Alex Strick van Linschoten - MLOps.systems Blog
Testing out instrumenting LLM tracing for litellm with Braintrust and Langfuse| mlops.systems
Testing out instrumenting LLM tracing for litellm with Braintrust and Langfuse| mlops.systems
I previously tried (and failed) to setup LLM tracing for hinbox using Arize Phoenix and litellm. Since this is sort of a priority for being able to follow along with the Hamel / Shreya evals course with my practical application, I’ll take another stab using a tool with which I’m familiar: Braintrust. Let’s start simple and then if it works the way we want we can set things up for hinbox as well. Simple Braintrust tracing with litellm callbacks Callbacks are listed in the litellm docs as...| Alex Strick van Linschoten
It’s important to instrument your AI applications! I hope this can more or less be taken as given just as you’d expect a non-AI-infused app to capture logs. When you’re evaluating your LLM-powered system, you need to have capture the inputs and outputs both at an end-to-end level in terms of the way the user experiences things as well as with more fine-grained granularity for all the internal workings. My goal with this blog is to first demonstrate how Phoenix and litellm can work toget...| Alex Strick van Linschoten
I’ve been working on a project called hinbox - a flexible entity extraction system designed to help historians and researchers build structured knowledge databases from collections of primary source documents. At its core, hinbox processes historical documents, academic papers, books and news articles to automatically extract and organize information about people, organizations, locations, and events. The tool works by ingesting batches of documents and intelligently identifying entities ac...| Alex Strick van Linschoten
