今回から何回かに渡ってBayesian Factorization Machines(BFM)関連の記事を書いていこうと思います。まずは、基本となる連続値を目的変数としたBFMのギブスサンプリング実装について、3回に分けて説明します。BFMの技術要素は、(1)線形モデルのギブスサンプリング、(2)階層ベイズ、(3)交互作用項の高速計算から成り立っており、それぞれバイアス項、ハイパーパラメータ、交...| LIVESENSE Data Analytics Blog
今回は、マッチングアルゴリズムとして有名なGale-Shapleyアルゴリズムを扱います。今回の記事ではアルゴリズムをそのまま実装したものを紹介し、次回の記事で計算速度を考慮した実装を紹介します。なお、弊社サービス[knew](https://knew.jp)が始まった頃にユーザーの急増に備えて書いたコードが元ネタですが、残念ながら今回および次回紹介するコードは現在のknewでは...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は事前分布にLKJ相関分布を利用したBPMF(Bayesian Probalibistic Matrix Factorization)を扱います。元のBPMF(Salakhutdinov et al. 2008)では因子行列の分散共分散行列の事前分布にWishart分布を使っています。しかし、Wishart分布を利用すると推定値にバイアスが生じるなど問題があることが知られています。一方...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は5年ぶりにBPMF(Bayesian Probabilistic Matrix Factorization)を扱います。5年前は論文の内容をそのままギブスサンプリングで実装しましたが、今回は同じモデルをStanで実装します。