
DeepSeek-V3.2-Exp in vLLM: Fine-Grained Sparse Attention in Action | vLLM Blog
Introduction| vLLM Blog
vLLM is a fast and easy-to-use library for LLM inference and serving.| vLLM Blog
Introduction| vLLM Blog
Introduction| vLLM Blog
| vLLM Blog
We’re excited to announce that vLLM now supports Qwen3-Next, the latest generation of foundation models from the Qwen team. Qwen3-Next introduces a hybrid architecture with extreme efficiency for long context support, and vLLM offers full support of its functionalities.| vLLM Blog
[!NOTE] Originally posted on Aleksa Gordic’s website.| vLLM Blog
Introduction| vLLM Blog
[!NOTE] This blog originated from our biweekly vLLM office hours, a community forum hosted by Red Hat with vLLM project committers and the UC Berkeley team. Each session covers recent updates, a deep dive with a guest speaker, and open Q&A. Join us every other Thursday at 2:00 PM ET / 11:00 AM PT on Google Meet, and get the recording and slides afterward on our YouTube playlist.| vLLM Blog
We’re thrilled to announce that vLLM now supports gpt-oss on NVIDIA Blackwell and Hopper GPUs, as well as AMD MI300x and MI355x GPUs. In this blog post, we’ll explore the efficient model architecture of gpt-oss and how vLLM supports it.| vLLM Blog
vLLM is a fast and easy-to-use library for LLM inference and serving.| vLLM Blog
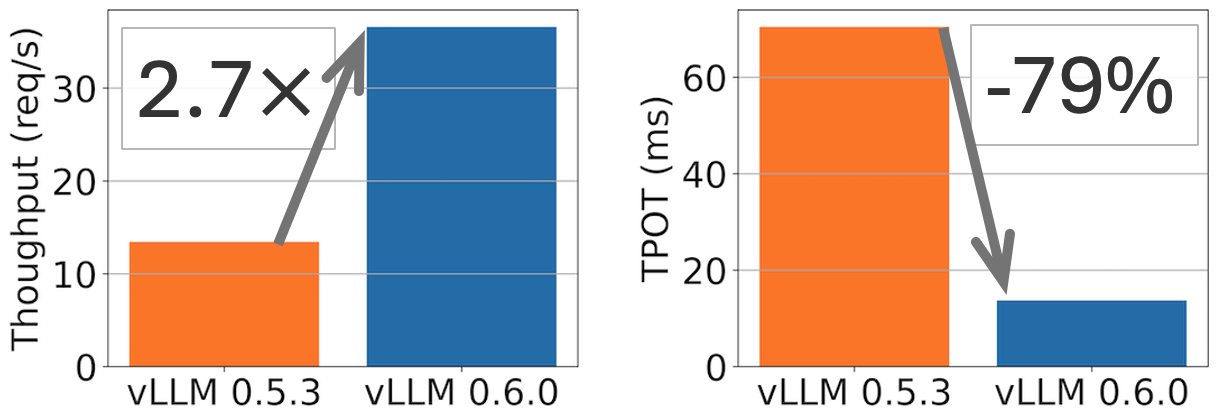
TL;DR: vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on Llama 8B model, and 1.8x higher throughput and 2x less TPOT on Llama 70B model.| vLLM Blog
GitHub | Documentation | Paper| vLLM Blog