I came across this quote in a happy coincidence after attending the second session of the evals course: It’s obviously a bit abstract, but I thought it was a nice oblique reflection on the topic being discussed. Both the main session and the office hours were mostly focused on the first part of the analyse-measure-improve loop that was introduced earlier in the week. Focus on the ‘analyse’ part of the LLM application improvement loop It was a very practical session in which we even took...| Alex Strick van Linschoten

Key insights from the first session of the Hamel/Shreya AI Evals course, focusing on a 'three gulfs' mental model (specification, generalisation, and comprehension) for LLM application development…| mlops.systems
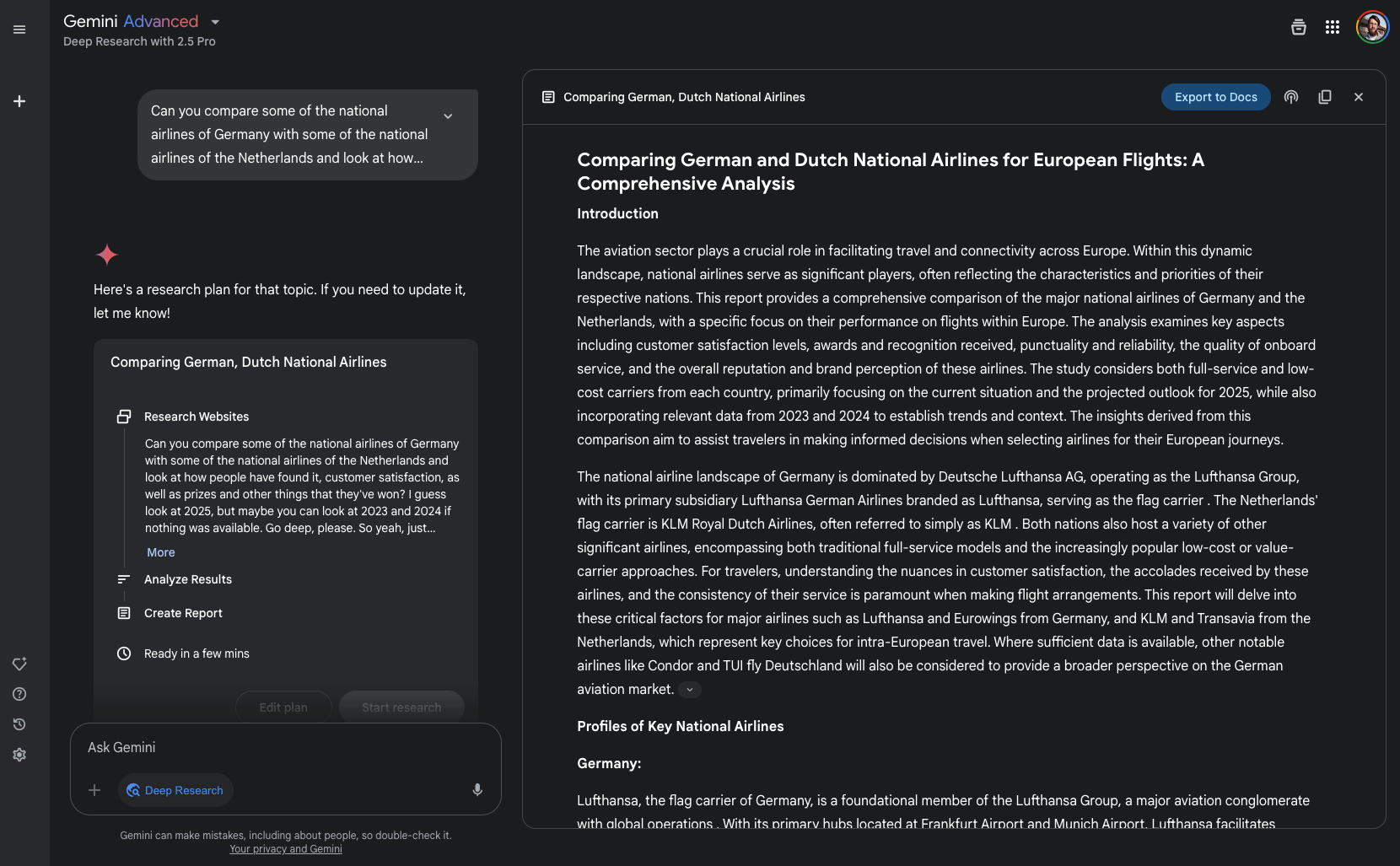
Some initial fast impressions of Google Deepmind's new iteration of Gemini Deep Research that uses their 2.5 Pro model.| mlops.systems
I took the past week off to work on a little side project. More on that at some point, but at its heart it’s an extension of what I worked on with my translation package tinbox. (The new project uses translated sources to bootstrap a knowledge database.) Building in an environment which has less pressure / deadlines gives you space to experiment, so I both tried out a bunch of new tools and also experimented with different ways of using my tried-and-tested development tools/processes. Along...| Alex Strick van Linschoten