BPMFのポイントは因子行列の分散の扱いにあります。今回もBPMFの特徴がわかりやすくなるようにPMF(Probabilistic Matrix Fact...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回も分散共分散行列のベイズ推定を扱います。以前の記事で分散共分散行列の事前分布に逆Wishart分布を使うと、推定対象の分散が小さいときに推定バイアスが生じることを紹介しました。では、どのような事前分布を使ったらよいかというのが今回の内容です。記事タイトルからも推測できる...| LIVESENSE Data Analytics Blog
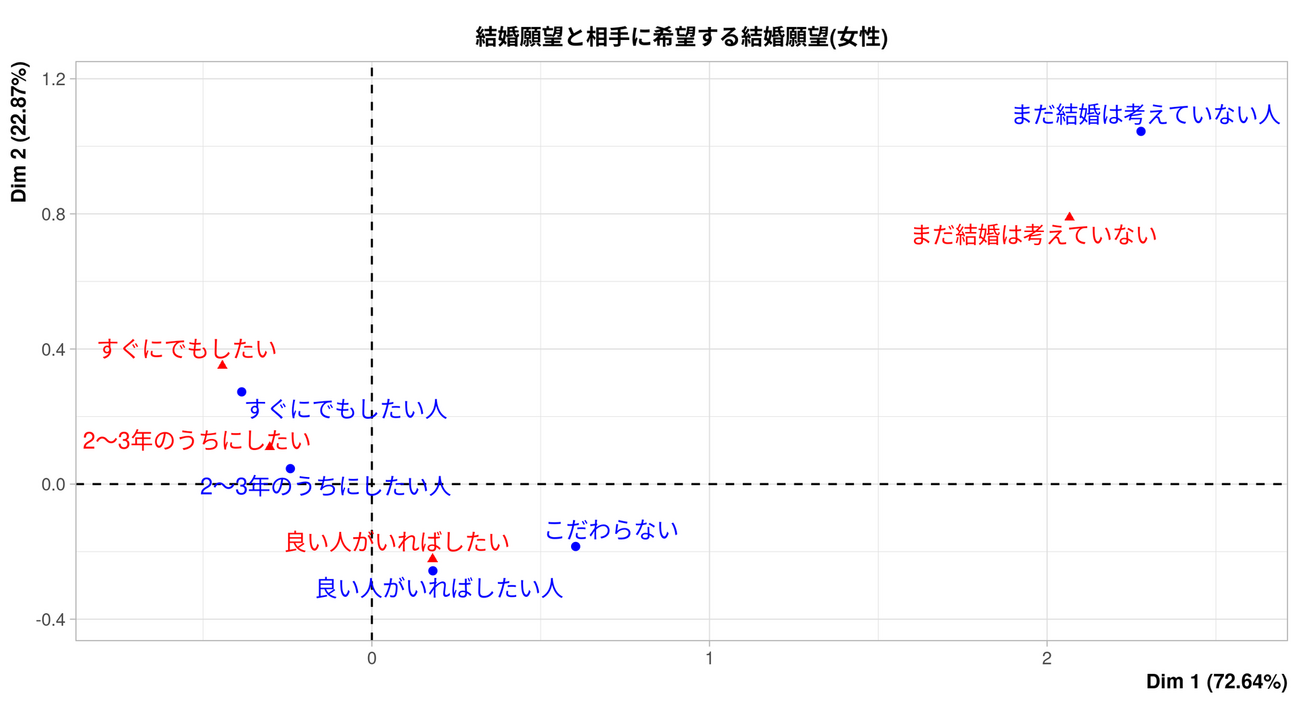
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は対応分析の利用事例として、紹介型マッチングアプリknewの結婚観の特徴を分析した結果を紹介します。対応分析は2カテゴリーの項目間の関係性を視覚的に把握する方法です。主に探索的分析で使われます。なお、対応分析については別記事にて紹介します。 knewは結婚につながる真剣な恋...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回も以前の記事に続き、分散共分散行列のベイズ推定を扱います。今回は、逆Wishart分布を事前分布として分散共分散行列を推定するときに生じる問題を取り上げます。分散共分散行列の事前分布としては逆Wishart分布が有名ですが、扱う問題によっては事後分布にバイアスが生じ不適切な推定結...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は、多変量正規分布の分散共分散行列を扱うときに有用であることが知られているコレスキー分解を取り上げます。 