を宣言して使う.倍精度を代入して使うこともできる. 4倍精度数を表現したい場合に...| hpc::numa.blog()

Background My dotfiles turned 4 years old a few months ago (since 9th Jan 2017) and remains one of my most frequently updated projects for obvious reasons. Going through the changes reminds me of a whole of posts I never got around to writing. Anyway, recently I gained access to another HPC cluster, with a standard configuration (bash, old CentOS) and decided to track my provisioning steps. This is really a very streamlined experience by now, since I’ve used the same setup across scores of ...| Rohit Goswami