Large Language Models have transformed how we interact with text, offering capabilities that seemed like science fiction just a few years ago. They can write poetry, generate code, and engage in sophisticated reasoning. Yet surprisingly, one seemingly straightforward task – document translation – remains a significant challenge. This is a challenge I understand intimately, both as a developer and as a historian who has spent years working with multilingual primary sources. Before the era ...| Alex Strick van Linschoten
I enjoyed chapter 7 on finetuning. It jams a lot of detail into the 50 pages she takes to explain things. Some areas had more detail than you’d expect, and others less, but overall this was a solid summary / review. Core Narrative: Fine-tuning represents a significant technical and organisational investment that should be approached as a last resort, not a first solution. The chapter’s essential message can be distilled into three key points: The decision to fine-tune should follow exhaus...| Alex Strick van Linschoten
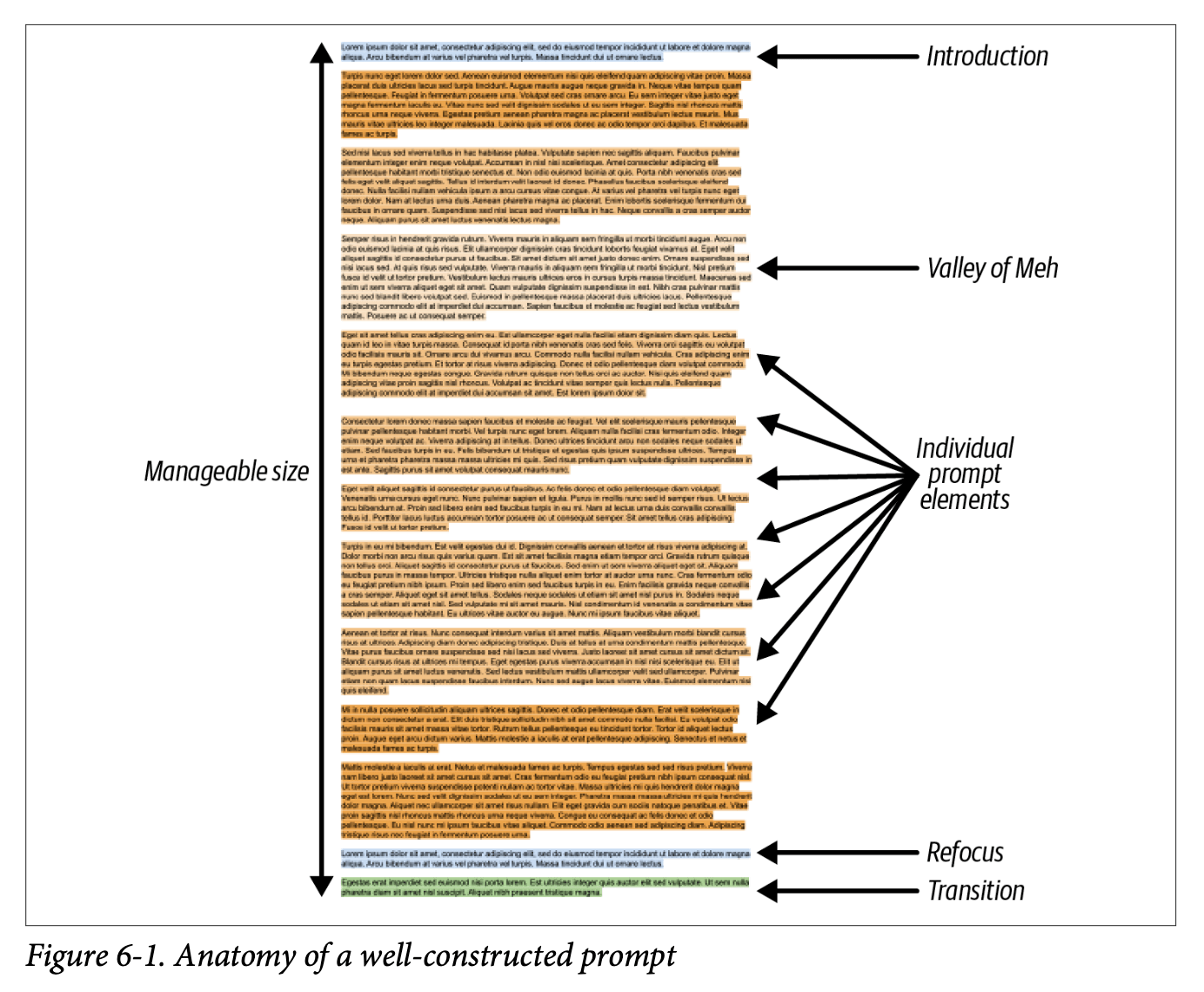
A detailed breakdown of Chapter 6 from 'Prompt Engineering for LLMs,' examining prompt structure, document types, and optimization strategies for effective prompt engineering, with practical tips on…| mlops.systems
I spent the morning building an MCP server for Beeminder, bridging the gap between AI assistants and my personal goal tracking data. This project emerged from a practical need — ok, desire :) — to interact more effectively with my Beeminder