多変量正規分布を使ったモデリングをしたいことはよくありますが、複雑な分布であるため計算時間が長くなりやすかったり不安定になりやすかったりします。コレスキー分...| LIVESENSE Data Analytics Blog
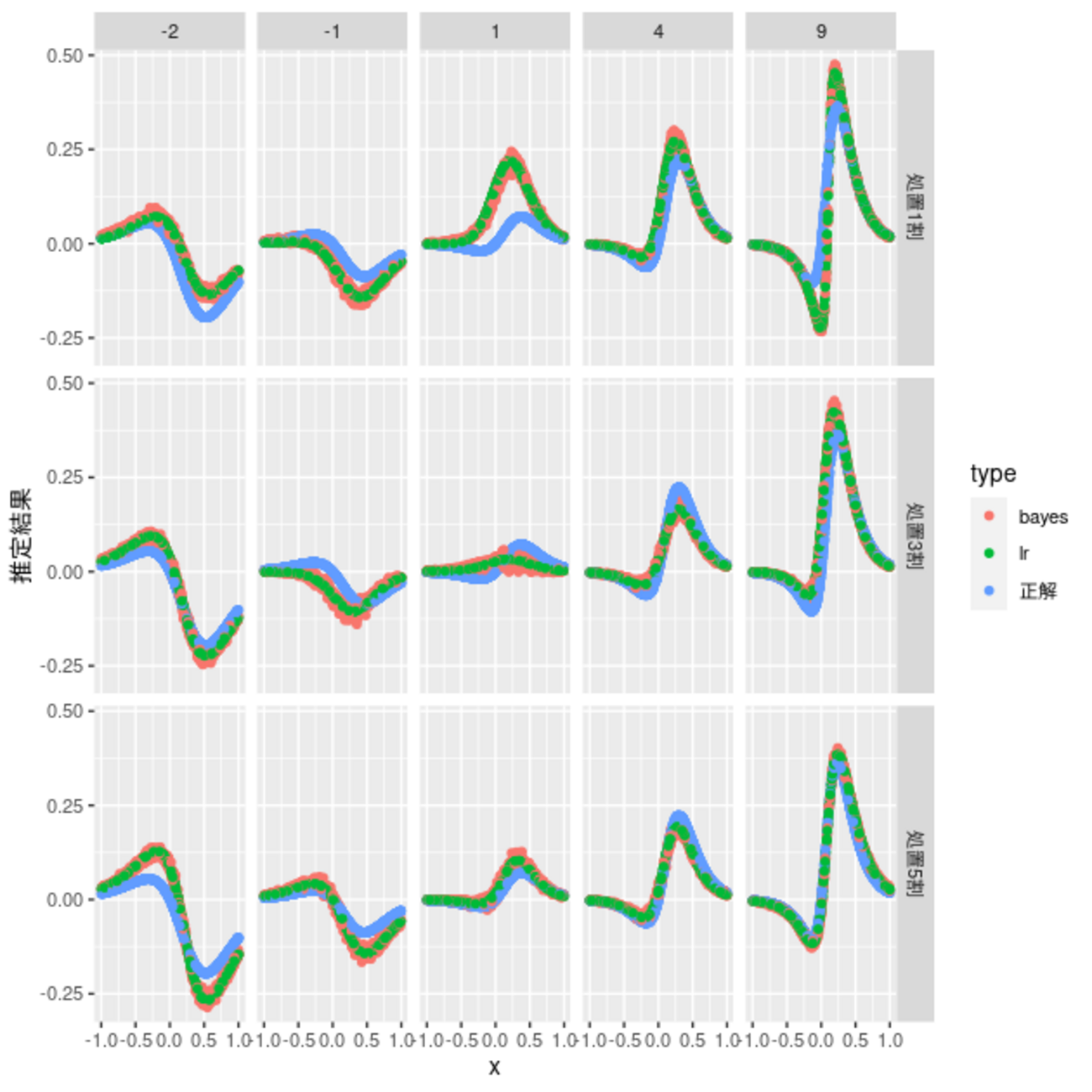
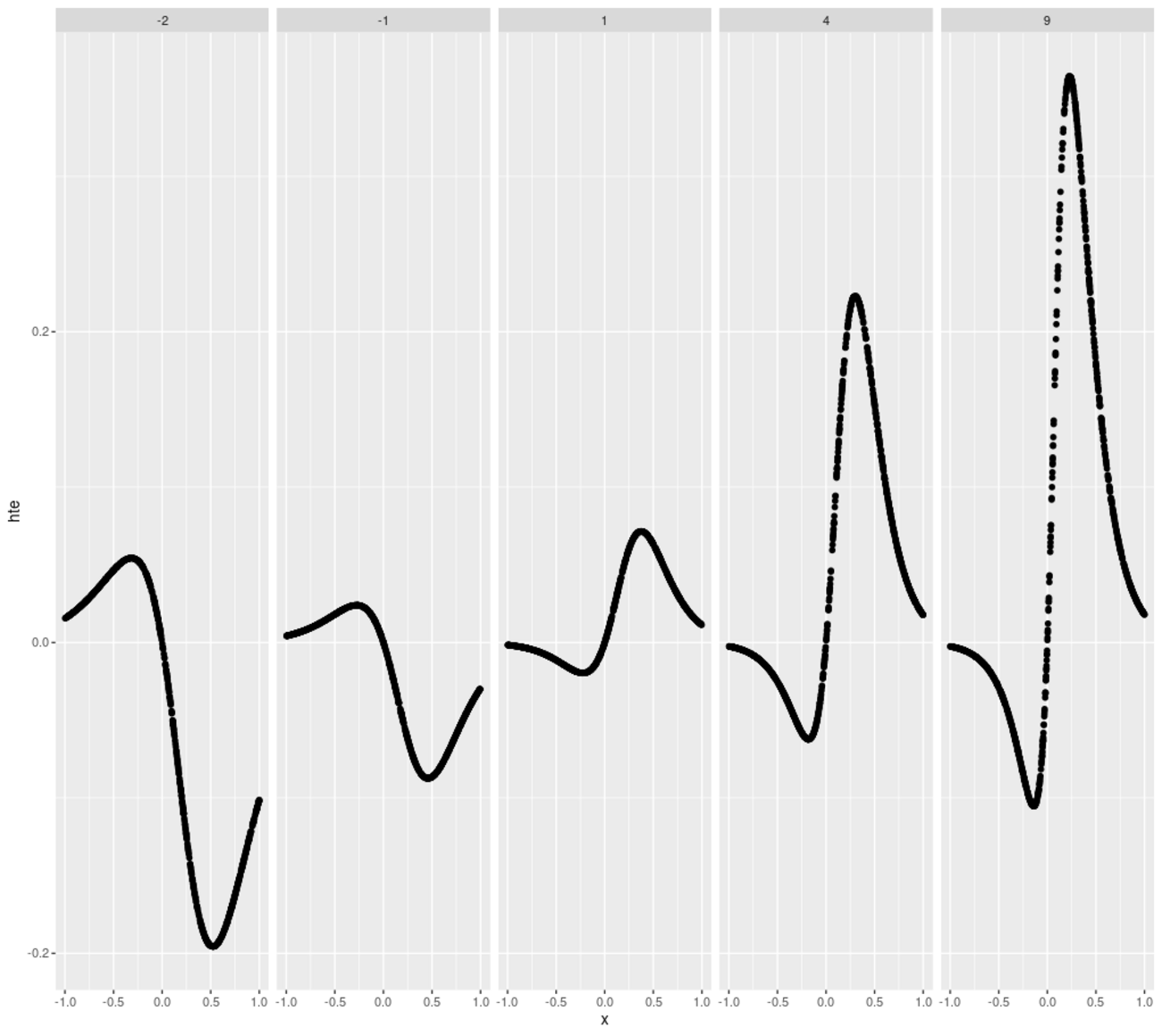
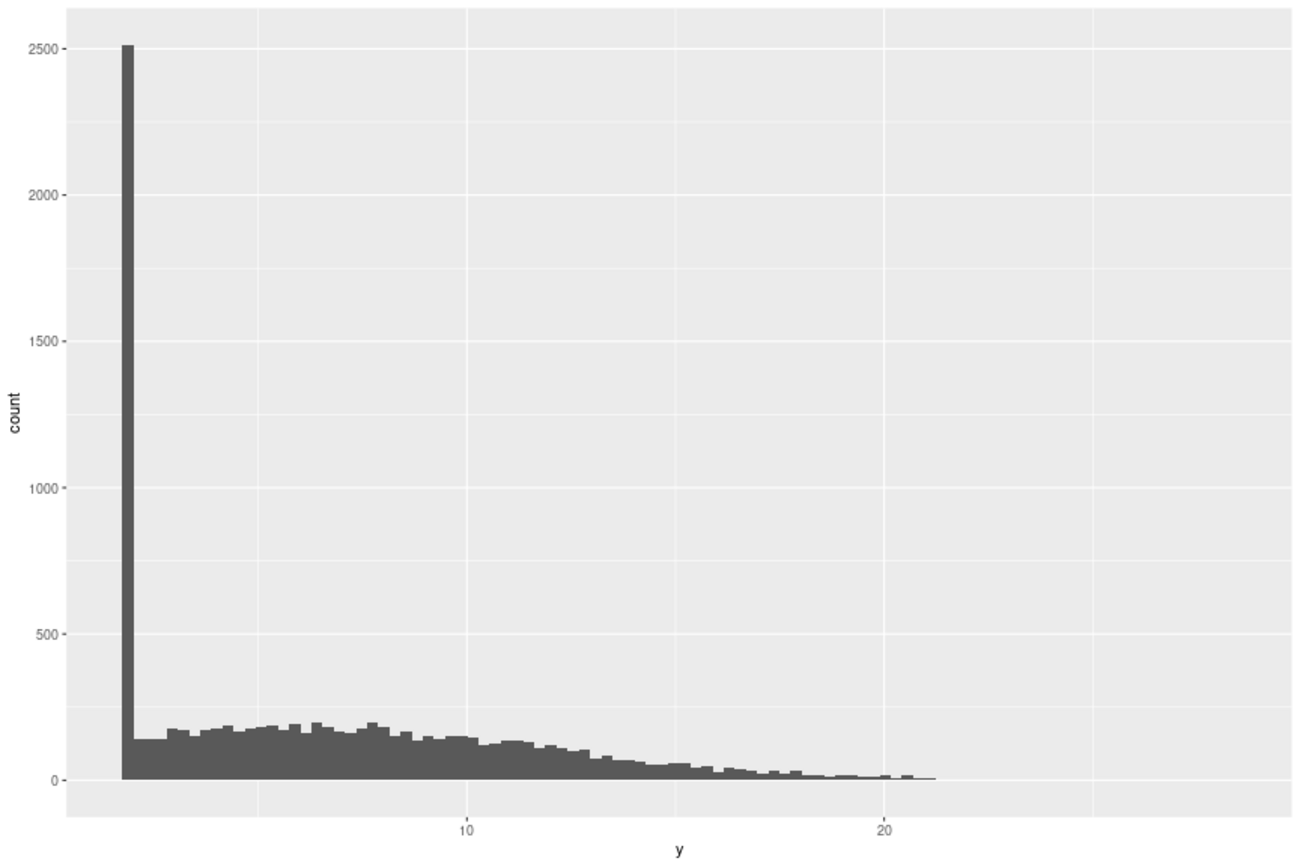
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回も前回に引き続きアウトカムが2値のHeterogeneous Treatment Effects(HTE)に関する簡単な検証実験を扱います。ベイズを利用してT-Learnerに事前知識を組み込むことで推定が改善されるのかを調べたものです。コードはRとStanです。前回の記事は以下。 analytics.livesense.co.jp データ データは前回の記事で利...| LIVESENSE Data Analytics Blog
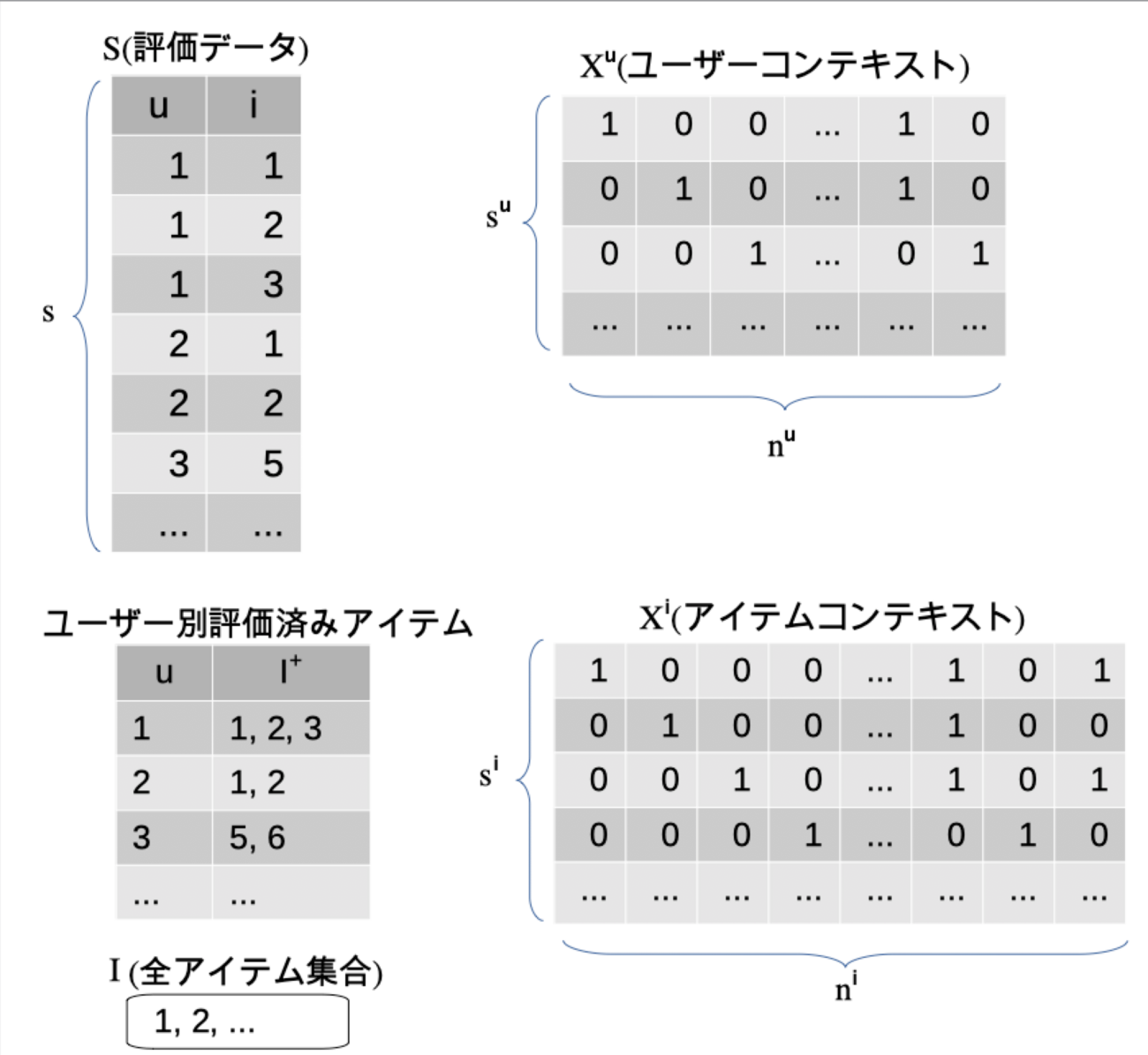
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回はStanを使ったレコメンデーション用FM(Factorization Machines)を扱います。 FMはシンプルなモデルなのでStanで簡単に実装することができます。しかし、レコメンデーションで使う場合はスパースデータに対応したものにしないと無駄な計算が多く計算に非常に時間がかかってしまったりメモリを大...