I previously tried (and failed) to setup LLM tracing for hinbox using Arize Phoenix and litellm. Since this is sort of a priority for being able to follow along with the Hamel / Shreya evals course with my practical application, I’ll take another stab using a tool with which I’m familiar: Braintrust. Let’s start simple and then if it works the way we want we can set things up for hinbox as well. Simple Braintrust tracing with litellm callbacks Callbacks are listed in the litellm docs as...| Alex Strick van Linschoten
It’s important to instrument your AI applications! I hope this can more or less be taken as given just as you’d expect a non-AI-infused app to capture logs. When you’re evaluating your LLM-powered system, you need to have capture the inputs and outputs both at an end-to-end level in terms of the way the user experiences things as well as with more fine-grained granularity for all the internal workings. My goal with this blog is to first demonstrate how Phoenix and litellm can work toget...| Alex Strick van Linschoten
I’ve been working on a project called hinbox - a flexible entity extraction system designed to help historians and researchers build structured knowledge databases from collections of primary source documents. At its core, hinbox processes historical documents, academic papers, books and news articles to automatically extract and organize information about people, organizations, locations, and events. The tool works by ingesting batches of documents and intelligently identifying entities ac...| Alex Strick van Linschoten
I took the past week off to work on a little side project. More on that at some point, but at its heart it’s an extension of what I worked on with my translation package tinbox. (The new project uses translated sources to bootstrap a knowledge database.) Building in an environment which has less pressure / deadlines gives you space to experiment, so I both tried out a bunch of new tools and also experimented with different ways of using my tried-and-tested development tools/processes. Along...| Alex Strick van Linschoten
Large Language Models have transformed how we interact with text, offering capabilities that seemed like science fiction just a few years ago. They can write poetry, generate code, and engage in sophisticated reasoning. Yet surprisingly, one seemingly straightforward task – document translation – remains a significant challenge. This is a challenge I understand intimately, both as a developer and as a historian who has spent years working with multilingual primary sources. Before the era ...| Alex Strick van Linschoten
I spent the morning building an MCP server for Beeminder, bridging the gap between AI assistants and my personal goal tracking data. This project emerged from a practical need — ok, desire :) — to interact more effectively with my Beeminder data through AI interfaces like Claude Desktop and Cursor. The MCP-Beeminder mashup in action! Understanding Beeminder For those unfamiliar with Beeminder, it’s a tool that combines self-tracking with commitment devices to help users achieve their go...| Alex Strick van Linschoten
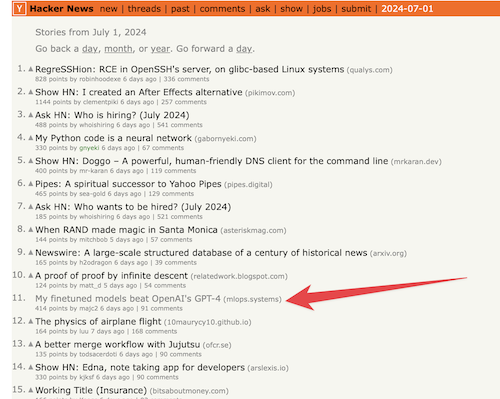
I was on the front page of Hacker News for my two last blog posts and I learned various things forom the discussion and scrutiny of my approach to evaluating my finetuned LLMs.| mlops.systems
I tried out some services that promise to simplify the process of finetuning open models. I describe my experiences with Predibase, OpenPipe and OpenAI.| mlops.systems
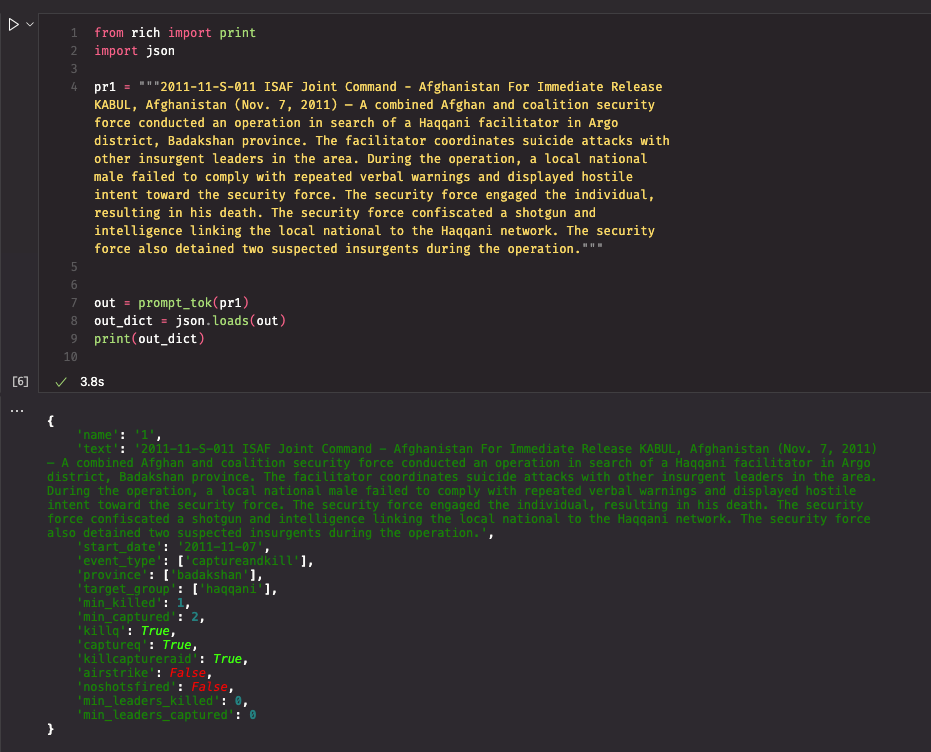
I finetuned my first LLM(s) for the task of extracting structured data from ISAF press releases. Initial tests suggest that it worked pretty well out of the box.| mlops.systems
I used Instructor to understand how well LLMs are at extracting data from the ISAF Press Releases dataset. They did pretty well, but not across the board.| mlops.systems
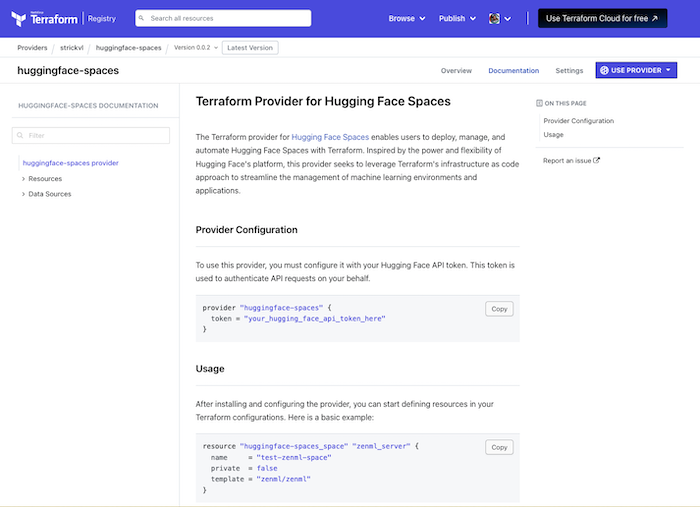
I worked on this short project to allow people to create/deploy Huggingface Spaces using Terraform (instead of via the API or using the website)| mlops.systems