data through AI interfaces like Claude Desktop and Cursor. The MCP-Beeminder mashup in action! Understanding Beeminder For those unfamiliar with Beeminder, it’s a tool that combines self-tracking with commitment devices to help users achieve their go...| Alex Strick van Linschoten
I finished the first unit of the Hugging Face Agents course, at least the reading part. I still want to play around with the code a bit more, since I imagine we’ll be doing that more going forward. In the meanwhile I wanted to write up some reflections on the course materials from unit one, in no particular order… Code agents’ prominence The course materials and smolagents in general places special emphasis on code agents, citing multipleresearchpapers and they seem to make some solid a...| Alex Strick van Linschoten
Chapter 10 of Chip Huyen’s “AI Engineering,” focuses on two fundamental aspects: architectural patterns in AI engineering and methods for gathering and using user feedback. The chapter presents a progressive architectural framework that evolves from simple API calls to complex agent-based systems, while also diving deep into the crucial aspect of user feedback collection and analysis. 1. Progressive Architecture Patterns The evolution of AI engineering architecture typically follows a p...| Alex Strick van Linschoten
What follows are my notes on chapter 9 of Chip Huyen’s ‘AI Engineering’ book. This chapter was on optimising your inference and I learned a lot while reading it! There are interesting techniques like prompt caching and architectural considerations that I was vaguely aware of but hadn’t fully appreciated how they might work in real inference systems. Chapter 9: Overview Machine learning inference optimization operates across three fundamental domains: model optimization, hardware optim...