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は小ネタで打ち切り・切断データの回帰モデルを扱います。弊社で扱っているデータの中には打ち切りデータになっているものがあり、そのようなデータから階層ベイズモデルを作ることがあります。打ち切り・切断データの扱い方が分かれば階層ベイズに拡張するのは容易なので、今回は...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は転職ドラフトの年収非公開施策のデータ分析の一つとして行った、施策が提示年収に与えた平均処置効果推定の紹介です。今回の記事は過去に行った分析結果を因果推論手法で再確認するのが主な目的です。 年収非公開施策ではA/Bテストを行っていないため、年収非公開施策回のみに参加...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は平均処置効果の推定方法について紹介します。より具体的にはマッチングや重み付けといった共変量のバランシングを利用してバイアスの小さい推定をする方法を使い、複数得られた推定結果を絞り込んで意思決定に使える結論を得るまでの流れを扱います。サンプルデータを使って実際...| LIVESENSE Data Analytics Blog
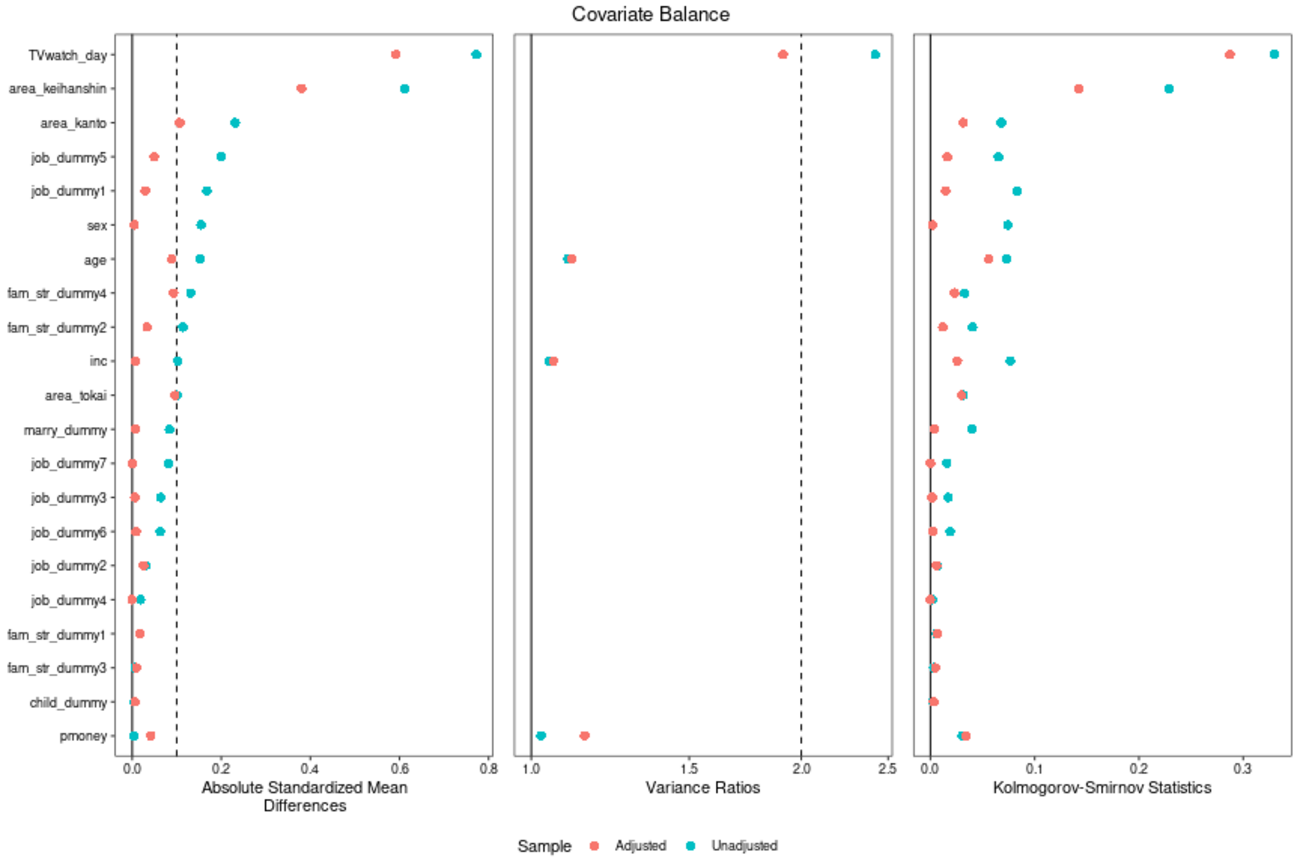
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回はCovariate Balancing Propensity Score(CBPS)の紹介をします。また、Rのmomentfitパッケージを利用したCBPSの実装も扱います。 CBPSは共変量のバランスも考慮して傾向スコアを算出する方法です。