| Alex Strick van Linschoten
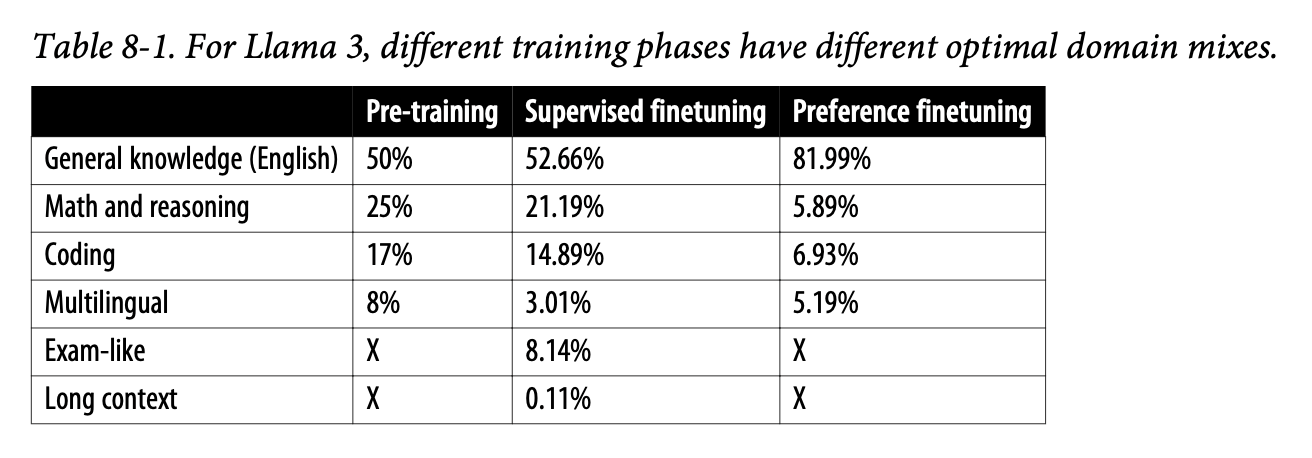
Explores Chapter 8 of Chip Huyen's 'AI Engineering,' examining the intricate landscape of dataset engineering through the lenses of curation, augmentation, and processing.| mlops.systems
This chapter was all about RAG and agents. It’s only 50 pages, so clearly there’s only so much of the details she can get into, but it was pretty good nonetheless and there were a few things in here I’d never really read. Also Chip does a good job bringing the RAG story into the story about agents, particularly in terms of how she defines agents. (Note that the second half of this chapter, on agents, is available on Chip’s blog as a free excerpt!) As always, what follows is just my no...| Alex Strick van Linschoten
This chapter represents a crucial bridge between academic research and production engineering practice in AI system evaluation. What sets it apart is the Chip’s very balanced perspective - neither succumbing to the prevalent hype in the field nor becoming overly academic. Instead, she melds together practical insights with theoretical foundations, creating a useful framework for evaluation that acknowledges both technical and ethical considerations. Introduction and Context Key Insight: The...| Alex Strick van Linschoten
Really enjoyed this chapter. My tidied notes from my readings follow below. 150 pages in and we’re starting to get to the good stuff :) Overview and Context This chapter serves as the first of two chapters (Chapters 3 and 4) dealing with evaluation in AI Engineering. While Chapter 4 will delve into evaluation within systems, Chapter 3 addresses the fundamental question of how to evaluate open-ended responses from foundation models and LLMs at a high level. The importance of evaluation canno...| Alex Strick van Linschoten
Had the first of a series of meet-ups I’m organising in which we discuss Chip Huyen’s new book. My notes from reading the chapter follow this, and then I’ll try to summarise what we discussed in the group. At a high-level, I really enjoyed the final part of the chapter where she got into how she was thinking about the practice of ‘AI Engineering’ and how it differs from ML engineering. Also the use of the term ‘model adaptation’ was an interesting way of encompassing all the dif...| Alex Strick van Linschoten
Here are the final notes from ‘Prompt Engineering for LLMs’, a book I’ve been reading over the past few days (and enjoying!). Chapter 10: Evaluating LLM Applications The chapter begins with an interesting anecdote about GitHub Copilot - the first code written in their repository was the evaluation harness, highlighting the importance of testing in LLM applications. The authors, who worked on the project from its inception, emphasise this as a best practice. Evaluation Framework When eva...| Alex Strick van Linschoten
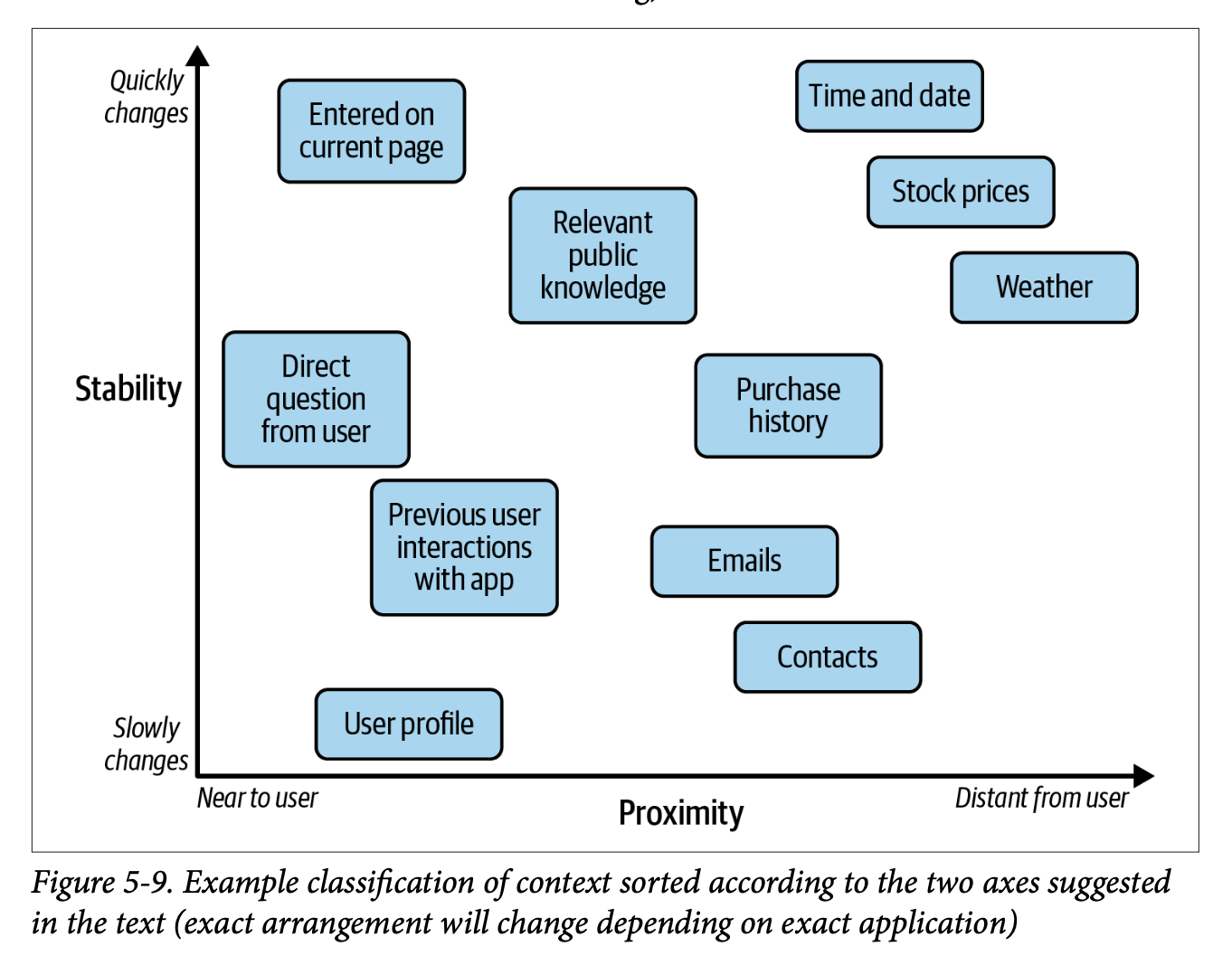