以前の記事で紹介したGeneralized Method of Moments(GMM、一般化モーメント法)を利用しているところも特徴の一つにな...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回はRのmomentfitパッケージを使ってGeneralized Method of Moments(GMM、一般化モーメント法)を実行する方法について紹介します。 GMMはパラメータ推定法の一つで、主に計量経済学で使われています。実務でGMMを直接使うケースはまれだと思いますが、因果推論に関わる機械学習で使われることがあるた...| LIVESENSE Data Analytics Blog
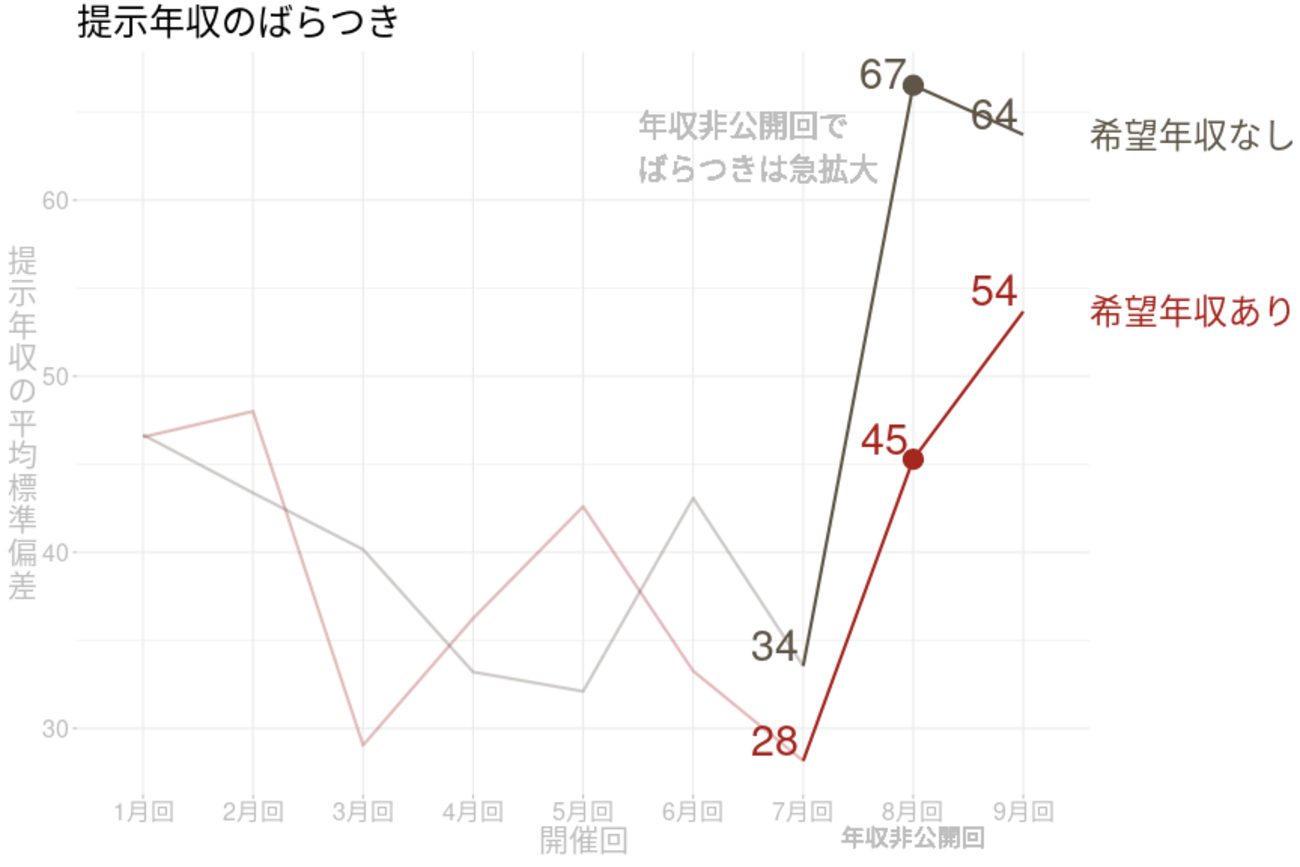
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は以前の記事の続きで転職ドラフトの年収非公開施策のデータ分析について紹介します。階層ベイズを利用した推定を行います。 以前の記事では提示年収のばらつきをユーザー別標準偏差の平均で計算していました。指名数が多いユーザーばかりであればこの方法で十分なのですが、実際に...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は2020年8月に開催された転職ドラフトの年収非公開施策の分析結果について紹介します。今回は一般向けの内容で、分析手法は集計のみを使いデータ分析の専門用語はほとんど使わずに説明しています。データサイエンティスト向けの、より詳細な分析については後日扱う予定です。 転職ド...| LIVESENSE Data Analytics Blog