Chapter 5 of 'Prompt Engineering for LLMs' explores static content (fixed instructions and few-shot examples) versus dynamic content (runtime-assembled context like RAG) in prompts, offering…| mlops.systems
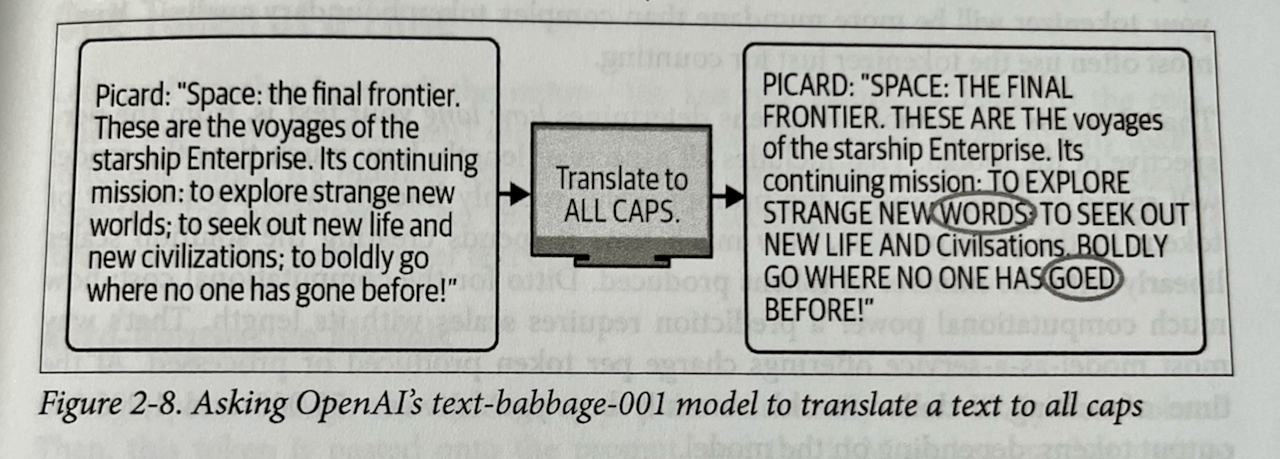
Summary notes from the first two chapters of 'Prompt Engineering for LLMs'.| mlops.systems
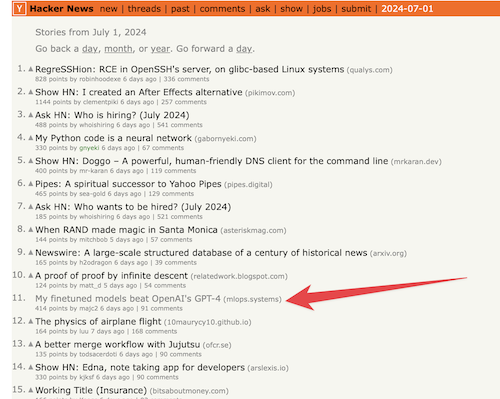
I was on the front page of Hacker News for my two last blog posts and I learned various things forom the discussion and scrutiny of my approach to evaluating my finetuned LLMs.| mlops.systems
I summarise the kinds of evaluations that are needed for a structured data generation task.| mlops.systems

I tried out some services that promise to simplify the process of finetuning open models. I describe my experiences with Predibase, OpenPipe and OpenAI.| mlops.systems
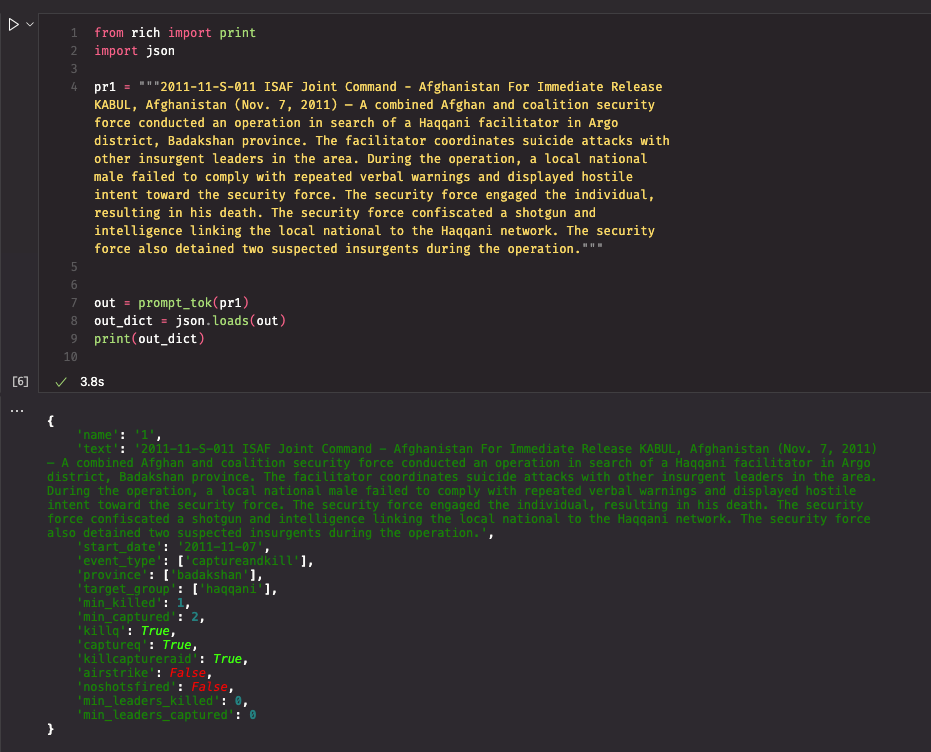
I finetuned my first LLM(s) for the task of extracting structured data from ISAF press releases. Initial tests suggest that it worked pretty well out of the box.| mlops.systems

I evaluated the baseline performance of OpenAI's GPT-4-Turbo on the ISAF Press Release dataset.| mlops.systems

I used Instructor to understand how well LLMs are at extracting data from the ISAF Press Releases dataset. They did pretty well, but not across the board.| mlops.systems

I'm publishing a unique new dataset of Afghan newspaper and magazine articles from the 2006-2009 period.| mlops.systems
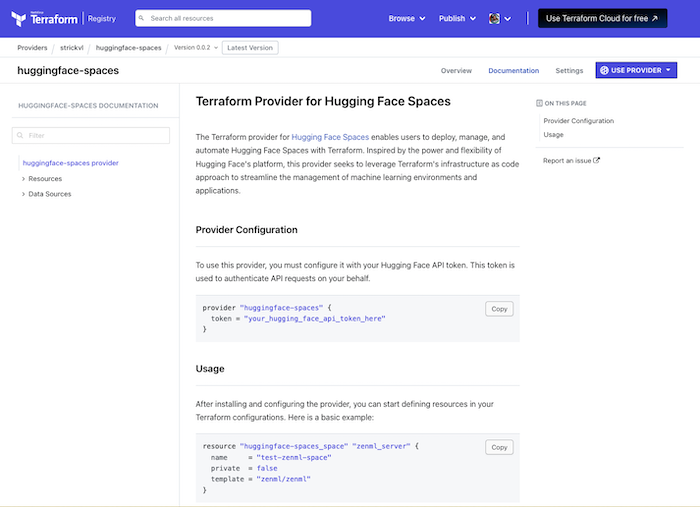
I worked on this short project to allow people to create/deploy Huggingface Spaces using Terraform (instead of via the API or using the website)| mlops.systems