前回に続きコンテキストを扱えるFactorization Machines(FM)をモデルとした、Bayesian Personalized Ranking(BPR)(以下ではBPR-FMと略)を紹介します。今回はBPR-FMのモデルパラメータ推定の実装の話をします。実装にはJuliaを使います。モデルやアルゴリズムの詳細については下記の記事をご参照ください。| LIVESENSE Data Analytics Blog
今回から3回にわたって暗黙的評価データを使ったコンテキスト対応レコメンデーションの紹介をしようと思います。具体的には、コンテキストを扱えるFactorization Machines(FM)をモデルとした、Bayesian Personalized Ranking(BPR)を紹介します。今回はアルゴリズムとモデル、次回は実装、最後は実務での応用の話をします。| LIVESENSE Data Analytics Blog
こんにちは、リブセンスで分析や機械学習関係の仕事をしている北原です。 今回は求職者に向けたリブセンスの機械学習業務の紹介です。 求職者に業務内容を理解してもらうのが目的の記事になっています。 各事業部で進められている機械学習プロジェクトなどもあるのですが、本記事ではテクノロジカルマーケティング部という横断組織での機械学習専門職の業務...| LIVESENSE Data Analytics Blog
テクノロジカルマーケティング部 データマーケティンググループにてUXリサーチャーをしている佐々木と申します。普段は、UXデザイン(以下、UXDと略記)に関するプロジェクトを事業部横断で支援する業務についております。 これまで前編として、"UXデザインが総論賛成、各論疑問になる理由"と"プロジェクト設計で意識したい3つの条件"の1つ目を前編「サービス...| LIVESENSE Data Analytics Blog
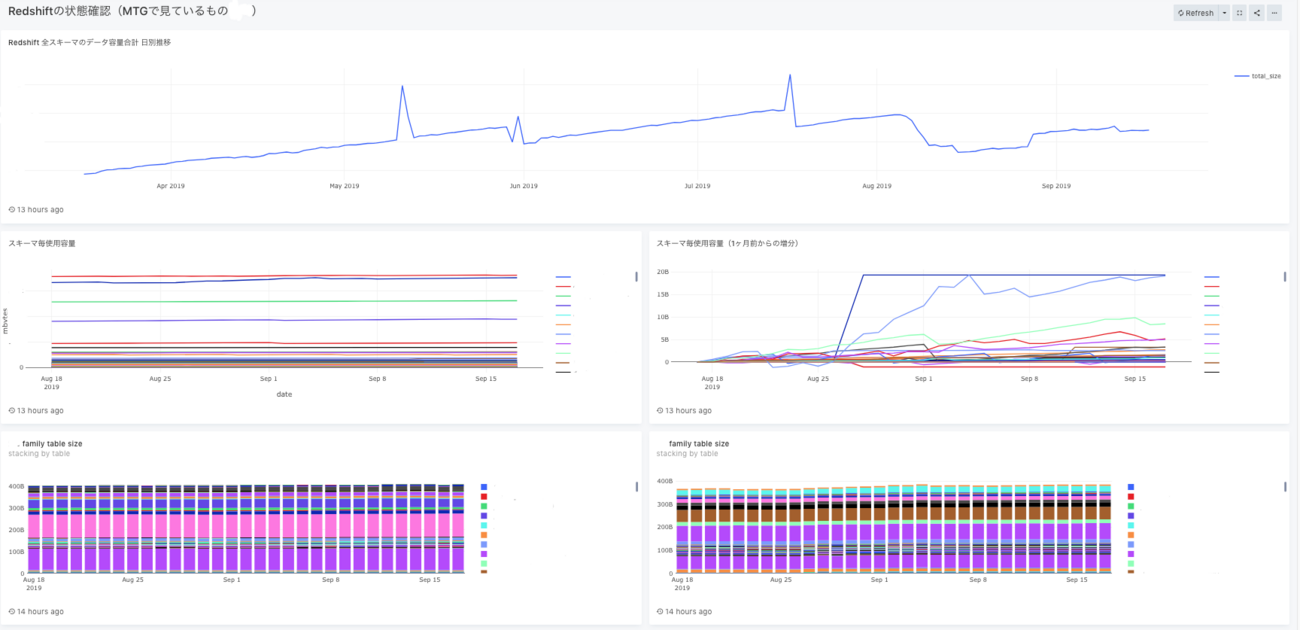
データプラットフォームグループの松原です。 弊社各サービスのデータ分析基盤であるLivesense Analytics(以降LA)の開発、運用を行っています。 LAではデータウェアハウスとしてRedshiftを運用しており、社内から比較的自由に利用できる様にしています。 Redshiftには、分析者がアドホックに実行したり、BIツールなどからKPIを取得するために実行されるインタラクティブな...| LIVESENSE Data Analytics Blog
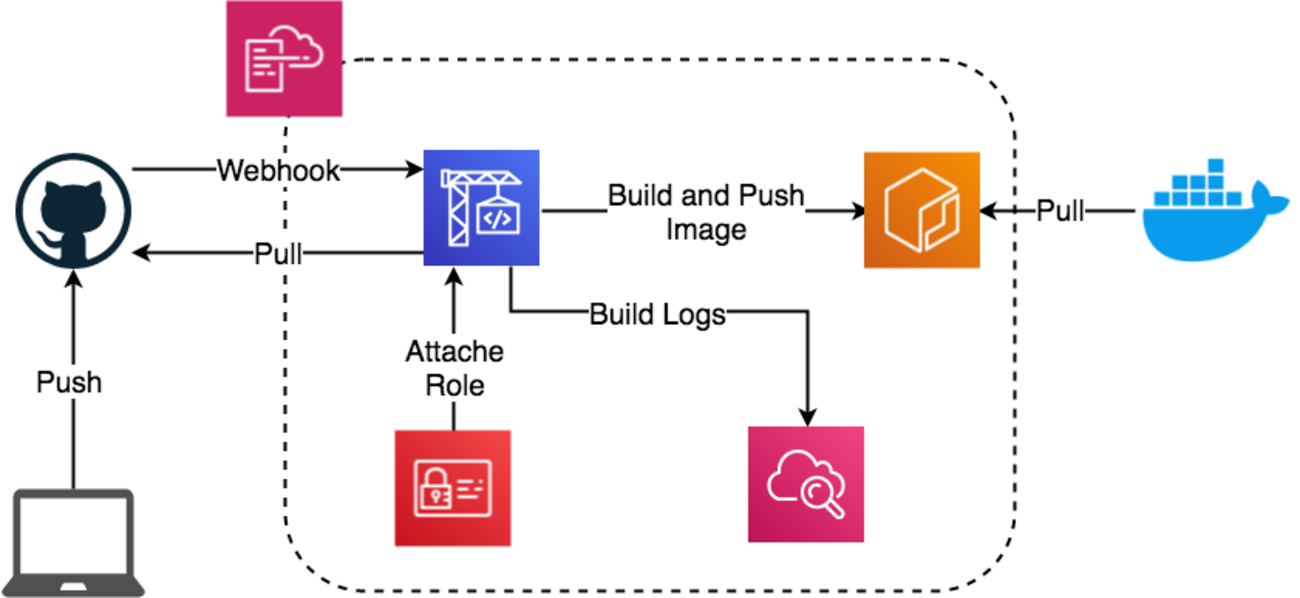
テクノロジカルマーケティング部の橋本です。 肩書的には分析基盤開発・保守を担当するエンジニアですが、近頃は基盤開発に限らず、データアナリストが推進するデータ活用施策をエンジニアの立場でサポートしており、施策実行のために必要となる周辺システムの開発も行っています。仕事とあらば、できる事はなんでもやります。 そんな中で、最近バッチ処理構...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回は平均処置効果の推定方法について紹介します。より具体的にはマッチングや重み付けといった共変量のバランシングを利用してバイアスの小さい推定をする方法を使い、複数得られた推定結果を絞り込んで意思決定に使える結論を得るまでの流れを扱います。サンプルデータを使って実際...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスで統計や機械学習関係の仕事をしている北原です。今回はレコメンデーションで使う評価推定値計算の効率化に関する小ネタです。機械学習を実務で使うときのちょっとした工夫に関するお話です。実装にはJuliaを使います。 FM(Factorization Machines)をレコメンデーションで使う場合、各ユーザーに対してレコメンド可能なアイテムの評価推定値計算...