I published a dataset from my previous work as a researcher in Afghanistan.| mlops.systems

I built a tool to help me practice the parts of mathematics that I find hardest.| mlops.systems

All the ways you can set input and local variables when using Terraform.| mlops.systems
I explore language tokenization using FastAI, Spacy, and Huggingface Tokenizers, with a special focus on the less-represented Balochi language.| mlops.systems

The basics around the tokenisation process: why we do it, the spectrum of choices when you get to choose how to do it, and the family of algorithms most commonly used at the moment.| mlops.systems
I share my journey of building language models for Balochi, a language with few digital resources. I discuss assembling a dataset of 2.6 million Balochi words.| mlops.systems

The dual-edged nature of developing a language model for the Balochi language, weighing potential benefits like improved communication, accessibility, and language preservation against serious risks…| mlops.systems

The Balochi language is underrepresented in NLP.| mlops.systems

I completed the first module from my maths degree with the Open University. Highlights were quadratic equations, trigonometry and exponential functions.| mlops.systems

I delved into exponents and logarithms in my Open University Maths degree, discovering their practical applications and connections to concepts like Euler's number.| mlops.systems
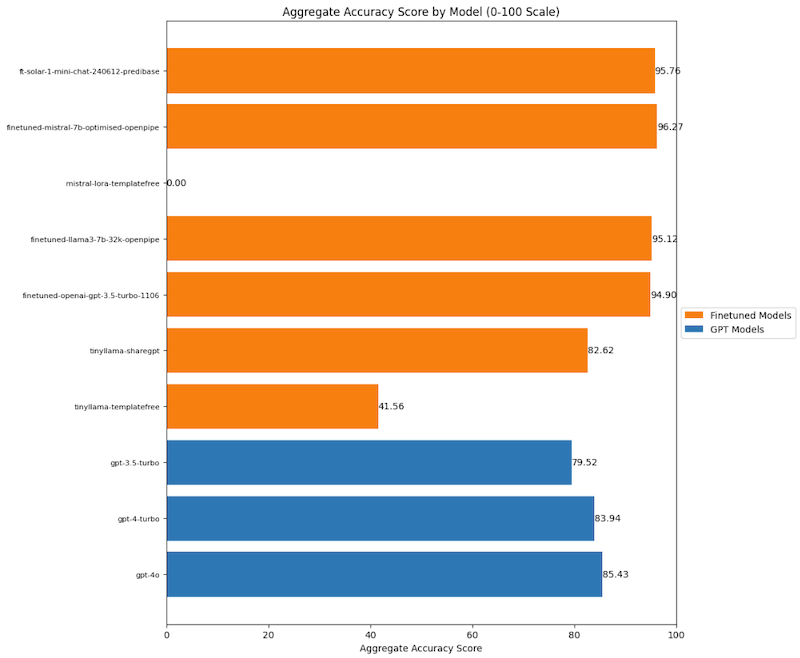
Finetunes of Mistral, Llama3 and Solar LLMs are more accurate for my test data than OpenAI's models.| mlops.systems