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスで統計や機械学習関係の仕事をしている北原です。今回はレコメンデーションにも使えるFactorization Machines(FM)の効率的な学習アルゴリズムの紹介です。実装にはJuliaを使います。 実務で必要な要件を満たす機械学習ライブラリがなくて、機械学習モデルをカスタマイズすることってありますよね。最近はTensorFlowのような機械学習フレームワーク...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスで機械学習関係の仕事をしている北原です。 弊社の転職ナビアプリには求人をレコメンドする機能が実装されていて、求人の好みを回答すると各ユーザーに合った求人がレコメンドされるようになっています。このサービスではいくつかのレコメンドアルゴリズムが使われているのですが、その中にBPMF(Bayesian Probabilistic Matrix Factorization)というア...| LIVESENSE Data Analytics Blog
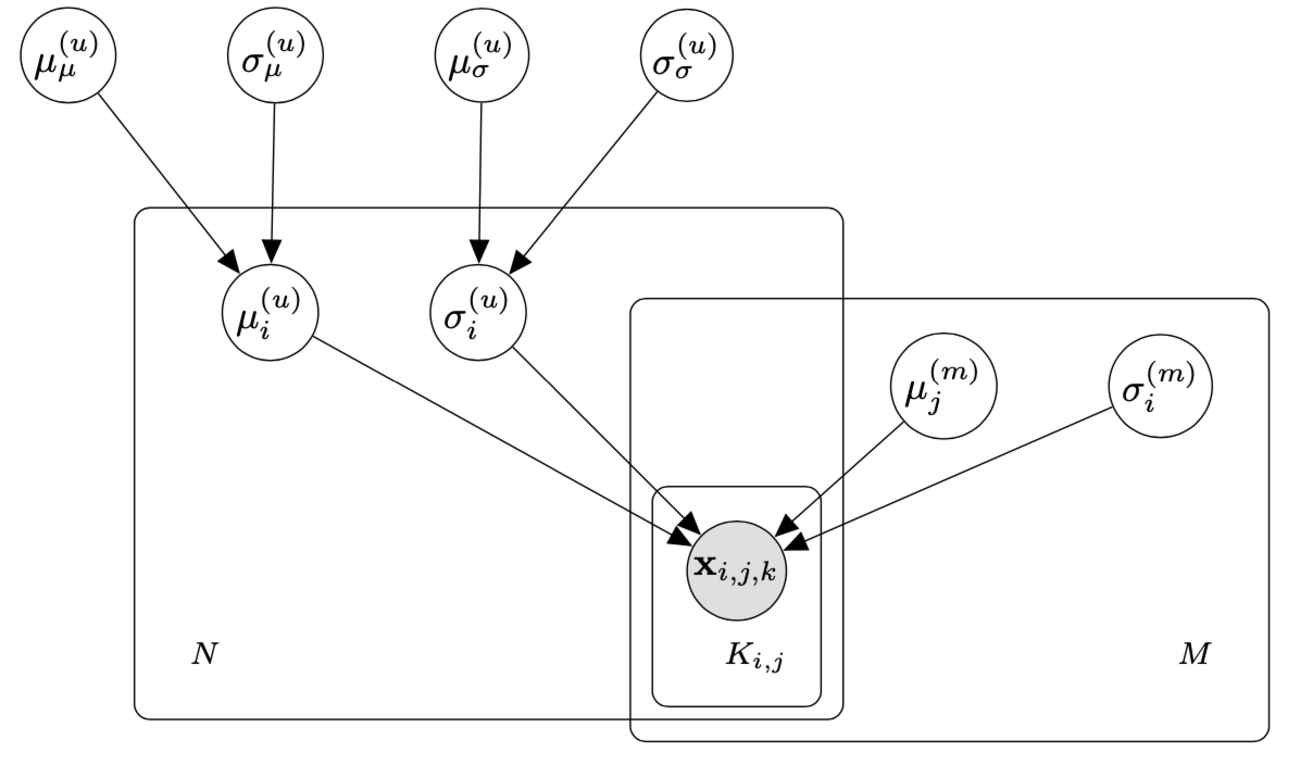
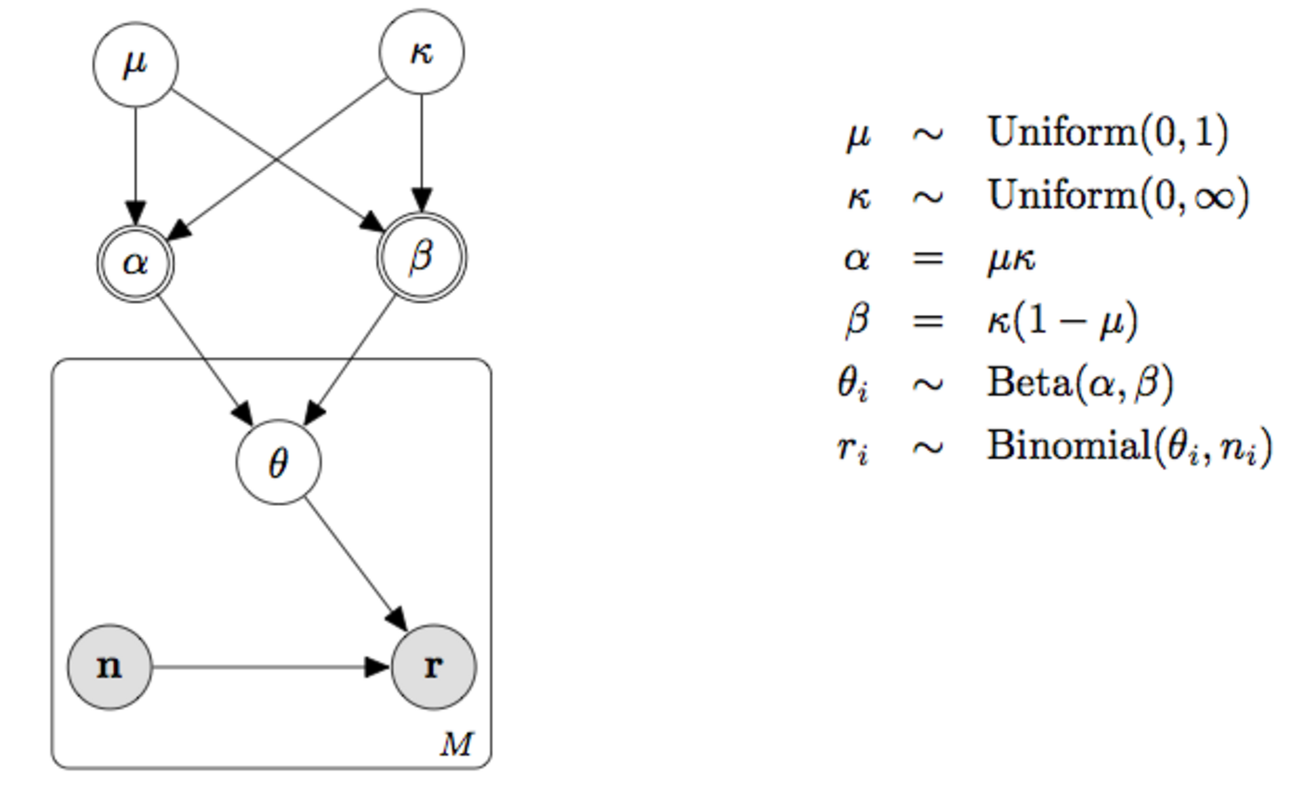
こんにちは、リブセンスで統計や機械学習関係の仕事をしている北原です。今回は階層ベイズを使った小技の紹介です。推定にはStanを使います。Webサービスに限らないかもしれませんが、CVRやCTRなど比率データを扱うことって多いですよね。弊社の求人サービスは成果報酬型であるため、各求人の採用率などを知りたいこともよくあります。しかし、求人別だとバイト...| LIVESENSE Data Analytics Blog